 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human motion anticipation and classification
Paper and Code
Dec 31, 2020
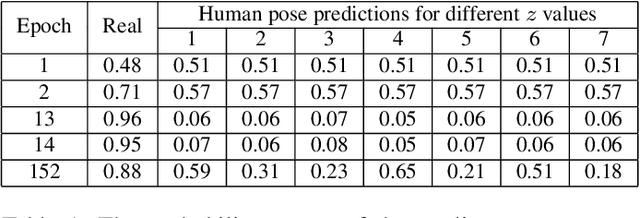


Human motion prediction and understanding is a challenging problem. Due to the complex dynamic of human motion and the non-deterministic aspect of future prediction. We propose a novel sequence-to-sequence model for human motion prediction and feature learning, trained with a modified version of generative adversarial network, with a custom loss function that takes inspiration from human motion animation and can control the variation between multiple predicted motion from the same input poses. Our model learns to predict multiple future sequences of human poses from the same input sequence. We show that the discriminator learns general presentation of human motion by using the learned feature in action recognition task. Furthermore, to quantify the quality of the non-deterministic predictions, we simultaneously train a motion-quality-assessment network that learns the probability that a given sequence of poses is a real human motion or not. We test our model on two of the largest human pose datasets: NTURGB-D and Human3.6M. We train on both single and multiple action types. Its predictive power for motion estimation is demonstrated by generating multiple plausible futures from the same input and show the effect of each of the loss functions. Furthermore, we show that it takes less than half the number of epochs to train an activity recognition network by using the feature learned from the discriminator.