 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Logistic Regression and SVM on 200GB Data Using b-Bit Minwise Hashing and Comparisons with Vowpal Wabbit
Aug 15, 2011
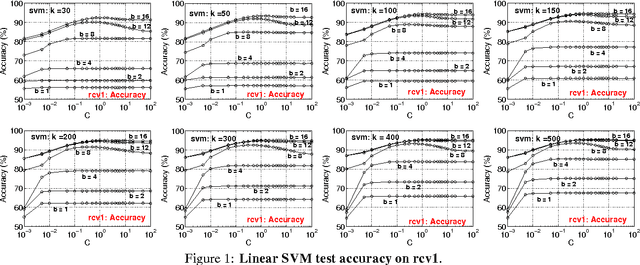

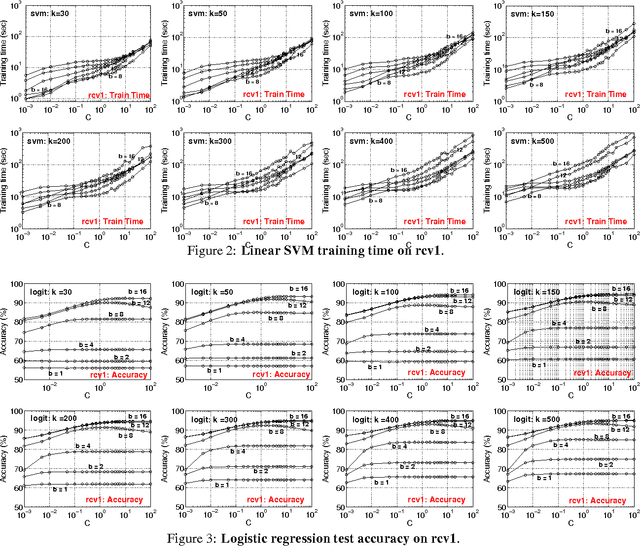
We generated a dataset of 200 GB with 10^9 features, to test our recent b-bit minwise hashing algorithms for training very large-scale logistic regression and SVM. The results confirm our prior work that, compared with the VW hashing algorithm (which has the same variance as random projections), b-bit minwise hashing is substantially more accurate at the same storage. For example, with merely 30 hashed values per data point, b-bit minwise hashing can achieve similar accuracies as VW with 2^14 hashed values per data point. We demonstrate that the preprocessing cost of b-bit minwise hashing is roughly on the same order of magnitude as the data loading time. Furthermore, by using a GPU, the preprocessing cost can be reduced to a small fraction of the data loading time. Minwise hashing has been widely used in industry, at least in the context of search. One reason for its popularity is that one can efficiently simulate permutations by (e.g.,) universal hashing. In other words, there is no need to store the permutation matrix. In this paper, we empirically verify this practice, by demonstrating that even using the simplest 2-universal hashing does not degrade the learning performance.
