 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated LLM-Based Intrusion Detection with Secure Slicing xApp for Securing O-RAN-Enabled Wireless Network Deployments
Apr 01, 2025



The Open Radio Access Network (O-RAN) architecture is reshaping telecommunications by promoting openness, flexibility, and intelligent closed-loop optimization. By decoupling hardware and software and enabling multi-vendor deployments, O-RAN reduces costs, enhances performance, and allows rapid adaptation to new technologies. A key innovation is intelligent network slicing, which partitions networks into isolated slices tailored for specific use cases or quality of service requirements. The RAN Intelligent Controller further optimizes resource allocation, ensuring efficient utilization and improved service quality for user equipment (UEs). However, the modular and dynamic nature of O-RAN expands the threat surface, necessitating advanced security measures to maintain network integrity, confidentiality, and availability. Intrusion detection systems have become essential for identifying and mitigating attacks. This research explores using large language models (LLMs) to generate security recommendations based on the temporal traffic patterns of connected UEs. The paper introduces an LLM-driven intrusion detection framework and demonstrates its efficacy through experimental deployments, comparing non fine-tuned and fine-tuned models for task-specific accuracy.
Hashing Algorithms for Large-Scale Learning
Jun 06, 2011



In this paper, we first demonstrate that b-bit minwise hashing, whose estimators are positive definite kernels, can be naturally integrated with learning algorithms such as SVM and logistic regression. We adopt a simple scheme to transform the nonlinear (resemblance) kernel into linear (inner product) kernel; and hence large-scale problems can be solved extremely efficiently. Our method provides a simple effective solution