 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of Time and Distance of Trips Using Explainable Attention-based LSTMs
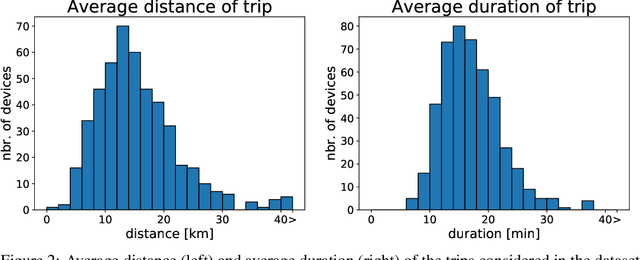
Mar 27, 2023In this paper, we propose machine learning solutions to predict the time of future trips and the possible distance the vehicle will travel. For this prediction task, we develop and investigate four methods. In the first method, we use long short-term memory (LSTM)-based structures specifically designed to handle multi-dimensional historical data of trip time and distances simultaneously. Using it, we predict the future trip time and forecast the distance a vehicle will travel by concatenating the outputs of LSTM networks through fully connected layers. The second method uses attention-based LSTM networks (At-LSTM) to perform the same tasks. The third method utilizes two LSTM networks in parallel, one for forecasting the time of the trip and the other for predicting the distance. The output of each LSTM is then concatenated through fully connected layers. Finally, the last model is based on two parallel At-LSTMs, where similarly, each At-LSTM predicts time and distance separately through fully connected layers. Among the proposed methods, the most advanced one, i.e., parallel At-LSTM, predicts the next trip's distance and time with 3.99% error margin where it is 23.89% better than LSTM, the first method. We also propose TimeSHAP as an explainability method for understanding how the networks perform learning and model the sequence of information.
Cold-Start Modeling and On-Line Optimal Control of the Three-Way Catalyst
Apr 26, 2021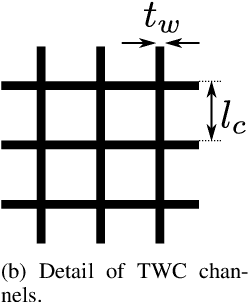
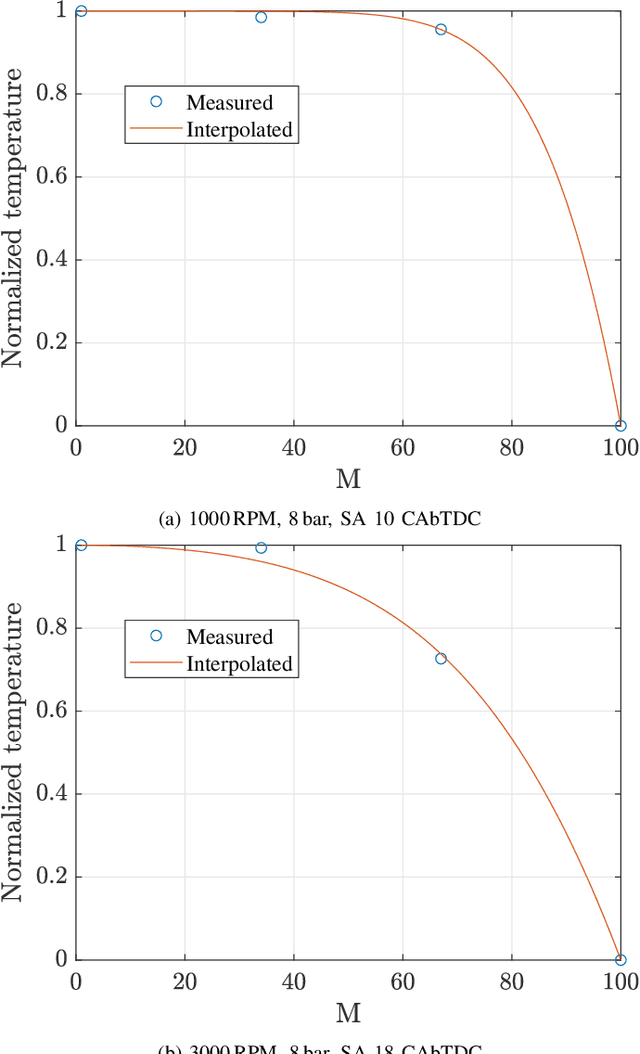


We present a three-way catalyst (TWC) cold-start model, calibrate the model based on experimental data from multiple operating points, and use the model to generate a Pareto-optimal cold-start controller suitable for implementation in standard engine control unit hardware. The TWC model is an extension of a previously presented physics-based model that predicts carbon monoxide, hydrocarbon, and nitrogen oxides tailpipe emissions. The model axially and radially resolves the temperatures in the monolith using very few state variables, thus allowing for use with control-policy based optimal control methods. In this paper we extend the model to allow for variable axial discretization lengths, include the heat of reaction from hydrogen gas generated from the combustion engine, and reformulate the model parameters to be expressed in conventional units. We experimentally measured the temperature and emission evolution for cold-starts with ten different engine load points, which was subsequently used to tune the model parameters (e.g.~chemical reaction rates, specific heats, and thermal resistances). The simulated cumulative tailpipe emission modeling error was found to be typically -20% to +80% of the measured emissions. We have constructed and simulated the performance of a Pareto-optimal controller using this model that balances fuel efficiency and the cumulative emissions of each individual species. A benchmark of the optimal controller with a conventional cold-start strategy shows the potential for reducing the cold-start emissions.