Accurate Estimators for Improving Minwise Hashing and b-Bit Minwise Hashing
Aug 03, 2011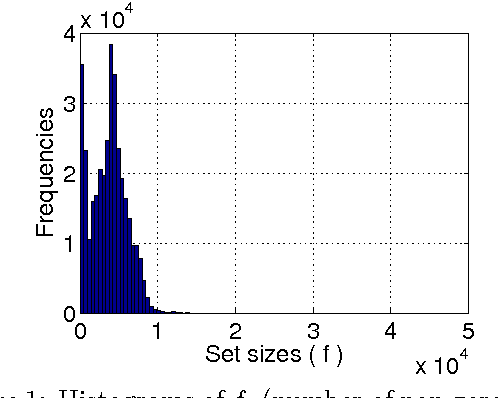
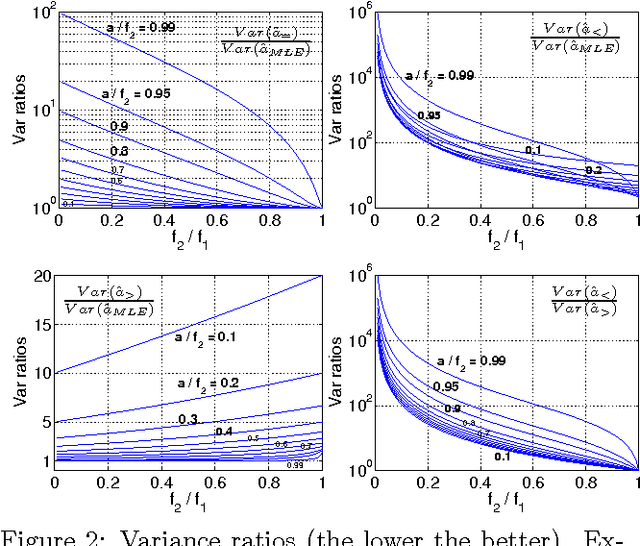
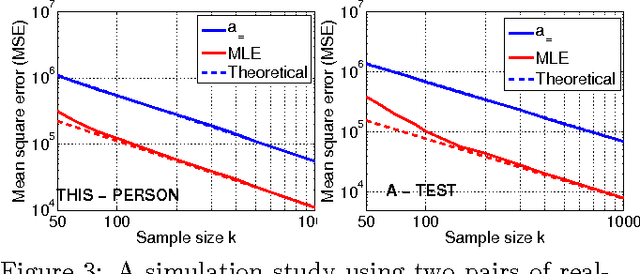
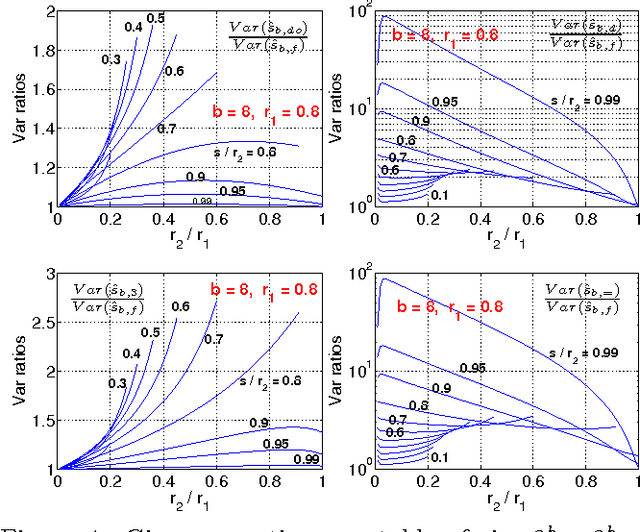
Minwise hashing is the standard technique in the context of search and databases for efficiently estimating set (e.g., high-dimensional 0/1 vector) similarities. Recently, b-bit minwise hashing was proposed which significantly improves upon the original minwise hashing in practice by storing only the lowest b bits of each hashed value, as opposed to using 64 bits. b-bit hashing is particularly effective in applications which mainly concern sets of high similarities (e.g., the resemblance >0.5). However, there are other important applications in which not just pairs of high similarities matter. For example, many learning algorithms require all pairwise similarities and it is expected that only a small fraction of the pairs are similar. Furthermore, many applications care more about containment (e.g., how much one object is contained by another object) than the resemblance. In this paper, we show that the estimators for minwise hashing and b-bit minwise hashing used in the current practice can be systematically improved and the improvements are most significant for set pairs of low resemblance and high containment.
