 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Perception
Nov 21, 2019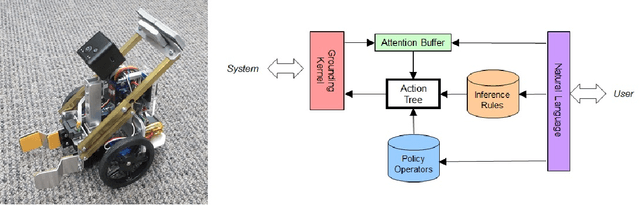
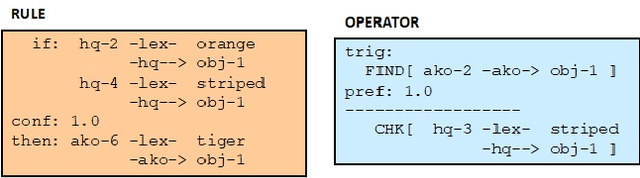
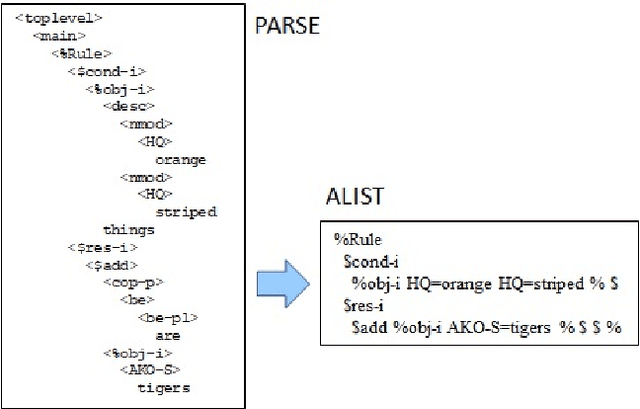
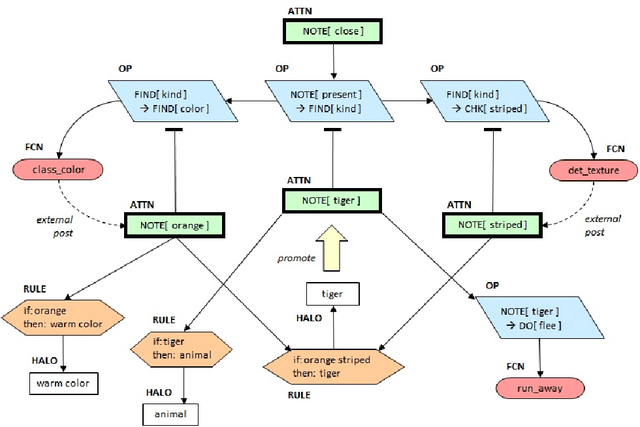
The visual world is very rich and generally too complex to perceive in its entirety. Yet only certain features are typically required to adequately perform some task in a given situation. Rather than hardwire-in decisions about when and what to sense, this paper describes a robotic system whose behavioral policy can be set by verbal instructions it receives. These capabilities are demonstrated in an associated video showing the fully implemented system guiding the perception of a physical robot in simple scenario. The structure and functioning of the underlying natural language based symbolic reasoning system is also discussed.
