 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWas that so hard? Estimating human classification difficulty
Mar 22, 2022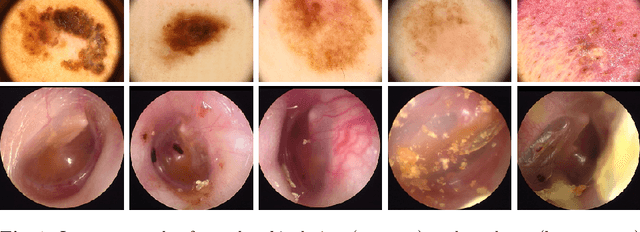
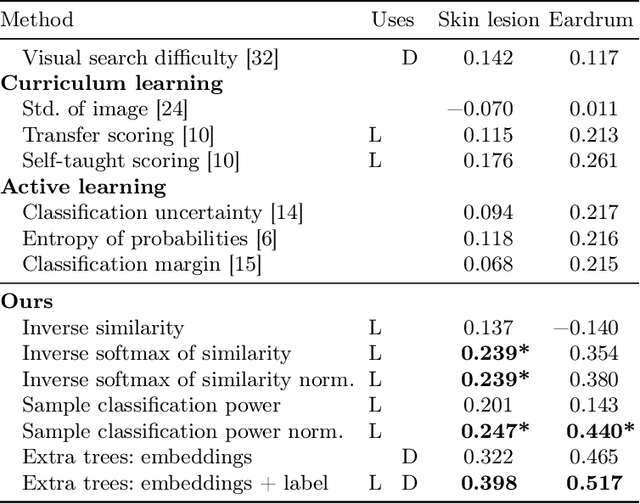

When doctors are trained to diagnose a specific disease, they learn faster when presented with cases in order of increasing difficulty. This creates the need for automatically estimating how difficult it is for doctors to classify a given case. In this paper, we introduce methods for estimating how hard it is for a doctor to diagnose a case represented by a medical image, both when ground truth difficulties are available for training, and when they are not. Our methods are based on embeddings obtained with deep metric learning. Additionally, we introduce a practical method for obtaining ground truth human difficulty for each image case in a dataset using self-assessed certainty. We apply our methods to two different medical datasets, achieving high Kendall rank correlation coefficients, showing that we outperform existing methods by a large margin on our problem and data.
EyeLoveGAN: Exploiting domain-shifts to boost network learning with cycleGANs
Mar 10, 2022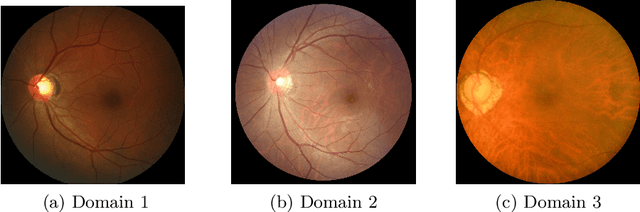
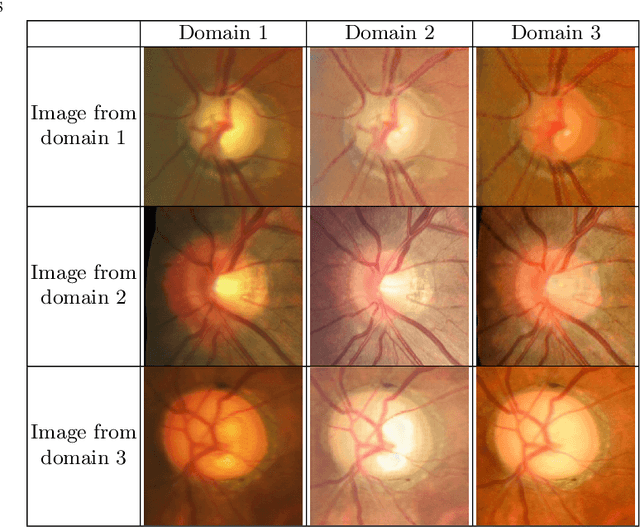
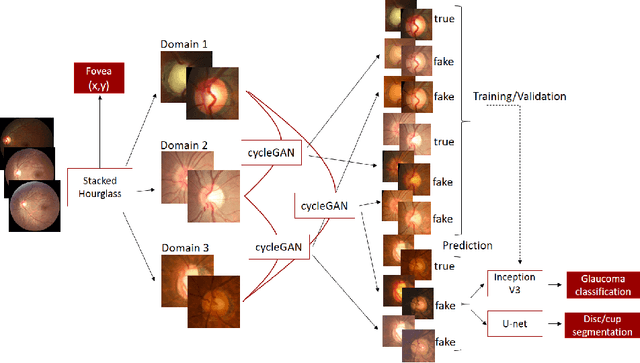
This paper presents our contribution to the REFUGE challenge 2020. The challenge consisted of three tasks based on a dataset of retinal images: Segmentation of optic disc and cup, classification of glaucoma, and localization of fovea. We propose employing convolutional neural networks for all three tasks. Segmentation is performed using a U-Net, classification is performed by a pre-trained InceptionV3 network, and fovea detection is performed by employing stacked hour-glass for heatmap prediction. The challenge dataset contains images from three different data sources. To enhance performance, cycleGANs were utilized to create a domain-shift between the data sources. These cycleGANs move images across domains, thus creating artificial images which can be used for training.
