 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealigned Softmax Warping for Deep Metric Learning
Sep 03, 2024



Deep Metric Learning (DML) loss functions traditionally aim to control the forces of separability and compactness within an embedding space so that the same class data points are pulled together and different class ones are pushed apart. Within the context of DML, a softmax operation will typically normalize distances into a probability for optimization, thus coupling all the push/pull forces together. This paper proposes a potential new class of loss functions that operate within a euclidean domain and aim to take full advantage of the coupled forces governing embedding space formation under a softmax. These forces of compactness and separability can be boosted or mitigated within controlled locations at will by using a warping function. In this work, we provide a simple example of a warping function and use it to achieve competitive, state-of-the-art results on various metric learning benchmarks.
Arrhythmia Classification using CGAN-augmented ECG Signals
Jan 26, 2022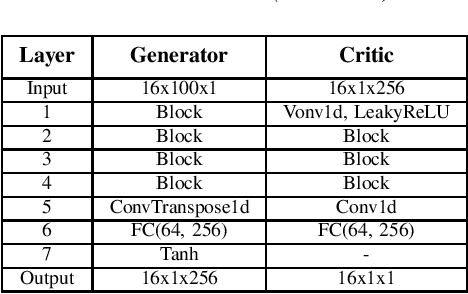
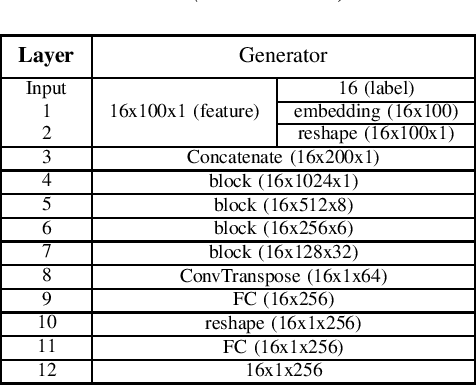
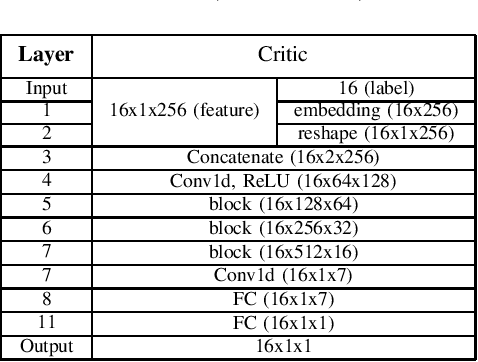
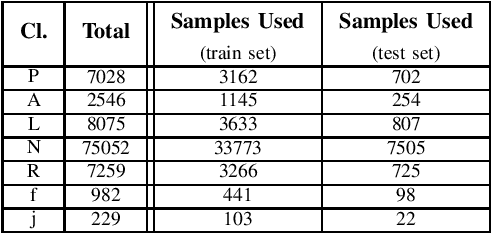
One of the easiest ways to diagnose cardiovascular conditions is Electrocardiogram (ECG) analysis. ECG databases usually have highly imbalanced distributions due to the abundance of Normal ECG and scarcity of abnormal cases which are equally, if not more, important for arrhythmia detection. As such, DL classifiers trained on these datasets usually perform poorly, especially on minor classes. One solution to address the imbalance is to generate realistic synthetic ECG signals mostly using Generative Adversarial Networks (GAN) to augment and the datasets. In this study, we designed an experiment to investigate the impact of data augmentation on arrhythmia classification. Using the MIT-BIH Arrhythmia dataset, we employed two ways for ECG beats generation: (i) an unconditional GAN, i.e., Wasserstein GAN with gradient penalty (WGAN-GP) is trained on each class individually; (ii) a conditional GAN model, i.e., Auxiliary Classifier Wasserstein GAN with gradient penalty (AC-WGAN-GP) is trained on all the available classes to train one single generator. Two scenarios are defined for each case: i) unscreened where all the generated synthetic beats were used directly without any post-processing, and ii) screened where a portion of generated beats are selected based on their Dynamic Time Warping (DTW) distance with a designated template. A ResNet classifier is trained on each of the four augmented datasets and the performance metrics of precision, recall and F1-Score as well as the confusion matrices were compared with the reference case, i.e., when the classifier is trained on the imbalanced original dataset. The results show that in all four cases augmentation achieves impressive improvements in metrics particularly on minor classes (typically from 0 or 0.27 to 0.99). The quality of the generated beats is also evaluated using DTW distance function compared with real data.
