 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriLite: Efficient Weakly Supervised Object Localization with Universal Visual Features and Tri-Region Disentanglement
Feb 26, 2026Weakly supervised object localization (WSOL) aims to localize target objects in images using only image-level labels. Despite recent progress, many approaches still rely on multi-stage pipelines or full fine-tuning of large backbones, which increases training cost, while the broader WSOL community continues to face the challenge of partial object coverage. We present TriLite, a single-stage WSOL framework that leverages a frozen Vision Transformer with Dinov2 pre-training in a self-supervised manner, and introduces only a minimal number of trainable parameters (fewer than 800K on ImageNet-1K) for both classification and localization. At its core is the proposed TriHead module, which decomposes patch features into foreground, background, and ambiguous regions, thereby improving object coverage while suppressing spurious activations. By disentangling classification and localization objectives, TriLite effectively exploits the universal representations learned by self-supervised ViTs without requiring expensive end-to-end training. Extensive experiments on CUB-200-2011, ImageNet-1K, and OpenImages demonstrate that TriLite sets a new state of the art, while remaining significantly more parameter-efficient and easier to train than prior methods. The code will be released soon.
Efficient Post-Hoc Uncertainty Calibration via Variance-Based Smoothing
Mar 19, 2025Since state-of-the-art uncertainty estimation methods are often computationally demanding, we investigate whether incorporating prior information can improve uncertainty estimates in conventional deep neural networks. Our focus is on machine learning tasks where meaningful predictions can be made from sub-parts of the input. For example, in speaker classification, the speech waveform can be divided into sequential patches, each containing information about the same speaker. We observe that the variance between sub-predictions serves as a reliable proxy for uncertainty in such settings. Our proposed variance-based scaling framework produces competitive uncertainty estimates in classification while being less computationally demanding and allowing for integration as a post-hoc calibration tool. This approach also leads to a simple extension of deep ensembles, improving the expressiveness of their predicted distributions.
Enhancing Hyperspectral Image Prediction with Contrastive Learning in Low-Label Regime
Oct 10, 2024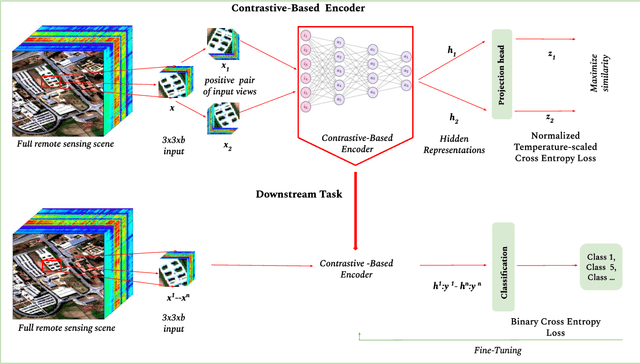

Self-supervised contrastive learning is an effective approach for addressing the challenge of limited labelled data. This study builds upon the previously established two-stage patch-level, multi-label classification method for hyperspectral remote sensing imagery. We evaluate the method's performance for both the single-label and multi-label classification tasks, particularly under scenarios of limited training data. The methodology unfolds in two stages. Initially, we focus on training an encoder and a projection network using a contrastive learning approach. This step is crucial for enhancing the ability of the encoder to discern patterns within the unlabelled data. Next, we employ the pre-trained encoder to guide the training of two distinct predictors: one for multi-label and another for single-label classification. Empirical results on four public datasets show that the predictors trained with our method perform better than those trained under fully supervised techniques. Notably, the performance is maintained even when the amount of training data is reduced by $50\%$. This advantage is consistent across both tasks. The method's effectiveness comes from its streamlined architecture. This design allows for retraining the encoder along with the predictor. As a result, the encoder becomes more adaptable to the features identified by the classifier, improving the overall classification performance. Qualitative analysis reveals the contrastive-learning-based encoder's capability to provide representations that allow separation among classes and identify location-based features despite not being explicitly trained for that. This observation indicates the method's potential in uncovering implicit spatial information within the data.
Deep Model Interpretation with Limited Data : A Coreset-based Approach
Oct 01, 2024Model Interpretation aims at the extraction of insights from the internals of a trained model. A common approach to address this task is the characterization of relevant features internally encoded in the model that are critical for its proper operation. Despite recent progress of these methods, they come with the weakness of being computationally expensive due to the dense evaluation of datasets that they require. As a consequence, research on the design of these methods have focused on smaller data subsets which may led to reduced insights. To address these computational costs, we propose a coreset-based interpretation framework that utilizes coreset selection methods to sample a representative subset of the large dataset for the interpretation task. Towards this goal, we propose a similarity-based evaluation protocol to assess the robustness of model interpretation methods towards the amount data they take as input. Experiments considering several interpretation methods, DNN models, and coreset selection methods show the effectiveness of the proposed framework.