Multi-modal data generation with a deep metric variational autoencoder
Feb 07, 2022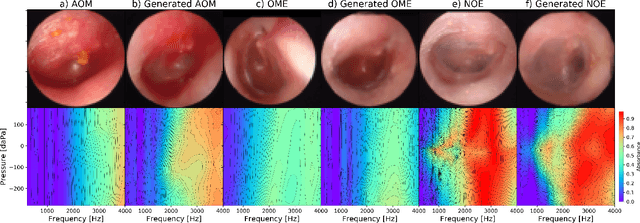
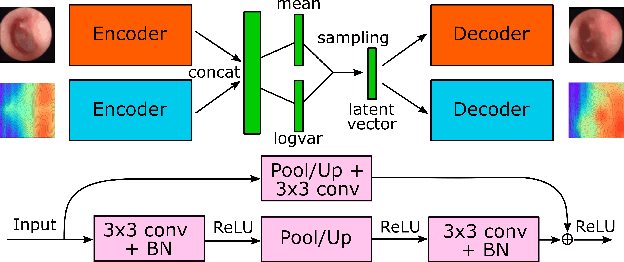
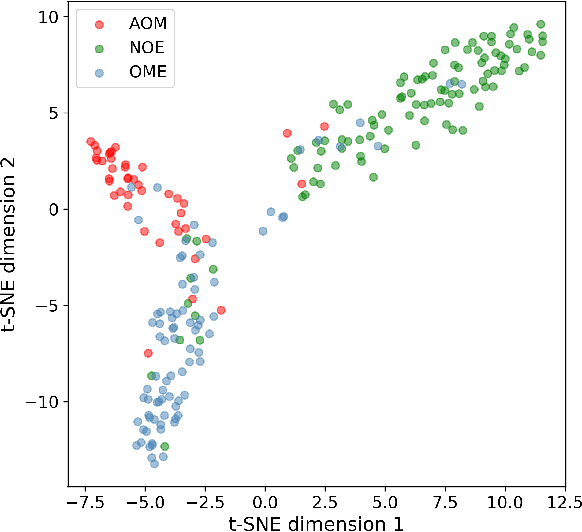
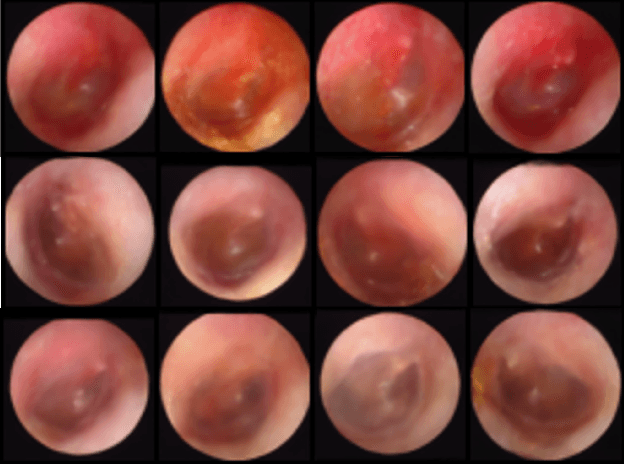
We present a deep metric variational autoencoder for multi-modal data generation. The variational autoencoder employs triplet loss in the latent space, which allows for conditional data generation by sampling in the latent space within each class cluster. The approach is evaluated on a multi-modal dataset consisting of otoscopy images of the tympanic membrane with corresponding wideband tympanometry measurements. The modalities in this dataset are correlated, as they represent different aspects of the state of the middle ear, but they do not present a direct pixel-to-pixel correlation. The approach shows promising results for the conditional generation of pairs of images and tympanograms, and will allow for efficient data augmentation of data from multi-modal sources.