 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoleyGAN: Visually Guided Generative Adversarial Network-Based Synchronous Sound Generation in Silent Videos
Jul 20, 2021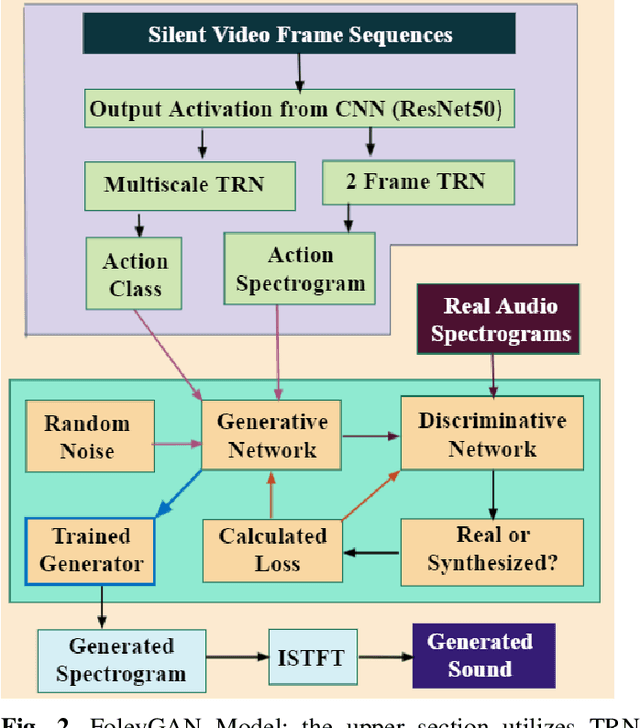
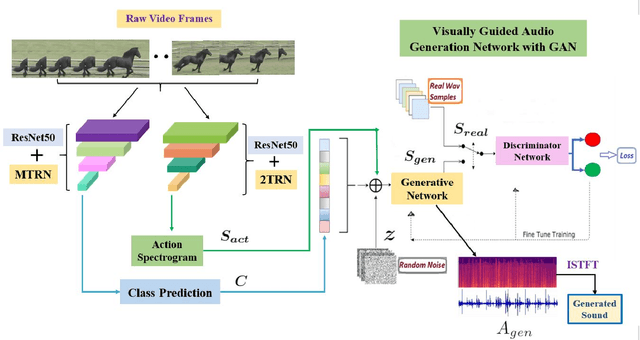
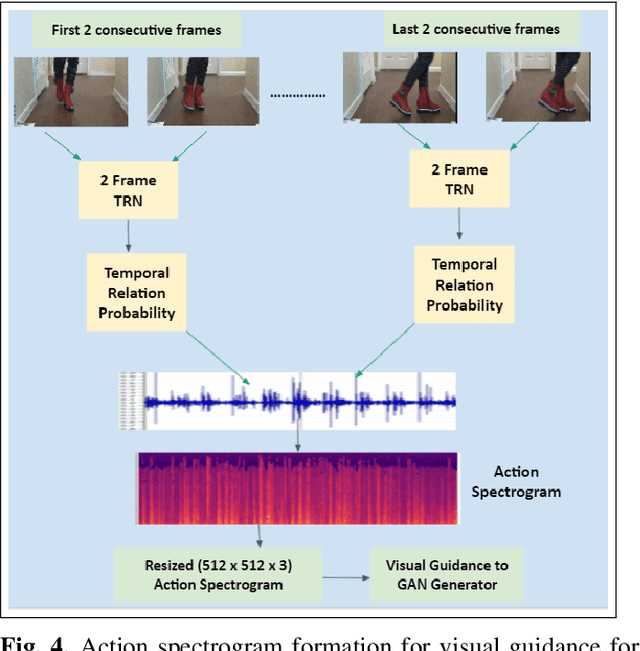
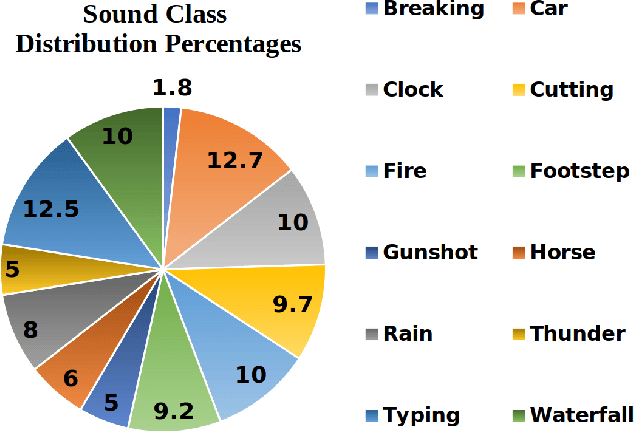
Deep learning based visual to sound generation systems essentially need to be developed particularly considering the synchronicity aspects of visual and audio features with time. In this research we introduce a novel task of guiding a class conditioned generative adversarial network with the temporal visual information of a video input for visual to sound generation task adapting the synchronicity traits between audio-visual modalities. Our proposed FoleyGAN model is capable of conditioning action sequences of visual events leading towards generating visually aligned realistic sound tracks. We expand our previously proposed Automatic Foley dataset to train with FoleyGAN and evaluate our synthesized sound through human survey that shows noteworthy (on average 81\%) audio-visual synchronicity performance. Our approach also outperforms in statistical experiments compared with other baseline models and audio-visual datasets.
AutoFoley: Artificial Synthesis of Synchronized Sound Tracks for Silent Videos with Deep Learning
Feb 21, 2020

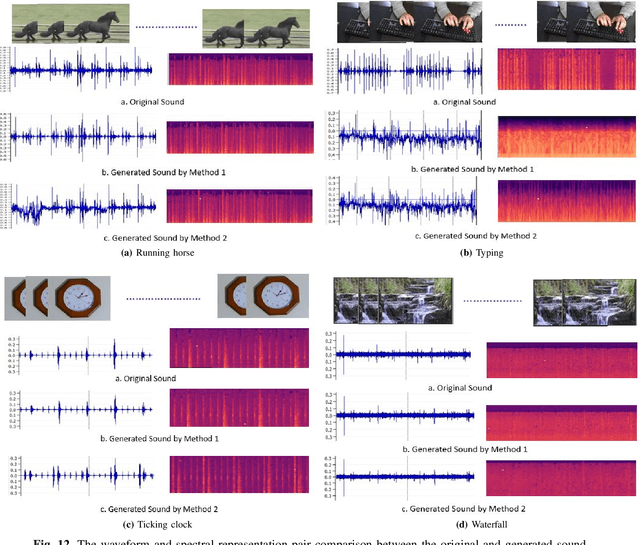