Smooth InfoMax -- Towards easier Post-Hoc interpretability
Aug 23, 2024



We introduce Smooth InfoMax (SIM), a novel method for self-supervised representation learning that incorporates an interpretability constraint into the learned representations at various depths of the neural network. SIM's architecture is split up into probabilistic modules, each locally optimized using the InfoNCE bound. Inspired by VAEs, the representations from these modules are designed to be samples from Gaussian distributions and are further constrained to be close to the standard normal distribution. This results in a smooth and predictable space, enabling traversal of the latent space through a decoder for easier post-hoc analysis of the learned representations. We evaluate SIM's performance on sequential speech data, showing that it performs competitively with its less interpretable counterpart, Greedy InfoMax (GIM). Moreover, we provide insights into SIM's internal representations, demonstrating that the contained information is less entangled throughout the representation and more concentrated in a smaller subset of the dimensions. This further highlights the improved interpretability of SIM.
FICNN: A Framework for the Interpretation of Deep Convolutional Neural Networks
May 17, 2023With the continue development of Convolutional Neural Networks (CNNs), there is a growing concern regarding representations that they encode internally. Analyzing these internal representations is referred to as model interpretation. While the task of model explanation, justifying the predictions of such models, has been studied extensively; the task of model interpretation has received less attention. The aim of this paper is to propose a framework for the study of interpretation methods designed for CNN models trained from visual data. More specifically, we first specify the difference between the interpretation and explanation tasks which are often considered the same in the literature. Then, we define a set of six specific factors that can be used to characterize interpretation methods. Third, based on the previous factors, we propose a framework for the positioning of interpretation methods. Our framework highlights that just a very small amount of the suggested factors, and combinations thereof, have been actually studied. Consequently, leaving significant areas unexplored. Following the proposed framework, we discuss existing interpretation methods and give some attention to the evaluation protocols followed to validate them. Finally, the paper highlights capabilities of the methods in producing feedback for enabling interpretation and proposes possible research problems arising from the framework.
Towards the Characterization of Representations Learned via Capsule-based Network Architectures
May 09, 2023Capsule Networks (CapsNets) have been re-introduced as a more compact and interpretable alternative to standard deep neural networks. While recent efforts have proved their compression capabilities, to date, their interpretability properties have not been fully assessed. Here, we conduct a systematic and principled study towards assessing the interpretability of these types of networks. Moreover, we pay special attention towards analyzing the level to which part-whole relationships are indeed encoded within the learned representation. Our analysis in the MNIST, SVHN, PASCAL-part and CelebA datasets suggest that the representations encoded in CapsNets might not be as disentangled nor strictly related to parts-whole relationships as is commonly stated in the literature.
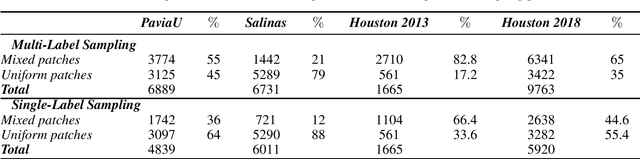
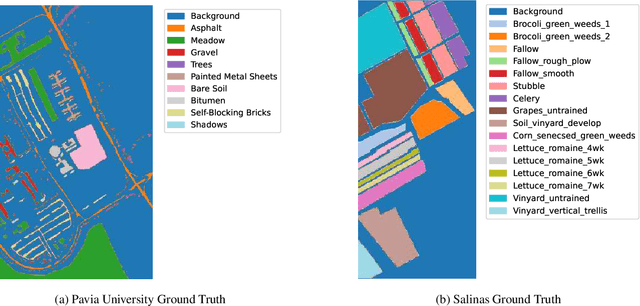
Training Methods of Multi-label Prediction Classifiers for Hyperspectral Remote Sensing Images
Jan 17, 2023With their combined spectral depth and geometric resolution, hyperspectral remote sensing images embed a wealth of complex, non-linear information that challenges traditional computer vision techniques. Yet, deep learning methods known for their representation learning capabilities prove more suitable for handling such complexities. Unlike applications that focus on single-label, pixel-level classification methods for hyperspectral remote sensing images, we propose a multi-label, patch-level classification method based on a two-component deep-learning network. We use patches of reduced spatial dimension and a complete spectral depth extracted from the remote sensing images. Additionally, we investigate three training schemes for our network: Iterative, Joint, and Cascade. Experiments suggest that the Joint scheme is the best-performing scheme; however, its application requires an expensive search for the best weight combination of the loss constituents. The Iterative scheme enables the sharing of features between the two parts of the network at the early stages of training. It performs better on complex data with multi-labels. Further experiments showed that methods designed with different architectures performed well when trained on patches extracted and labeled according to our sampling method.