b-Bit Minwise Hashing for Large-Scale Linear SVM
May 23, 2011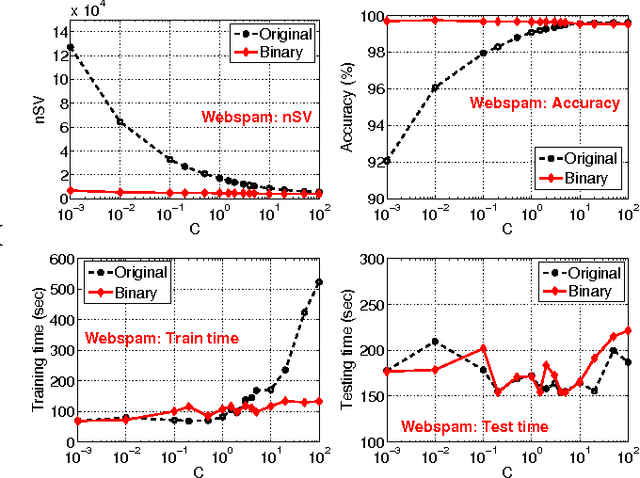
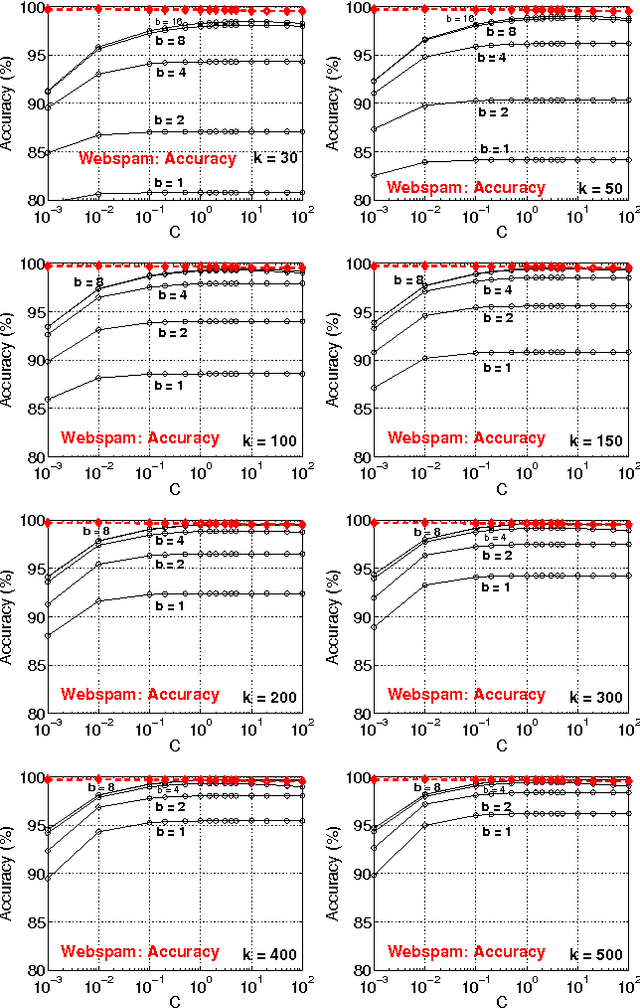
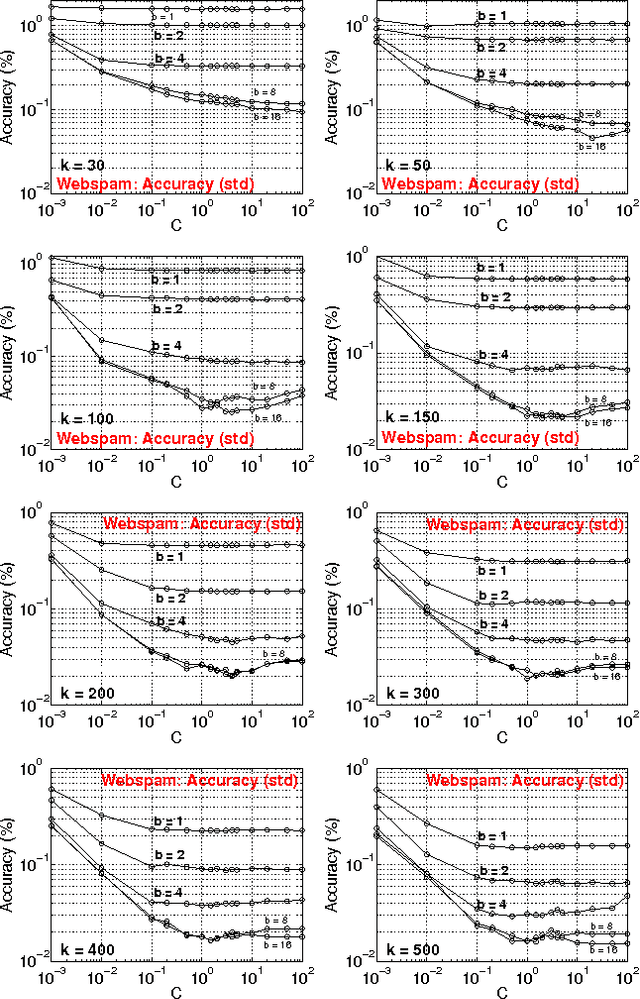
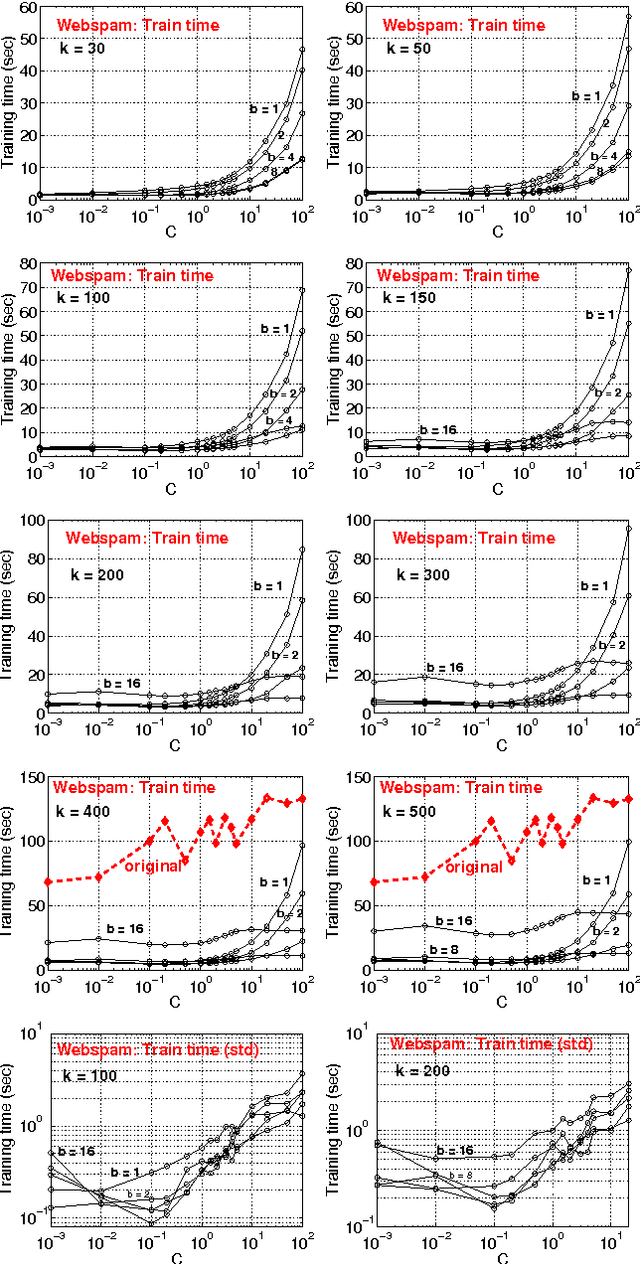
In this paper, we propose to (seamlessly) integrate b-bit minwise hashing with linear SVM to substantially improve the training (and testing) efficiency using much smaller memory, with essentially no loss of accuracy. Theoretically, we prove that the resemblance matrix, the minwise hashing matrix, and the b-bit minwise hashing matrix are all positive definite matrices (kernels). Interestingly, our proof for the positive definiteness of the b-bit minwise hashing kernel naturally suggests a simple strategy to integrate b-bit hashing with linear SVM. Our technique is particularly useful when the data can not fit in memory, which is an increasingly critical issue in large-scale machine learning. Our preliminary experimental results on a publicly available webspam dataset (350K samples and 16 million dimensions) verified the effectiveness of our algorithm. For example, the training time was reduced to merely a few seconds. In addition, our technique can be easily extended to many other linear and nonlinear machine learning applications such as logistic regression.