 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Interpretability of Deep Learning Segmentation Through Shapley-Derived Agreement and Uncertainty Metrics
Dec 08, 2025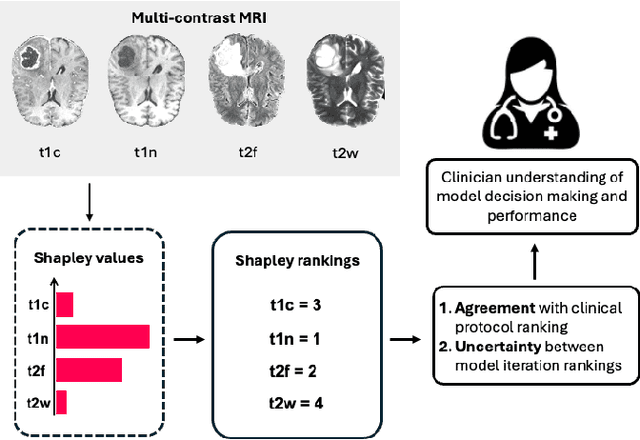
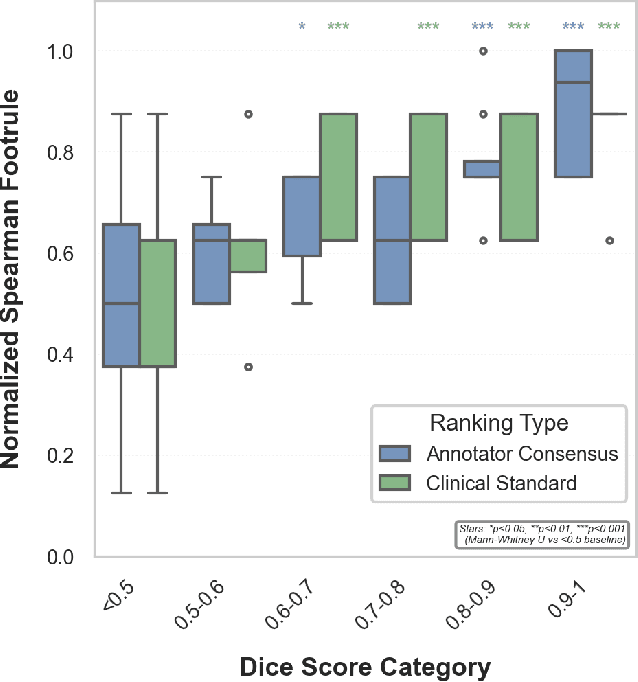
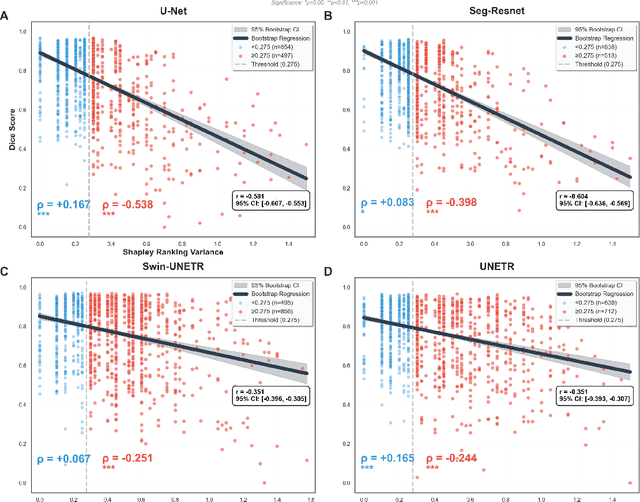
Segmentation is the identification of anatomical regions of interest, such as organs, tissue, and lesions, serving as a fundamental task in computer-aided diagnosis in medical imaging. Although deep learning models have achieved remarkable performance in medical image segmentation, the need for explainability remains critical for ensuring their acceptance and integration in clinical practice, despite the growing research attention in this area. Our approach explored the use of contrast-level Shapley values, a systematic perturbation of model inputs to assess feature importance. While other studies have investigated gradient-based techniques through identifying influential regions in imaging inputs, Shapley values offer a broader, clinically aligned approach, explaining how model performance is fairly attributed to certain imaging contrasts over others. Using the BraTS 2024 dataset, we generated rankings for Shapley values for four MRI contrasts across four model architectures. Two metrics were proposed from the Shapley ranking: agreement between model and ``clinician" imaging ranking, and uncertainty quantified through Shapley ranking variance across cross-validation folds. Higher-performing cases (Dice \textgreater0.6) showed significantly greater agreement with clinical rankings. Increased Shapley ranking variance correlated with decreased performance (U-Net: $r=-0.581$). These metrics provide clinically interpretable proxies for model reliability, helping clinicians better understand state-of-the-art segmentation models.
