 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Framework for Causal Analysis of Recurrent Events in Presence of Immortal Risk
Apr 06, 2023Observational studies of recurrent event rates are common in biomedical statistics. Broadly, the goal is to estimate differences in event rates under two treatments within a defined target population over a specified followup window. Estimation with observational claims data is challenging because while membership in the target population is defined in terms of eligibility criteria, treatment is rarely assigned exactly at the time of eligibility. Ad-hoc solutions to this timing misalignment, such as assigning treatment at eligibility based on subsequent assignment, incorrectly attribute prior event rates to treatment - resulting in immortal risk bias. Even if eligibility and treatment are aligned, a terminal event process (e.g. death) often stops the recurrent event process of interest. Both processes are also censored so that events are not observed over the entire followup window. Our approach addresses misalignment by casting it as a treatment switching problem: some patients are on treatment at eligibility while others are off treatment but may switch to treatment at a specified time - if they survive long enough. We define and identify an average causal effect of switching under specified causal assumptions. Estimation is done using a g-computation framework with a joint semiparametric Bayesian model for the death and recurrent event processes. Computing the estimand for various switching times allows us to assess the impact of treatment timing. We apply the method to contrast hospitalization rates under different opioid treatment strategies among patients with chronic back pain using Medicare claims data.
Tree-based Subgroup Discovery In Electronic Health Records: Heterogeneity of Treatment Effects for DTG-containing Therapies
Aug 30, 2022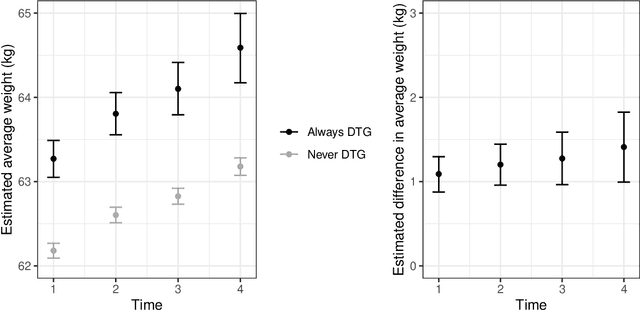



The rich longitudinal individual level data available from electronic health records (EHRs) can be used to examine treatment effect heterogeneity. However, estimating treatment effects using EHR data poses several challenges, including time-varying confounding, repeated and temporally non-aligned measurements of covariates, treatment assignments and outcomes, and loss-to-follow-up due to dropout. Here, we develop the Subgroup Discovery for Longitudinal Data (SDLD) algorithm, a tree-based algorithm for discovering subgroups with heterogeneous treatment effects using longitudinal data by combining the generalized interaction tree algorithm, a general data-driven method for subgroup discovery, with longitudinal targeted maximum likelihood estimation. We apply the algorithm to EHR data to discover subgroups of people living with human immunodeficiency virus (HIV) who are at higher risk of weight gain when receiving dolutegravir-containing antiretroviral therapies (ARTs) versus when receiving non dolutegravir-containing ARTs.
Causal Interaction Trees: Tree-Based Subgroup Identification for Observational Data
Mar 06, 2020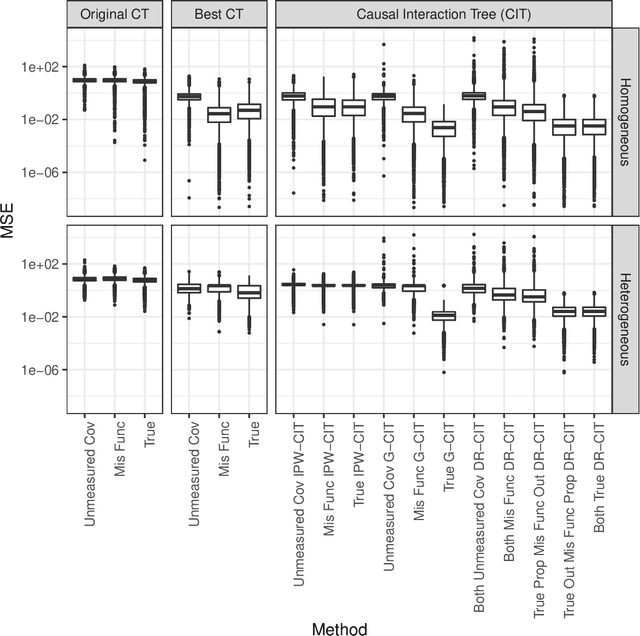
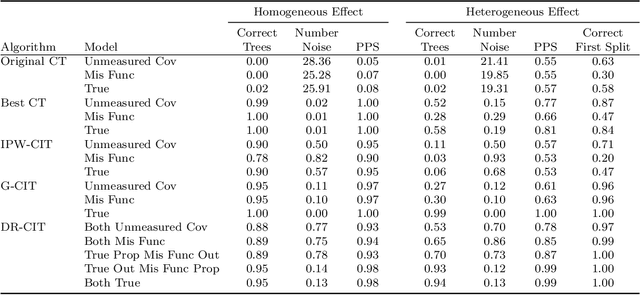
We propose Causal Interaction Trees for identifying subgroups of participants that have enhanced treatment effects using observational data. We extend the Classification and Regression Tree algorithm by using splitting criteria that focus on maximizing between-group treatment effect heterogeneity based on subgroup-specific treatment effect estimators to dictate decision-making in the algorithm. We derive properties of three subgroup-specific treatment effect estimators that account for the observational nature of the data -- inverse probability weighting, g-formula and doubly robust estimators. We study the performance of the proposed algorithms using simulations and implement the algorithms in an observational study that evaluates the effectiveness of right heart catheterization on critically ill patients.