 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Cultural Differences in News Video Thumbnails via Computational Aesthetics
May 28, 2025We propose a two-step approach for detecting differences in the style of images across sources of differing cultural affinity, where images are first clustered into finer visual themes based on content before their aesthetic features are compared. We test this approach on 2,400 YouTube video thumbnails taken equally from two U.S. and two Chinese YouTube channels, and relating equally to COVID-19 and the Ukraine conflict. Our results suggest that while Chinese thumbnails are less formal and more candid, U.S. channels tend to use more deliberate, proper photographs as thumbnails. In particular, U.S. thumbnails are less colorful, more saturated, darker, more finely detailed, less symmetric, sparser, less varied, and more up close and personal than Chinese thumbnails. We suggest that most of these differences reflect cultural preferences, and that our methods and observations can serve as a baseline against which suspected visual propaganda can be computed and compared.
3D Human motion anticipation and classification
Dec 31, 2020


Human motion prediction and understanding is a challenging problem. Due to the complex dynamic of human motion and the non-deterministic aspect of future prediction. We propose a novel sequence-to-sequence model for human motion prediction and feature learning, trained with a modified version of generative adversarial network, with a custom loss function that takes inspiration from human motion animation and can control the variation between multiple predicted motion from the same input poses. Our model learns to predict multiple future sequences of human poses from the same input sequence. We show that the discriminator learns general presentation of human motion by using the learned feature in action recognition task. Furthermore, to quantify the quality of the non-deterministic predictions, we simultaneously train a motion-quality-assessment network that learns the probability that a given sequence of poses is a real human motion or not. We test our model on two of the largest human pose datasets: NTURGB-D and Human3.6M. We train on both single and multiple action types. Its predictive power for motion estimation is demonstrated by generating multiple plausible futures from the same input and show the effect of each of the loss functions. Furthermore, we show that it takes less than half the number of epochs to train an activity recognition network by using the feature learned from the discriminator.
Report: Dynamic Eye Movement Matching and Visualization Tool in Neuro Gesture
Jan 07, 2018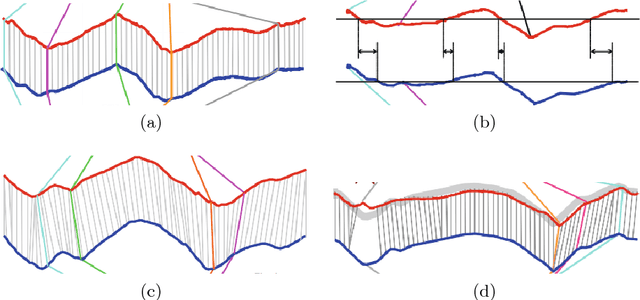

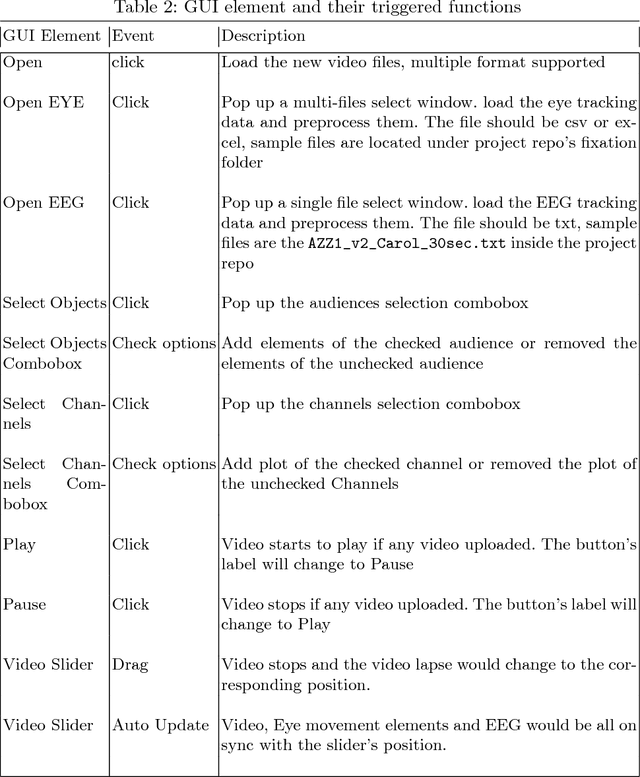
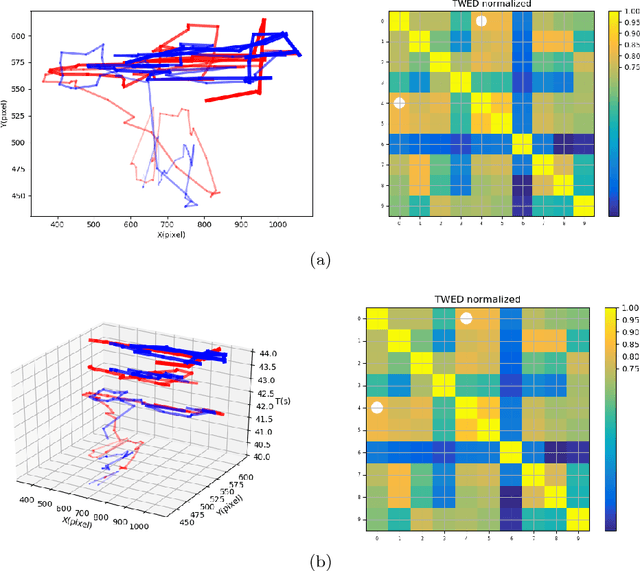
In the research of the impact of gestures using by a lecturer, one challenging task is to infer the attention of a group of audiences. Two important measurements that can help infer the level of attention are eye movement data and Electroencephalography (EEG) data. Under the fundamental assumption that a group of people would look at the same place if they all pay attention at the same time, we apply a method, "Time Warp Edit Distance", to calculate the similarity of their eye movement trajectories. Moreover, we also cluster eye movement pattern of audiences based on these pair-wised similarity metrics. Besides, since we don't have a direct metric for the "attention" ground truth, a visual assessment would be beneficial to evaluate the gesture-attention relationship. Thus we also implement a visualization tool.