Verbal Programming of Robot Behavior
Nov 21, 2019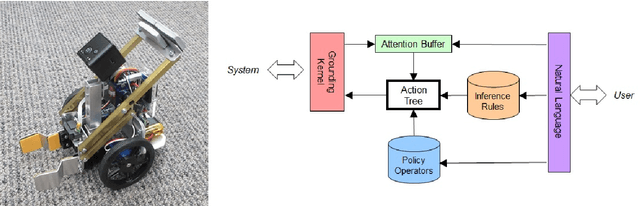
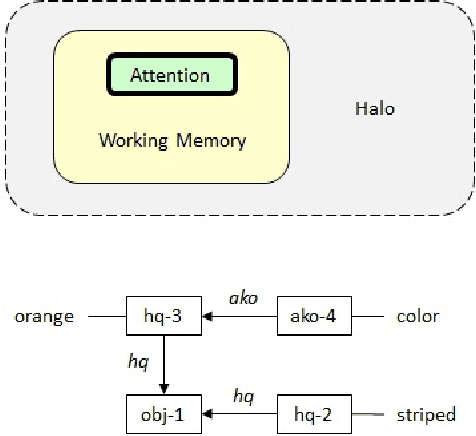

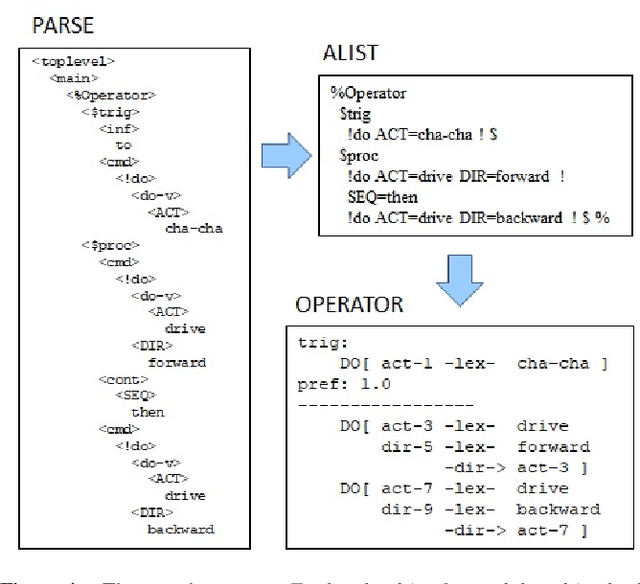
Home robots may come with many sophisticated built-in abilities, however there will always be a degree of customization needed for each user and environment. Ideally this should be accomplished through one-shot learning, as collecting the large number of examples needed for statistical inference is tedious. A particularly appealing approach is to simply explain to the robot, via speech, what it should be doing. In this paper we describe the ALIA cognitive architecture that is able to effectively incorporate user-supplied advice and prohibitions in this manner. The functioning of the implemented system on a small robot is illustrated by an associated video.
Structured Differential Learning for Automatic Threshold Setting
Aug 01, 2018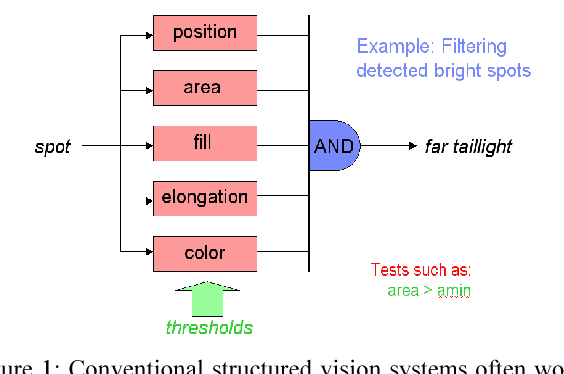
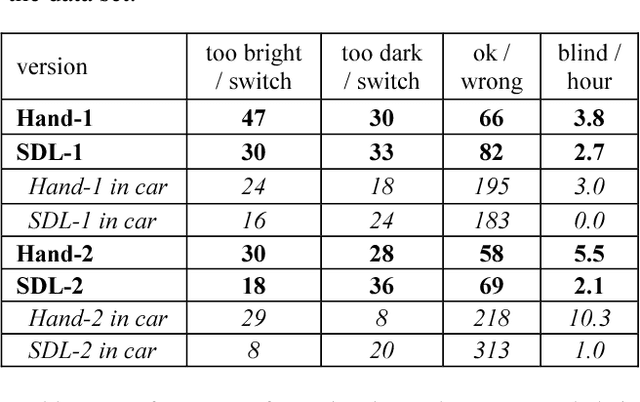
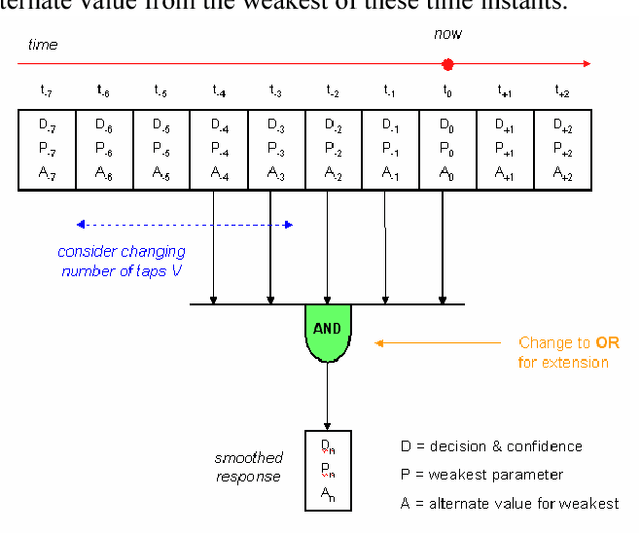
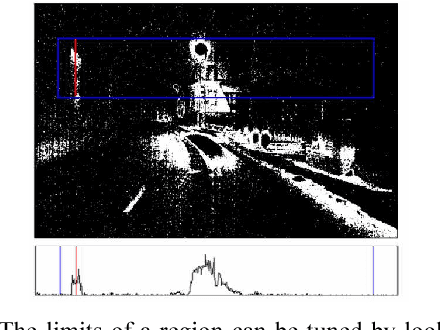
We introduce a technique that can automatically tune the parameters of a rule-based computer vision system comprised of thresholds, combinational logic, and time constants. This lets us retain the flexibility and perspicacity of a conventionally structured system while allowing us to perform approximate gradient descent using labeled data. While this is only a heuristic procedure, as far as we are aware there is no other efficient technique for tuning such systems. We