 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Task Relations for Few-shot Text Classification via Self-Supervised Hierarchical Task Clustering
Nov 16, 2022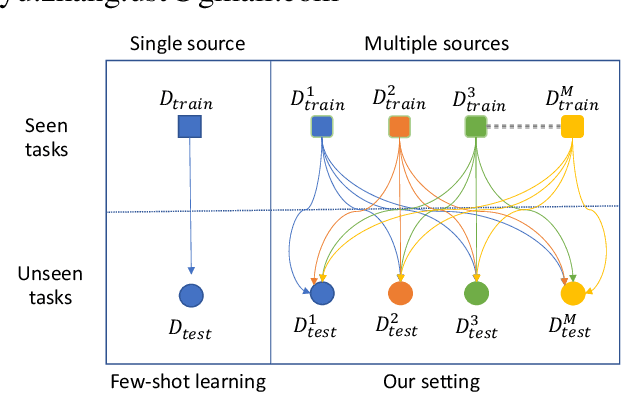
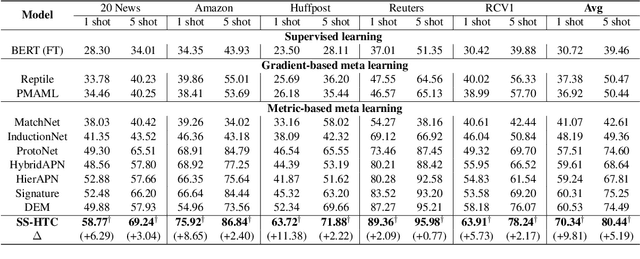
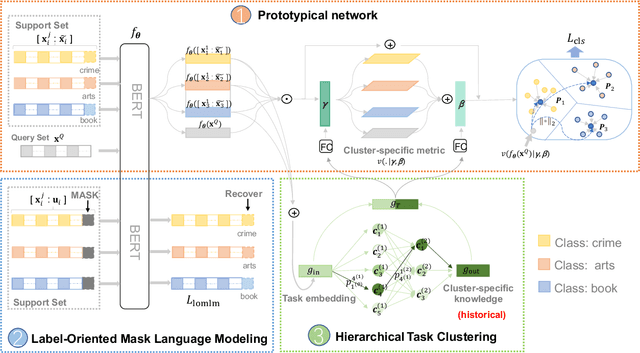
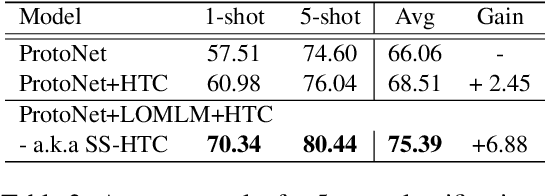
Few-Shot Text Classification (FSTC) imitates humans to learn a new text classifier efficiently with only few examples, by leveraging prior knowledge from historical tasks. However, most prior works assume that all the tasks are sampled from a single data source, which cannot adapt to real-world scenarios where tasks are heterogeneous and lie in different distributions. As such, existing methods may suffer from their globally knowledge-shared mechanisms to handle the task heterogeneity. On the other hand, inherent task relation are not explicitly captured, making task knowledge unorganized and hard to transfer to new tasks. Thus, we explore a new FSTC setting where tasks can come from a diverse range of data sources. To address the task heterogeneity, we propose a self-supervised hierarchical task clustering (SS-HTC) method. SS-HTC not only customizes cluster-specific knowledge by dynamically organizing heterogeneous tasks into different clusters in hierarchical levels but also disentangles underlying relations between tasks to improve the interpretability. Extensive experiments on five public FSTC benchmark datasets demonstrate the effectiveness of SS-HTC.