Synthetic ECG Signal Generation Using Generative Neural Networks
Dec 05, 2021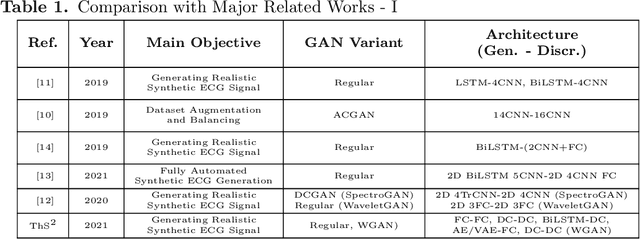
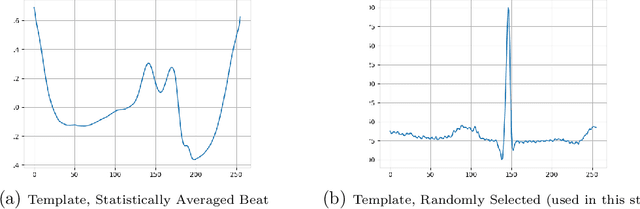
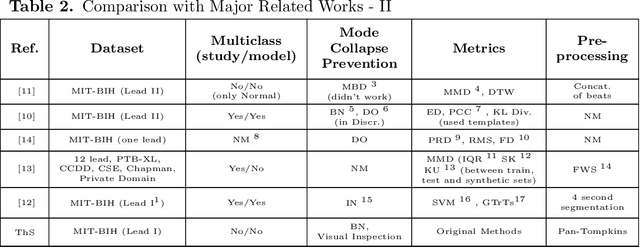
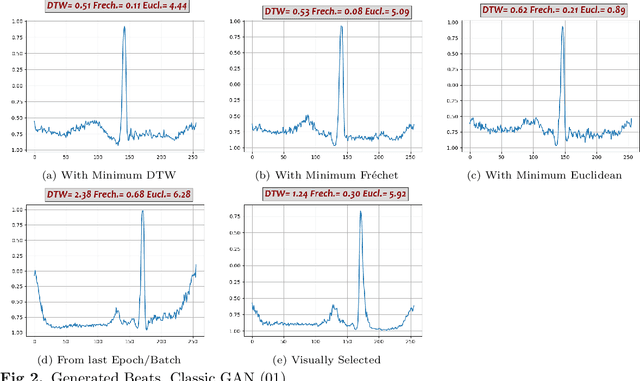
Electrocardiogram (ECG) datasets tend to be highly imbalanced due to the scarcity of abnormal cases. Additionally, the use of real patients' ECG is highly regulated due to privacy issues. Therefore, there is always a need for more ECG data, especially for the training of automatic diagnosis machine learning models, which perform better when trained on a balanced dataset. We studied the synthetic ECG generation capability of 5 different models from the generative adversarial network (GAN) family and compared their performances, the focus being only on Normal cardiac cycles. Dynamic Time Warping (DTW), Fr\'echet, and Euclidean distance functions were employed to quantitatively measure performance. Five different methods for evaluating generated beats were proposed and applied. We also proposed 3 new concepts (threshold, accepted beat and productivity rate) and employed them along with the aforementioned methods as a systematic way for comparison between models. The results show that all the tested models can to an extent successfully mass-generate acceptable heartbeats with high similarity in morphological features, and potentially all of them can be used to augment imbalanced datasets. However, visual inspections of generated beats favor BiLSTM-DC GAN and WGAN, as they produce statistically more acceptable beats. Also, with regards to productivity rate, the Classic GAN is superior with a 72% productivity rate.
