 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Hyperspectral Image Prediction with Contrastive Learning in Low-Label Regime
Paper and Code
Oct 10, 2024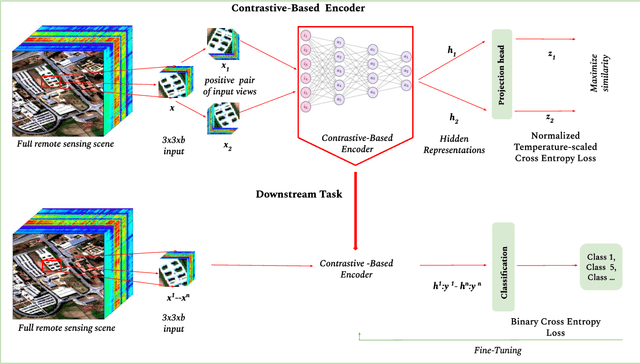
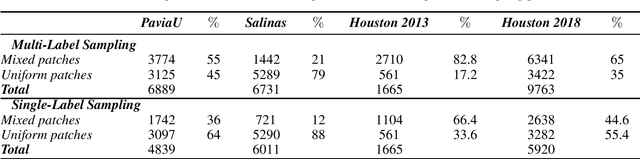
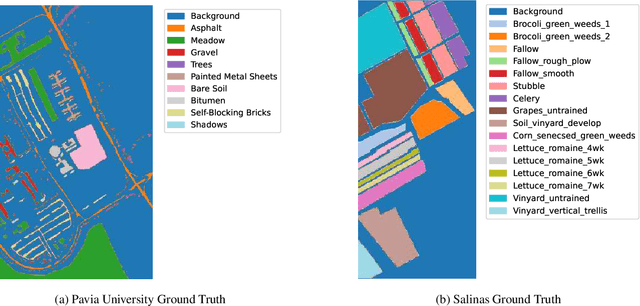

Self-supervised contrastive learning is an effective approach for addressing the challenge of limited labelled data. This study builds upon the previously established two-stage patch-level, multi-label classification method for hyperspectral remote sensing imagery. We evaluate the method's performance for both the single-label and multi-label classification tasks, particularly under scenarios of limited training data. The methodology unfolds in two stages. Initially, we focus on training an encoder and a projection network using a contrastive learning approach. This step is crucial for enhancing the ability of the encoder to discern patterns within the unlabelled data. Next, we employ the pre-trained encoder to guide the training of two distinct predictors: one for multi-label and another for single-label classification. Empirical results on four public datasets show that the predictors trained with our method perform better than those trained under fully supervised techniques. Notably, the performance is maintained even when the amount of training data is reduced by $50\%$. This advantage is consistent across both tasks. The method's effectiveness comes from its streamlined architecture. This design allows for retraining the encoder along with the predictor. As a result, the encoder becomes more adaptable to the features identified by the classifier, improving the overall classification performance. Qualitative analysis reveals the contrastive-learning-based encoder's capability to provide representations that allow separation among classes and identify location-based features despite not being explicitly trained for that. This observation indicates the method's potential in uncovering implicit spatial information within the data.