 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL1-regularized Reconstruction Error as Alpha Matte
Paper and Code
Feb 09, 2017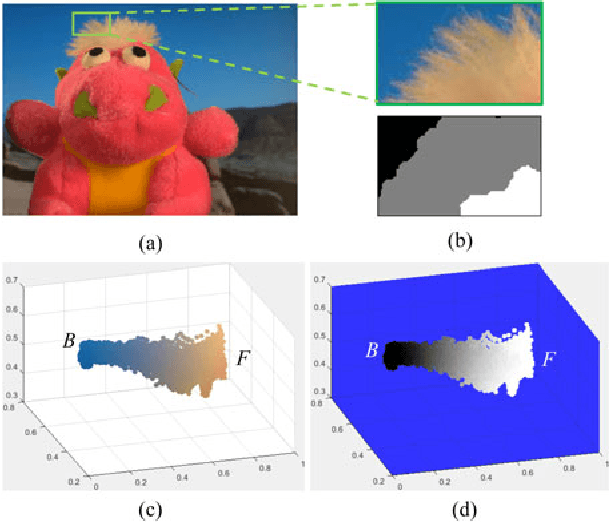


Sampling-based alpha matting methods have traditionally followed the compositing equation to estimate the alpha value at a pixel from a pair of foreground (F) and background (B) samples. The (F,B) pair that produces the least reconstruction error is selected, followed by alpha estimation. The significance of that residual error has been left unexamined. In this letter, we propose a video matting algorithm that uses L1-regularized reconstruction error of F and B samples as a measure of the alpha matte. A multi-frame non-local means framework using coherency sensitive hashing is utilized to ensure temporal coherency in the video mattes. Qualitative and quantitative evaluations on a dataset exclusively for video matting demonstrate the effectiveness of the proposed matting algorithm.