FoleyGAN: Visually Guided Generative Adversarial Network-Based Synchronous Sound Generation in Silent Videos
Jul 20, 2021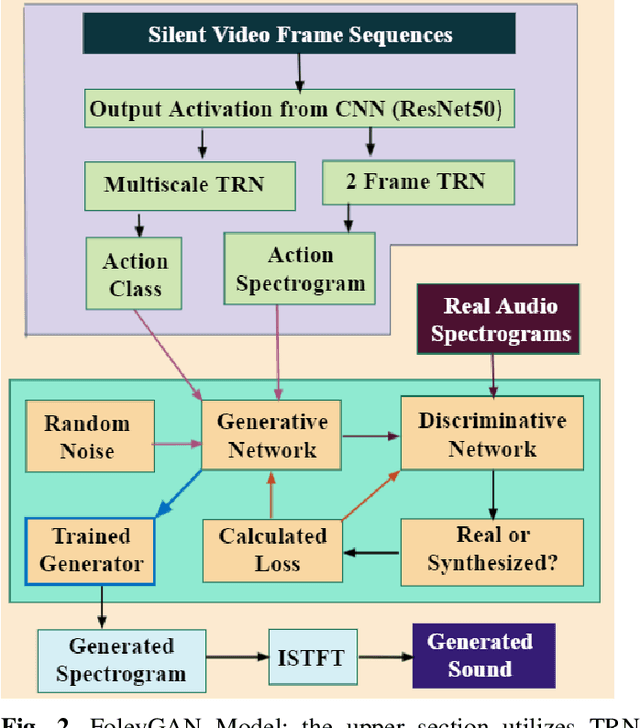
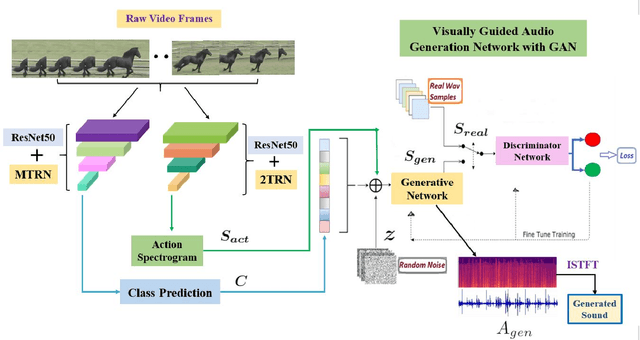
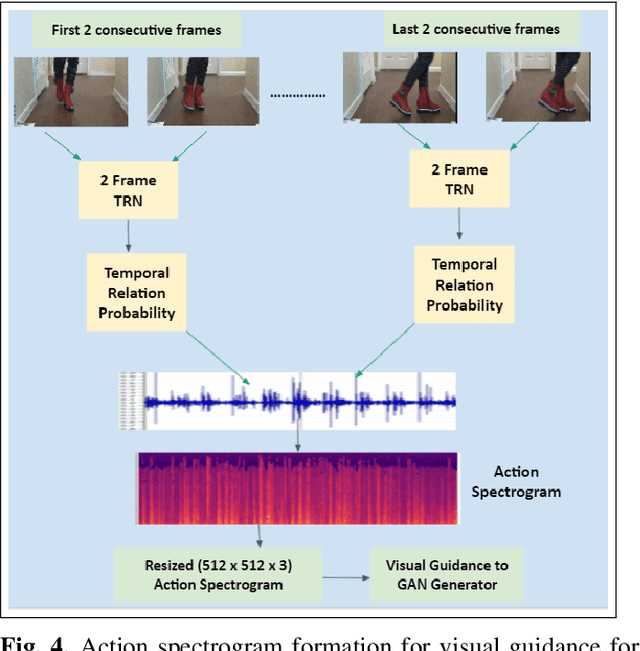
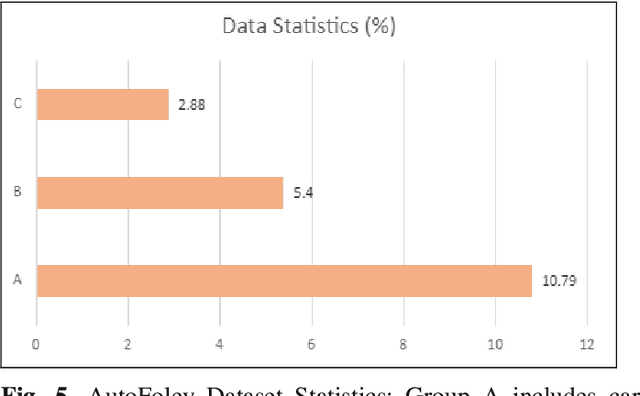
Deep learning based visual to sound generation systems essentially need to be developed particularly considering the synchronicity aspects of visual and audio features with time. In this research we introduce a novel task of guiding a class conditioned generative adversarial network with the temporal visual information of a video input for visual to sound generation task adapting the synchronicity traits between audio-visual modalities. Our proposed FoleyGAN model is capable of conditioning action sequences of visual events leading towards generating visually aligned realistic sound tracks. We expand our previously proposed Automatic Foley dataset to train with FoleyGAN and evaluate our synthesized sound through human survey that shows noteworthy (on average 81\%) audio-visual synchronicity performance. Our approach also outperforms in statistical experiments compared with other baseline models and audio-visual datasets.