to large-scale learning in massive and extremely high-dimensional datasets, especially when data do not fit in memory. We then compare b-bit minwise hashing with the Vowpal Wabbit (VW) algorithm (which is related the Count-Min (CM) sketch). Interestingly, VW has the same variances as random projections. Our theoretical and empirical comparisons illustrate that usually $b$-bit minwise hashing is significantly more accurate (at the same storage) than VW (and random projections) in binary data. Furthermore, $b$-bit minwise hashing can be combined with VW to achieve further improvements in terms of training speed, especially when $b$ is large.
b-Bit Minwise Hashing for Large-Scale Linear SVM
May 23, 2011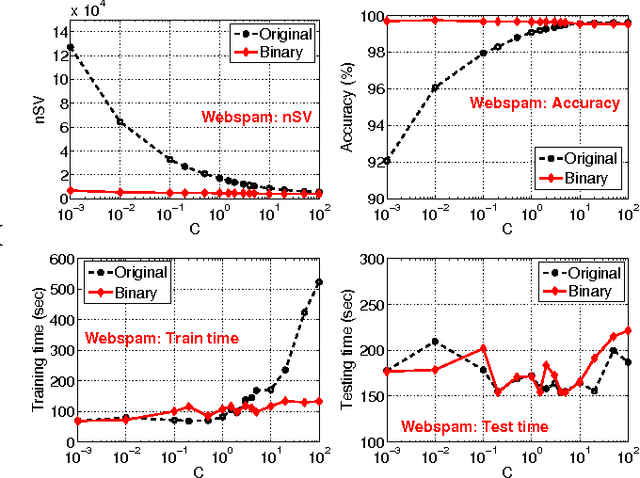
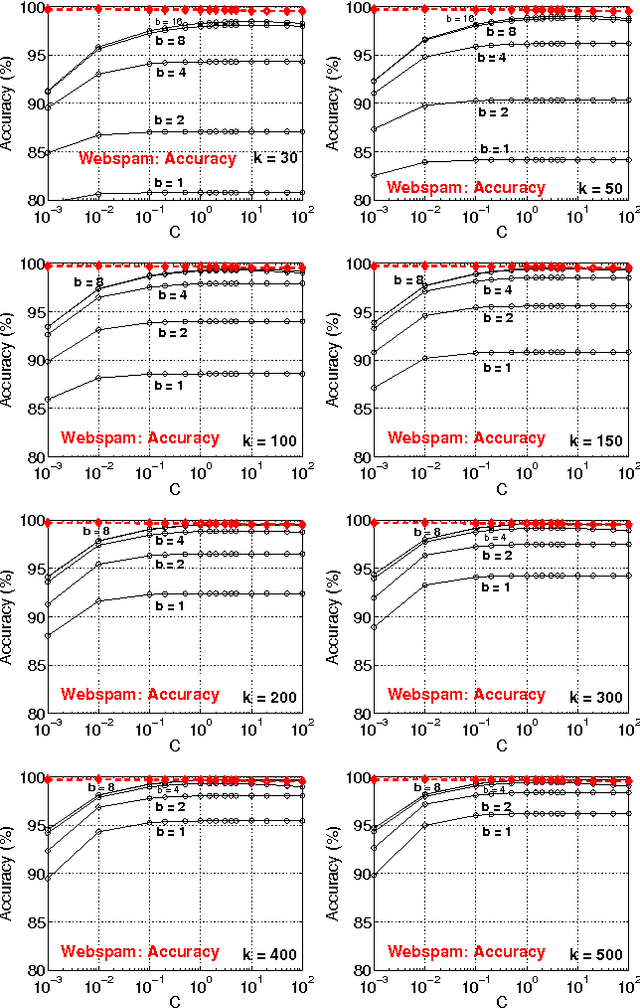
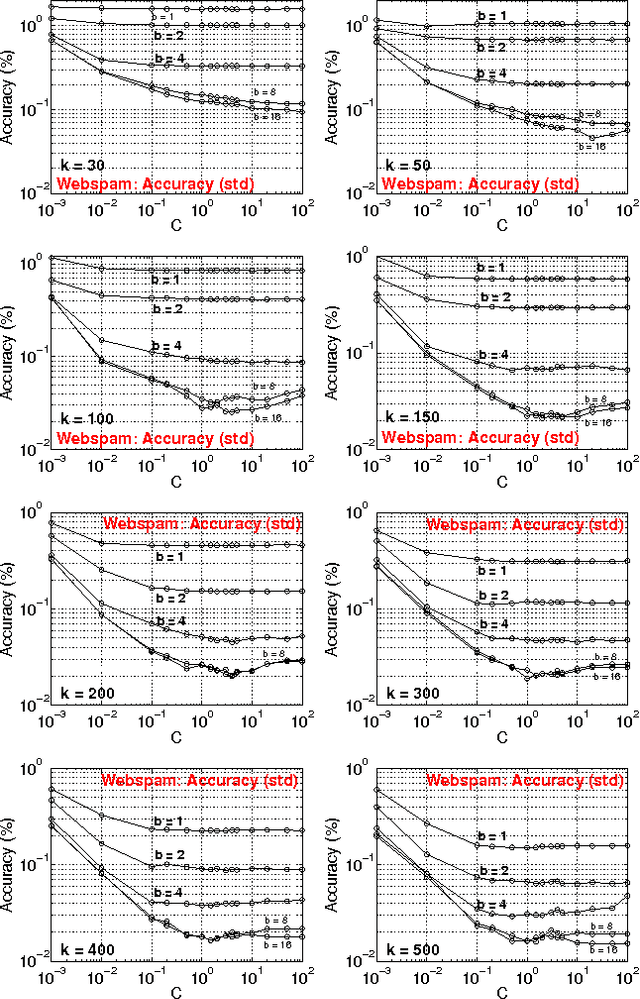
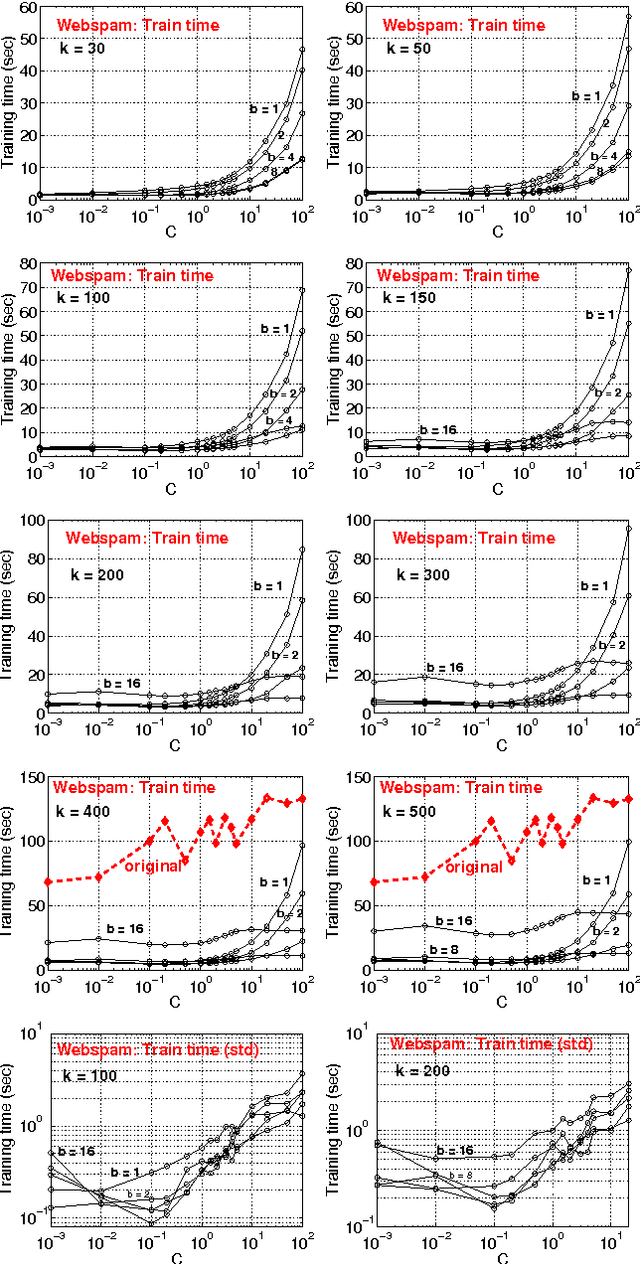
In this paper, we propose to (seamlessly) integrate b-bit minwise hashing with linear SVM to substantially improve the training (and testing) efficiency using much smaller memory, with essentially no loss of accuracy. Theoretically, we prove that the resemblance matrix, the minwise hashing matrix, and the b-bit minwise hashing matrix are all positive definite matrices (kernels). Interestingly, our proof for the positive definiteness of the b-bit minwise hashing kernel naturally suggests a simple strategy to integrate b-bit hashing with linear SVM. Our technique is particularly useful when the data can not fit in memory, which is an increasingly critical issue in large-scale machine learning. Our preliminary experimental results on a publicly available webspam dataset (350K samples and 16 million dimensions) verified the effectiveness of our algorithm. For example, the training time was reduced to merely a few seconds. In addition, our technique can be easily extended to many other linear and nonlinear machine learning applications such as logistic regression.