 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoleyGAN: Visually Guided Generative Adversarial Network-Based Synchronous Sound Generation in Silent Videos
Paper and Code
Jul 20, 2021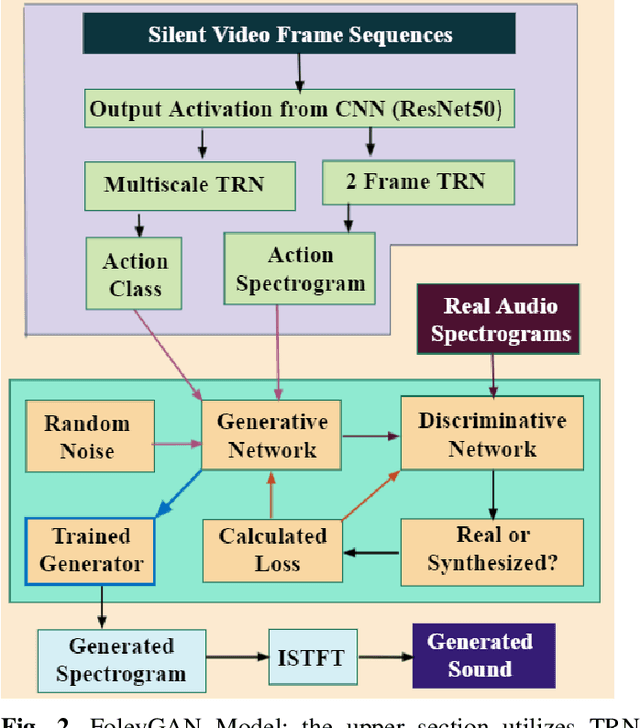
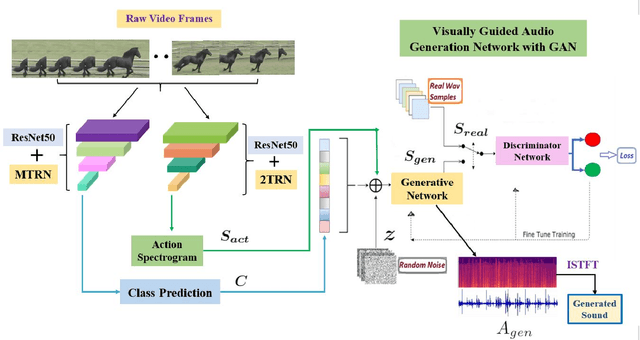
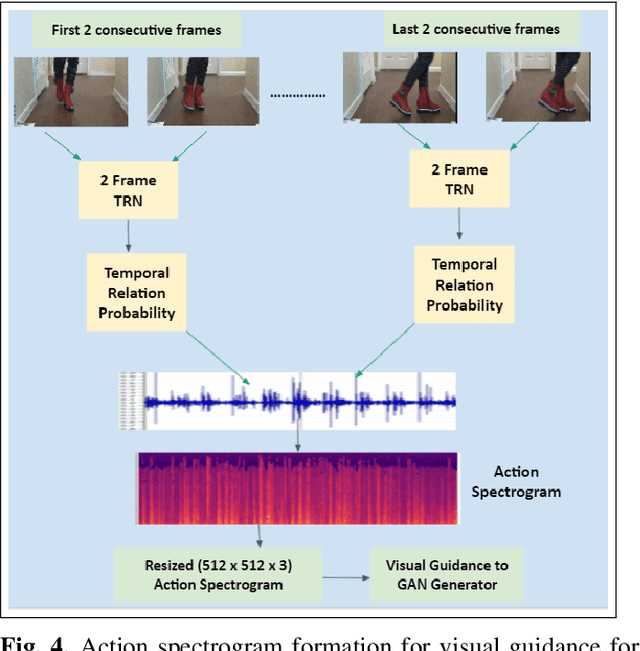
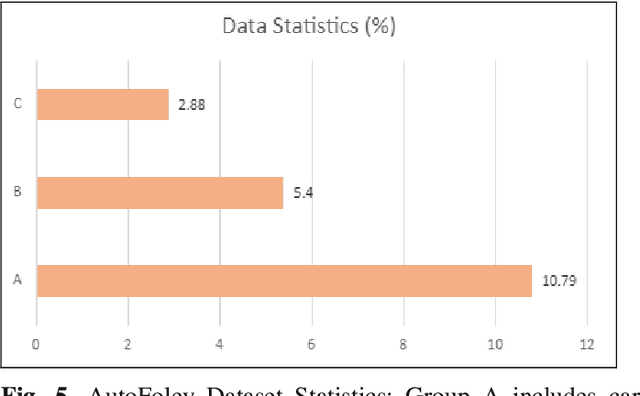
Deep learning based visual to sound generation systems essentially need to be developed particularly considering the synchronicity aspects of visual and audio features with time. In this research we introduce a novel task of guiding a class conditioned generative adversarial network with the temporal visual information of a video input for visual to sound generation task adapting the synchronicity traits between audio-visual modalities. Our proposed FoleyGAN model is capable of conditioning action sequences of visual events leading towards generating visually aligned realistic sound tracks. We expand our previously proposed Automatic Foley dataset to train with FoleyGAN and evaluate our synthesized sound through human survey that shows noteworthy (on average 81\%) audio-visual synchronicity performance. Our approach also outperforms in statistical experiments compared with other baseline models and audio-visual datasets.