 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSocNav: Social Navigation by Imitating Human Behaviors
Jul 19, 2021
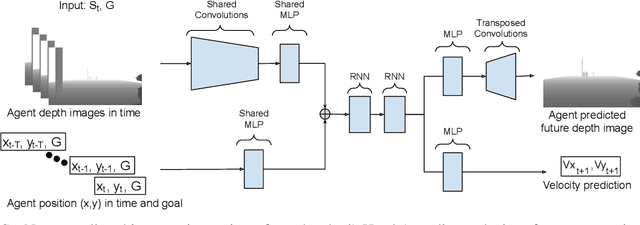
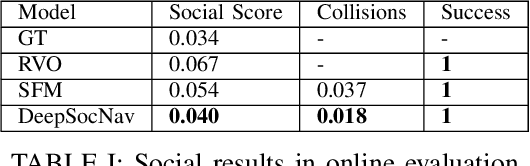
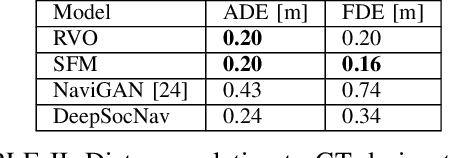
Current datasets to train social behaviors are usually borrowed from surveillance applications that capture visual data from a bird's-eye perspective. This leaves aside precious relationships and visual cues that could be captured through a first-person view of a scene. In this work, we propose a strategy to exploit the power of current game engines, such as Unity, to transform pre-existing bird's-eye view datasets into a first-person view, in particular, a depth view. Using this strategy, we are able to generate large volumes of synthetic data that can be used to pre-train a social navigation model. To test our ideas, we present DeepSocNav, a deep learning based model that takes advantage of the proposed approach to generate synthetic data. Furthermore, DeepSocNav includes a self-supervised strategy that is included as an auxiliary task. This consists of predicting the next depth frame that the agent will face. Our experiments show the benefits of the proposed model that is able to outperform relevant baselines in terms of social navigation scores.
A Behavioral Approach to Visual Navigation with Graph Localization Networks
Mar 01, 2019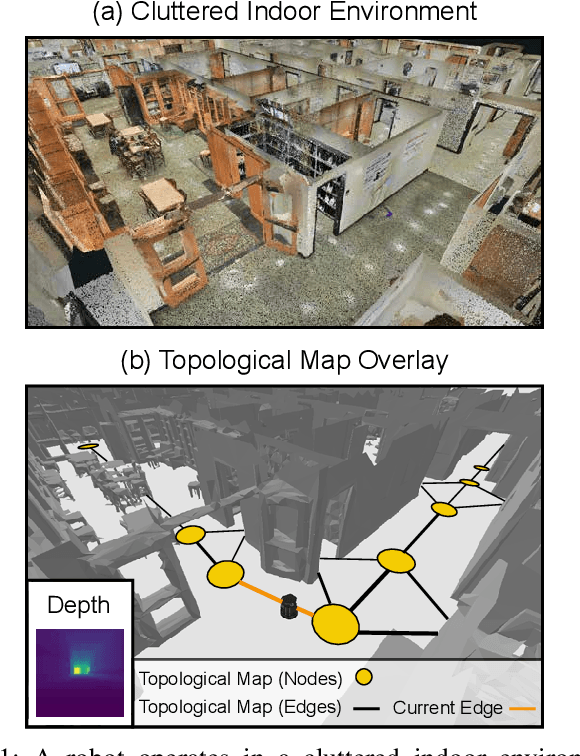
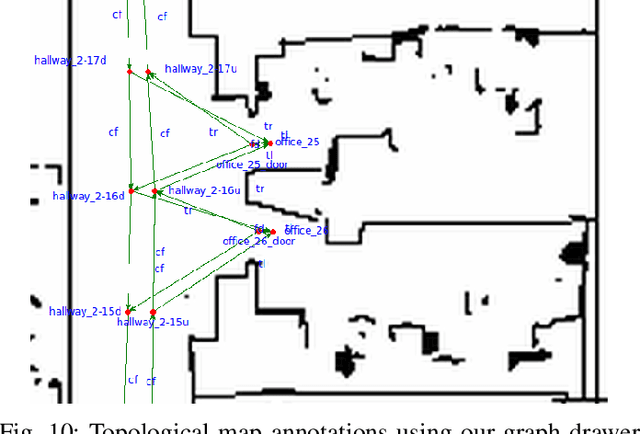


Inspired by research in psychology, we introduce a behavioral approach for visual navigation using topological maps. Our goal is to enable a robot to navigate from one location to another, relying only on its visual input and the topological map of the environment. We propose using graph neural networks for localizing the agent in the map, and decompose the action space into primitive behaviors implemented as convolutional or recurrent neural networks. Using the Gibson simulator, we verify that our approach outperforms relevant baselines and is able to navigate in both seen and unseen environments.