describe the components of the system and the associated supervised learning mechanism. We also demonstrate the utility of the algorithm by comparing its performance versus hand tuning for an automotive headlight controller. Despite having over 100 parameters, the method is able to profitably adjust the system values given just the desired output for a number of videos.
Extensible Grounding of Speech for Robot Instruction
Jul 31, 2018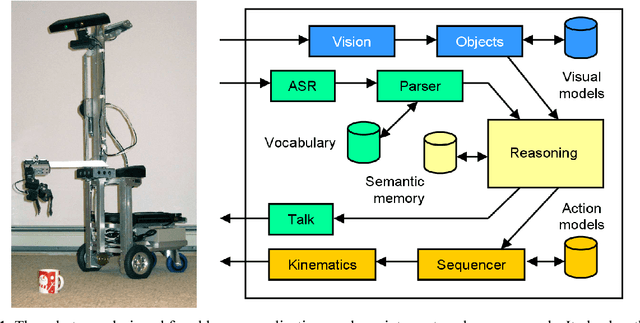

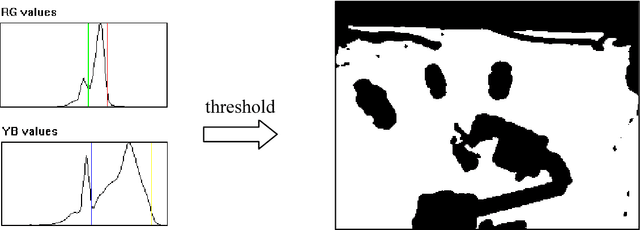

Spoken language is a convenient interface for commanding a mobile robot. Yet for this to work a number of base terms must be grounded in perceptual and motor skills. We detail the language processing used on our robot ELI and explain how this grounding is performed, how it interacts with user gestures, and how it handles phenomena such as anaphora. More importantly, however, there are certain concepts which the robot cannot be preprogrammed with, such as the names of various objects in a household or the nature of specific tasks it may be requested to perform. In these cases it is vital that there exist a method for extending the grounding, essentially "learning by being told". We describe how this was successfully implemented for learning new nouns and verbs in a tabletop setting. Creating this language learning kernel may be the last explicit programming the robot ever needs - the core mechanism could eventually be used for imparting a vast amount of knowledge, much as a child learns from its parents and teachers.