HP-GAN: Probabilistic 3D human motion prediction via GAN
Nov 27, 2017
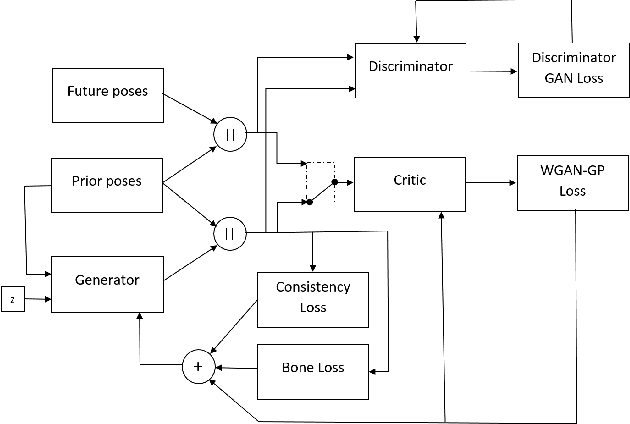
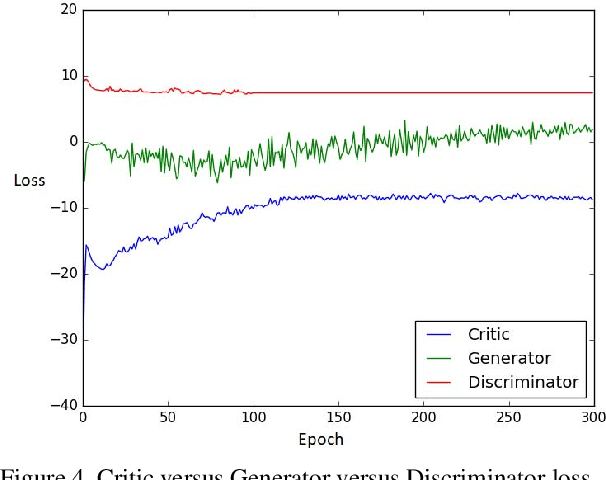
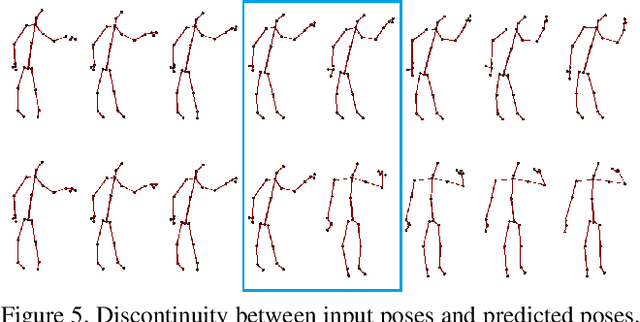
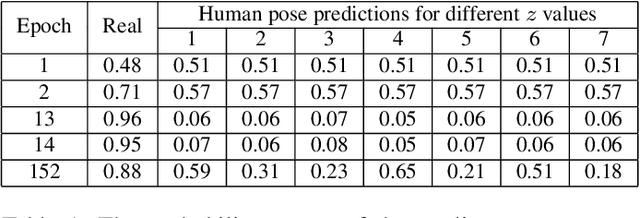
Predicting and understanding human motion dynamics has many applications, such as motion synthesis, augmented reality, security, and autonomous vehicles. Due to the recent success of generative adversarial networks (GAN), there has been much interest in probabilistic estimation and synthetic data generation using deep neural network architectures and learning algorithms. We propose a novel sequence-to-sequence model for probabilistic human motion prediction, trained with a modified version of improved Wasserstein generative adversarial networks (WGAN-GP), in which we use a custom loss function designed for human motion prediction. Our model, which we call HP-GAN, learns a probability density function of future human poses conditioned on previous poses. It predicts multiple sequences of possible future human poses, each from the same input sequence but a different vector z drawn from a random distribution. Furthermore, to quantify the quality of the non-deterministic predictions, we simultaneously train a motion-quality-assessment model that learns the probability that a given skeleton sequence is a real human motion. We test our algorithm on two of the largest skeleton datasets: NTURGB-D and Human3.6M. We train our model on both single and multiple action types. Its predictive power for long-term motion estimation is demonstrated by generating multiple plausible futures of more than 30 frames from just 10 frames of input. We show that most sequences generated from the same input have more than 50\% probabilities of being judged as a real human sequence. We will release all the code used in this paper to Github.