AutoFoley: Artificial Synthesis of Synchronized Sound Tracks for Silent Videos with Deep Learning
Feb 21, 2020

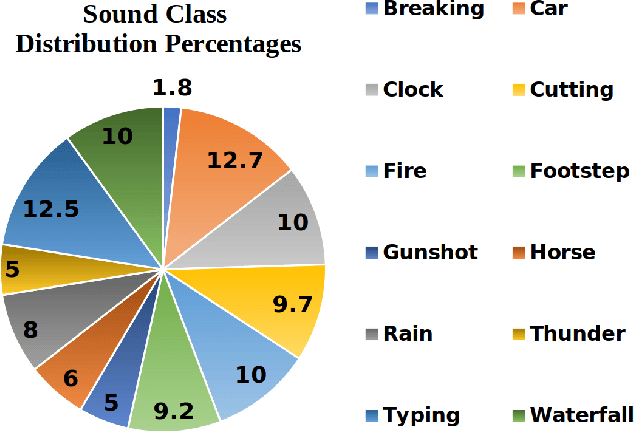
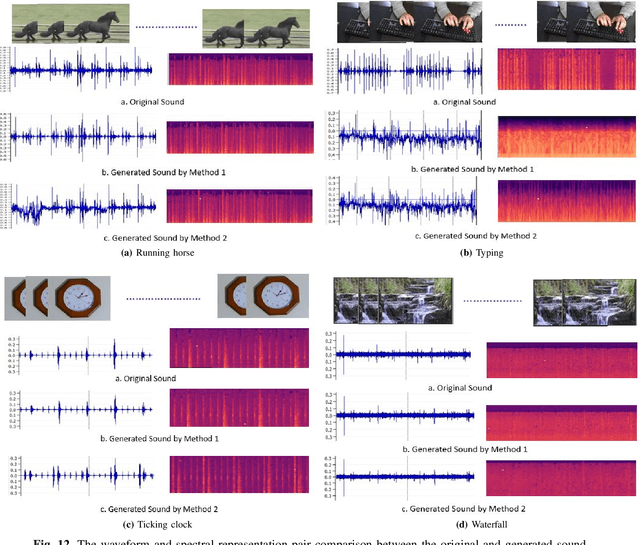
In movie productions, the Foley Artist is responsible for creating an overlay soundtrack that helps the movie come alive for the audience. This requires the artist to first identify the sounds that will enhance the experience for the listener thereby reinforcing the Directors's intention for a given scene. In this paper, we present AutoFoley, a fully-automated deep learning tool that can be used to synthesize a representative audio track for videos. AutoFoley can be used in the applications where there is either no corresponding audio file associated with the video or in cases where there is a need to identify critical scenarios and provide a synthesized, reinforced soundtrack. An important performance criterion of the synthesized soundtrack is to be time-synchronized with the input video, which provides for a realistic and believable portrayal of the synthesized sound. Unlike existing sound prediction and generation architectures, our algorithm is capable of precise recognition of actions as well as inter-frame relations in fast moving video clips by incorporating an interpolation technique and Temporal Relationship Networks (TRN). We employ a robust multi-scale Recurrent Neural Network (RNN) associated with a Convolutional Neural Network (CNN) for a better understanding of the intricate input-to-output associations over time. To evaluate AutoFoley, we create and introduce a large scale audio-video dataset containing a variety of sounds frequently used as Foley effects in movies. Our experiments show that the synthesized sounds are realistically portrayed with accurate temporal synchronization of the associated visual inputs. Human qualitative testing of AutoFoley show over 73% of the test subjects considered the generated soundtrack as original, which is a noteworthy improvement in cross-modal research in sound synthesis.