 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAATT Nav: a Socially Aware Autonomous Transparent Transportation Navigation Framework for Wheelchairs
Mar 14, 2026While powered wheelchairs reduce physical fatigue as opposed to manual wheelchairs for individuals with mobility impairment, they demand high cognitive workload due to information processing, decision making and motor coordination. Current autonomous systems lack social awareness in navigation and transparency in decision-making, leading to decreased perceived safety and trust from the user and others in context. This work proposes Socially Aware Autonomous Transparent Transportation (SAATT) Navigation framework for wheelchairs as a potential solution. By implementing a Large Language Model (LLM) informed of user intent and capable of predicting other peoples' intent as a decision-maker for its local controller, it is able to detect and navigate social situations, such as passing pedestrians or a pair conversing. Furthermore, the LLM textually communicates its reasoning at each waypoint for transparency. In this experiment, it is compared against a standard global planner, a representative competing social navigation model, and an Ablation study in three simulated environments varied by social levels in eight metrics categorized under Safety, Social Compliance, Efficiency, and Comfort. Overall, SAATT Nav outperforms in most social situations and equivalently or only slightly worse in the remaining metrics, demonstrating the potential of a socially aware and transparent autonomous navigation system to assist wheelchair users.
Spiking Neural Networks for Early Prediction in Human Robot Collaboration
Jul 29, 2018

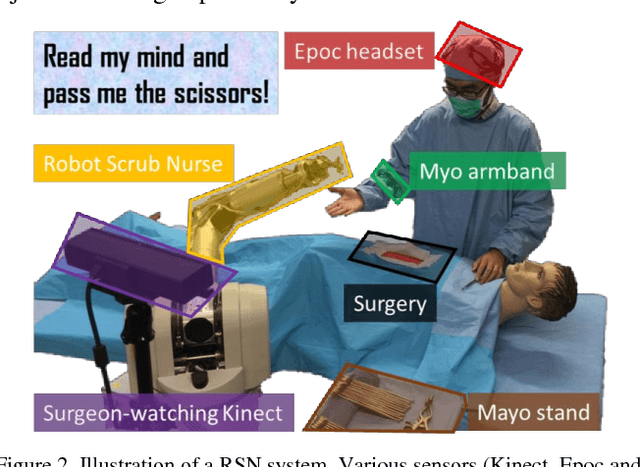

This paper introduces the Turn-Taking Spiking Neural Network (TTSNet), which is a cognitive model to perform early turn-taking prediction about human or agent's intentions. The TTSNet framework relies on implicit and explicit multimodal communication cues (physical, neurological and physiological) to be able to predict when the turn-taking event will occur in a robust and unambiguous fashion. To test the theories proposed, the TTSNet framework was implemented on an assistant robotic nurse, which predicts surgeon's turn-taking intentions and delivers surgical instruments accordingly. Experiments were conducted to evaluate TTSNet's performance in early turn-taking prediction. It was found to reach a F1 score of 0.683 given 10% of completed action, and a F1 score of 0.852 at 50% and 0.894 at 100% of the completed action. This performance outperformed multiple state-of-the-art algorithms, and surpassed human performance when limited partial observation is given (< 40%). Such early turn-taking prediction capability would allow robots to perform collaborative actions proactively, in order to facilitate collaboration and increase team efficiency.