Eliciting Transferability in Multi-task Learning with Task-level Mixture-of-Experts
May 25, 2022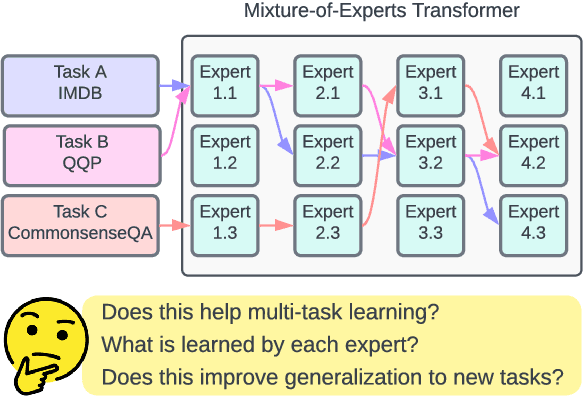
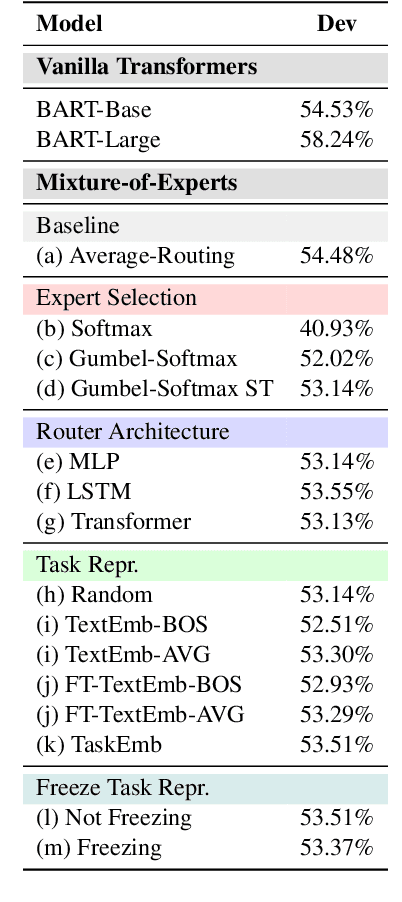
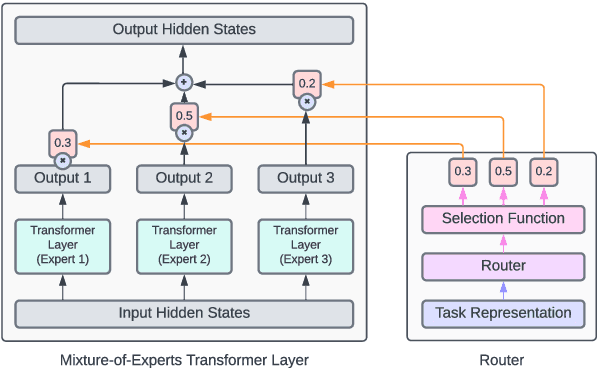
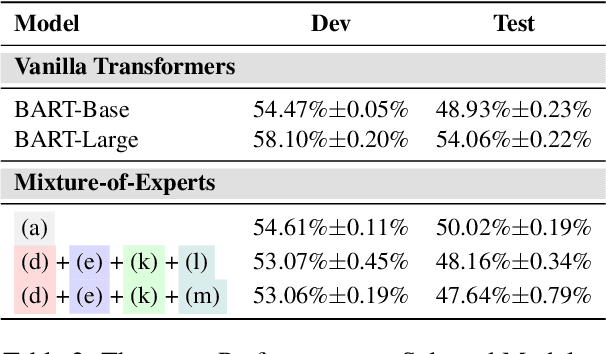
Recent work suggests that transformer models are capable of multi-task learning on diverse NLP tasks. However, the potential of these models may be limited as they use the same set of parameters for all tasks. In contrast, humans tackle tasks in a more flexible way, by making proper presumptions on what skills and knowledge are relevant and executing only the necessary computations. Inspired by this, we propose to use task-level mixture-of-expert models, which has a collection of transformer layers (i.e., experts) and a router component to choose among these experts dynamically and flexibly. We show that the learned routing decisions and experts partially rediscover human categorization of NLP tasks -- certain experts are strongly associated with extractive tasks, some with classification tasks, and some with tasks requiring world knowledge.