A Unified Framework for Online Trip Destination Prediction
Jan 12, 2021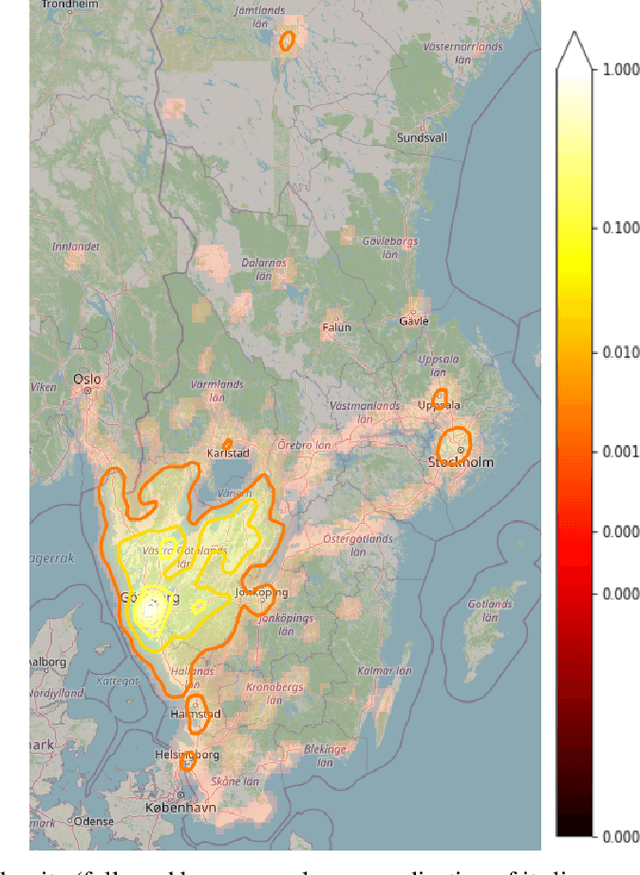
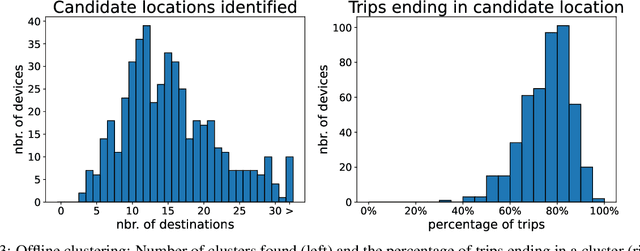
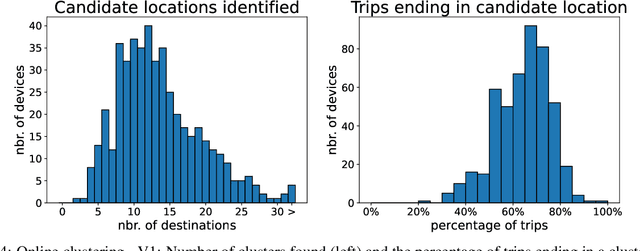
Trip destination prediction is an area of increasing importance in many applications such as trip planning, autonomous driving and electric vehicles. Even though this problem could be naturally addressed in an online learning paradigm where data is arriving in a sequential fashion, the majority of research has rather considered the offline setting. In this paper, we present a unified framework for trip destination prediction in an online setting, which is suitable for both online training and online prediction. For this purpose, we develop two clustering algorithms and integrate them within two online prediction models for this problem. We investigate the different configurations of clustering algorithms and prediction models on a real-world dataset. By using traditional clustering metrics and accuracy, we demonstrate that both the clustering and the entire framework yield consistent results compared to the offline setting. Finally, we propose a novel regret metric for evaluating the entire online framework in comparison to its offline counterpart. This metric makes it possible to relate the source of erroneous predictions to either the clustering or the prediction model. Using this metric, we show that the proposed methods converge to a probability distribution resembling the true underlying distribution and enjoy a lower regret than all of the baselines.