Early Turn-taking Prediction with Spiking Neural Networks for Human Robot Collaboration
Sep 26, 2017
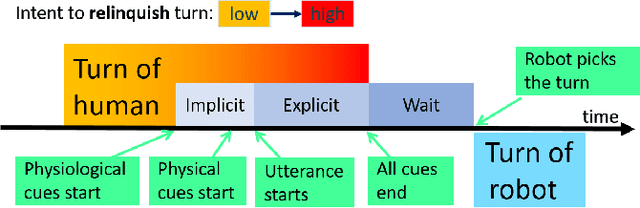


Turn-taking is essential to the structure of human teamwork. Humans are typically aware of team members' intention to keep or relinquish their turn before a turn switch, where the responsibility of working on a shared task is shifted. Future co-robots are also expected to provide such competence. To that end, this paper proposes the Cognitive Turn-taking Model (CTTM), which leverages cognitive models (i.e., Spiking Neural Network) to achieve early turn-taking prediction. The CTTM framework can process multimodal human communication cues (both implicit and explicit) and predict human turn-taking intentions in an early stage. The proposed framework is tested on a simulated surgical procedure, where a robotic scrub nurse predicts the surgeon's turn-taking intention. It was found that the proposed CTTM framework outperforms the state-of-the-art turn-taking prediction algorithms by a large margin. It also outperforms humans when presented with partial observations of communication cues (i.e., less than 40% of full actions). This early prediction capability enables robots to initiate turn-taking actions at an early stage, which facilitates collaboration and increases overall efficiency.
Early Prediction for Physical Human Robot Collaboration in the Operating Room
Sep 26, 2017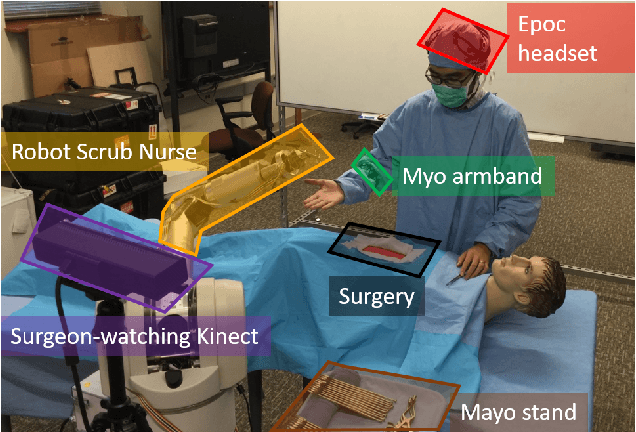
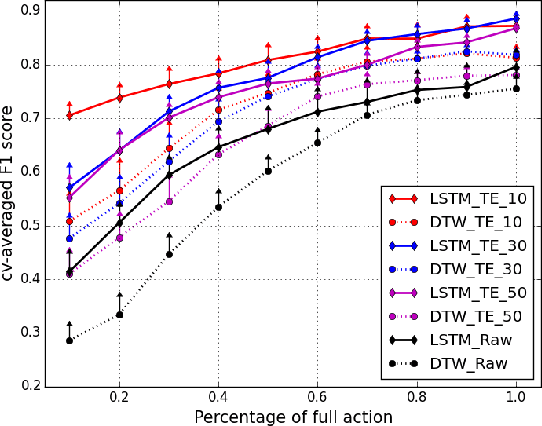
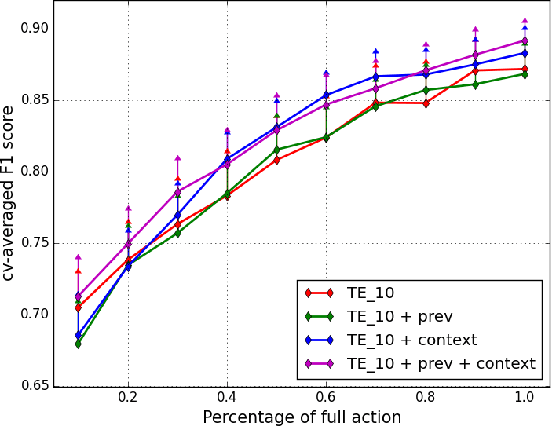
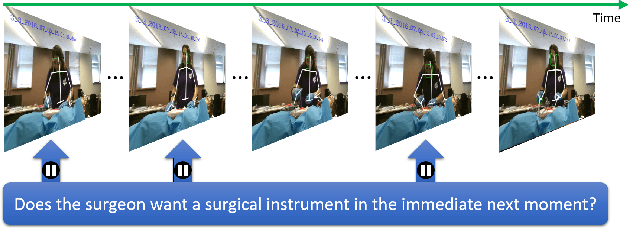
To enable a natural and fluent human robot collaboration flow, it is critical for a robot to comprehend their human peers' on-going actions, predict their behaviors in the near future, and plan its actions correspondingly. Specifically, the capability of making early predictions is important, so that the robot can foresee the precise