Setting Up Pepper For Autonomous Navigation And Personalized Interaction With Users
Apr 16, 2017
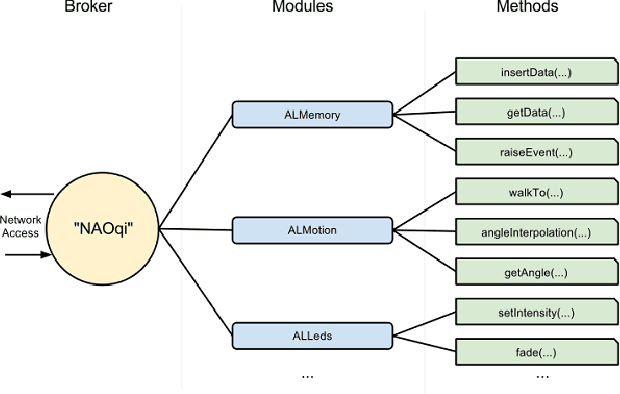
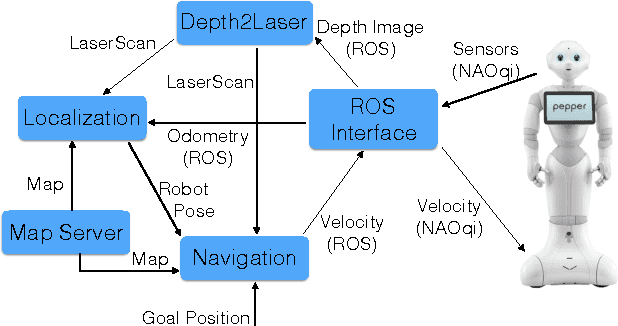
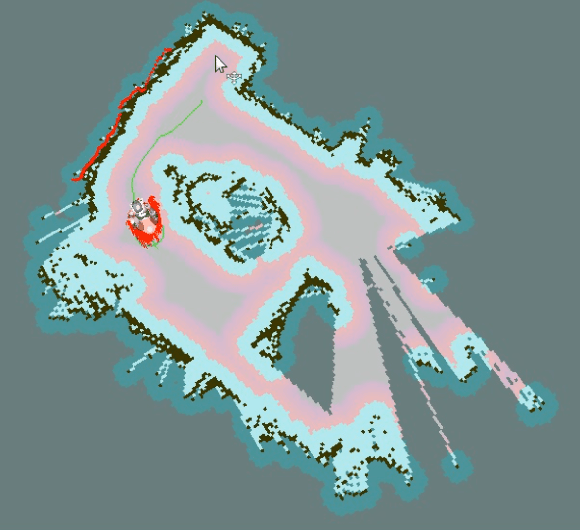
In this paper we present our work with the Pepper robot, a service robot from SoftBank Robotics. We had two main goals in this work: improving the autonomy of this robot by increasing its awareness of the environment; and enhance the robot ability to interact with its users. To achieve this goals, we used ROS, a modern open-source framework for developing robotics software, to provide Pepper with state of the art localization and navigation capabilities. Furthermore, we contribute an architecture for effective human interaction based on cloud services. Our architecture improves Pepper speech recognition capabilities by connecting it to the IBM Bluemix Speech Recognition service and enable the robot to recognize its user via an in-house face recognition web-service. We show examples of our successful integration of ROS and IBM services with Pepper's own software. As a result, we were able to make Pepper move autonomously in a environment with humans and obstacles. We were also able to have Pepper execute spoken commands from known users as well as newly introduced users that were enrolled in the robot list of trusted users via a multi-modal interface.