Here Comes the Explanation: A Shapley Perspective on Multi-contrast Medical Image Segmentation
Apr 06, 2025



Deep learning has been successfully applied to medical image segmentation, enabling accurate identification of regions of interest such as organs and lesions. This approach works effectively across diverse datasets, including those with single-image contrast, multi-contrast, and multimodal imaging data. To improve human understanding of these black-box models, there is a growing need for Explainable AI (XAI) techniques for model transparency and accountability. Previous research has primarily focused on post hoc pixel-level explanations, using methods gradient-based and perturbation-based apporaches. These methods rely on gradients or perturbations to explain model predictions. However, these pixel-level explanations often struggle with the complexity inherent in multi-contrast magnetic resonance imaging (MRI) segmentation tasks, and the sparsely distributed explanations have limited clinical relevance. In this study, we propose using contrast-level Shapley values to explain state-of-the-art models trained on standard metrics used in brain tumor segmentation. Our results demonstrate that Shapley analysis provides valuable insights into different models' behavior used for tumor segmentation. We demonstrated a bias for U-Net towards over-weighing T1-contrast and FLAIR, while Swin-UNETR provided a cross-contrast understanding with balanced Shapley distribution.
Re-DiffiNet: Modeling discrepancies loss in tumor segmentation using diffusion models
Feb 15, 2024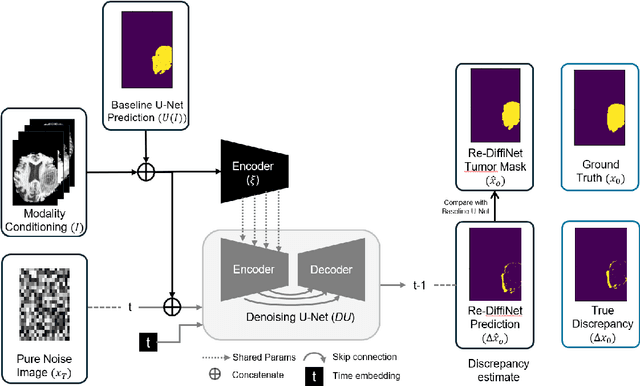
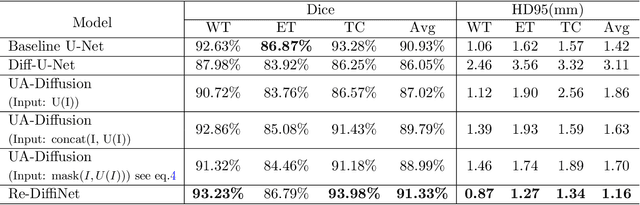
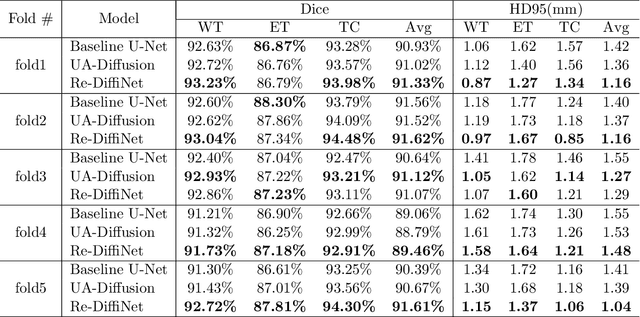
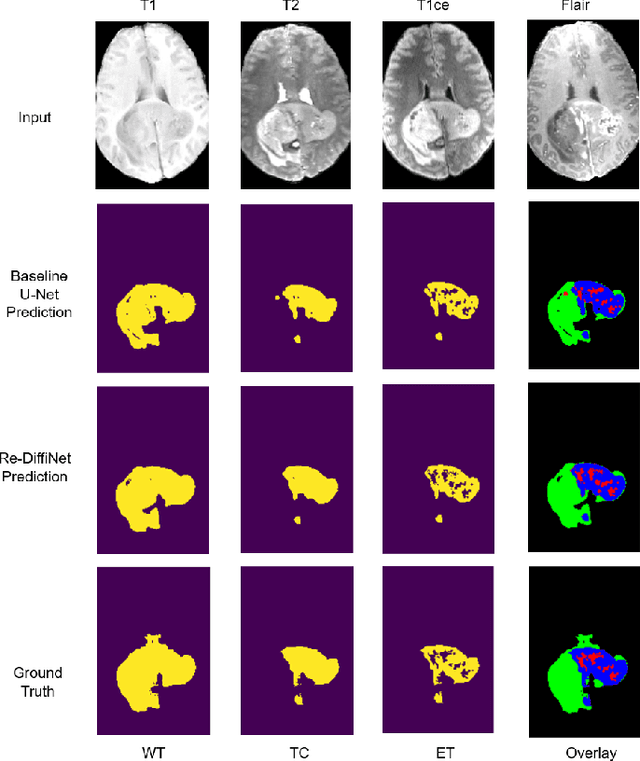
Identification of tumor margins is essential for surgical decision-making for glioblastoma patients and provides reliable assistance for neurosurgeons. Despite improvements in deep learning architectures for tumor segmentation over the years, creating a fully autonomous system suitable for clinical floors remains a formidable challenge because the model predictions have not yet reached the desired level of accuracy and generalizability for clinical applications. Generative modeling techniques have seen significant improvements in recent times. Specifically, Generative Adversarial Networks (GANs) and Denoising-diffusion-based models (DDPMs) have been used to generate higher-quality images with fewer artifacts and finer attributes. In this work, we introduce a framework called Re-Diffinet for modeling the discrepancy between the outputs of a segmentation model like U-Net and the ground truth, using DDPMs. By explicitly modeling the discrepancy, the results show an average improvement of 0.55\% in the Dice score and 16.28\% in HD95 from cross-validation over 5-folds, compared to the state-of-the-art U-Net segmentation model.