In movie productions, the Foley Artist is responsible for creating an overlay soundtrack that helps the movie come alive for the audience. This requires the artist to first identify the sounds that will enhance the experience for the listener thereby reinforcing the Directors's intention for a given scene. In this paper, we present AutoFoley, a fully-automated deep learning tool that can be used to synthesize a representative audio track for videos. AutoFoley can be used in the applications where there is either no corresponding audio file associated with the video or in cases where there is a need to identify critical scenarios and provide a synthesized, reinforced soundtrack. An important performance criterion of the synthesized soundtrack is to be time-synchronized with the input video, which provides for a realistic and believable portrayal of the synthesized sound. Unlike existing sound prediction and generation architectures, our algorithm is capable of precise recognition of actions as well as inter-frame relations in fast moving video clips by incorporating an interpolation technique and Temporal Relationship Networks (TRN). We employ a robust multi-scale Recurrent Neural Network (RNN) associated with a Convolutional Neural Network (CNN) for a better understanding of the intricate input-to-output associations over time. To evaluate AutoFoley, we create and introduce a large scale audio-video dataset containing a variety of sounds frequently used as Foley effects in movies. Our experiments show that the synthesized sounds are realistically portrayed with accurate temporal synchronization of the associated visual inputs. Human qualitative testing of AutoFoley show over 73% of the test subjects considered the generated soundtrack as original, which is a noteworthy improvement in cross-modal research in sound synthesis.