timing of a turn-taking event and start motion planning and execution early enough to smooth the turn-taking transition. Such proactive behavior would reduce human's waiting time, increase efficiency and enhance naturalness in collaborative task. To that end, this paper presents the design and implementation of an early turn-taking prediction algorithm, catered for physical human robot collaboration scenarios. Specifically, a Robotic Scrub Nurse (RSN) system which can comprehend surgeon's multimodal communication cues and perform turn-taking prediction is presented. The developed algorithm was tested on a collected data set of simulated surgical procedures in a surgeon-nurse tandem. The proposed turn-taking prediction algorithm is found to be significantly superior to its algorithmic counterparts, and is more accurate than human baseline when little partial input is given (less than 30% of full action). After observing more information, the algorithm can achieve comparable performances as humans with a F1 score of 0.90.
Communication Modalities for Supervised Teleoperation in Highly Dexterous Tasks - Does one size fit all?
Apr 17, 2017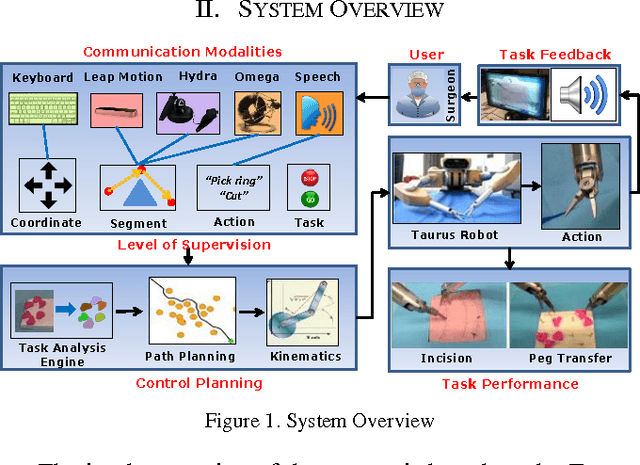
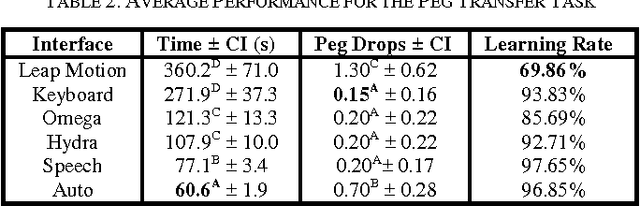
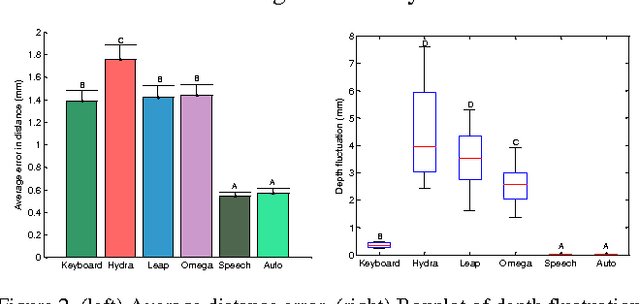
This study tries to explain the connection between communication modalities and levels of supervision in teleoperation during a dexterous task, like surgery. This concept is applied to two surgical related tasks: incision and peg transfer. It was found that as the complexity of the task escalates, the combination linking human supervision with a more expressive modality shows better performance than other combinations of modalities and control. More specifically, in the peg transfer task, the combination of speech modality and action level supervision achieves shorter task completion time (77.1 +- 3.4 s) with fewer mistakes (0.20 +- 0.17 pegs dropped).