 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollecting high-quality adversarial data for machine reading comprehension tasks with humans and models in the loop
Jun 28, 2022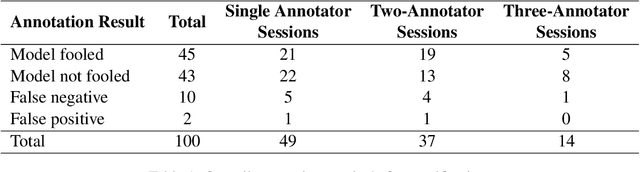



We present our experience as annotators in the creation of high-quality, adversarial machine-reading-comprehension data for extractive QA for Task 1 of the First Workshop on Dynamic Adversarial Data Collection (DADC). DADC is an emergent data collection paradigm with both models and humans in the loop. We set up a quasi-experimental annotation design and perform quantitative analyses across groups with different numbers of annotators focusing on successful adversarial attacks, cost analysis, and annotator confidence correlation. We further perform a qualitative analysis of our perceived difficulty of the task given the different topics of the passages in our dataset and conclude with recommendations and suggestions that might be of value to people working on future DADC tasks and related annotation interfaces.
ScienceExamCER: A High-Density Fine-Grained Science-Domain Corpus for Common Entity Recognition
Nov 24, 2019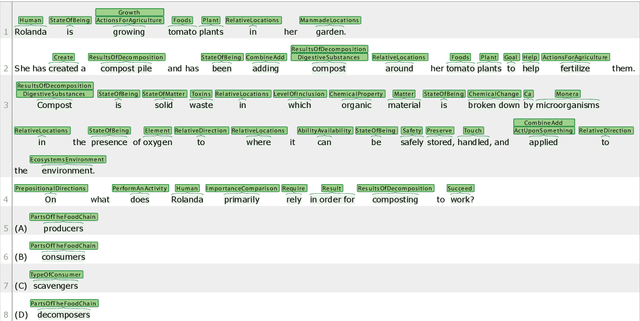
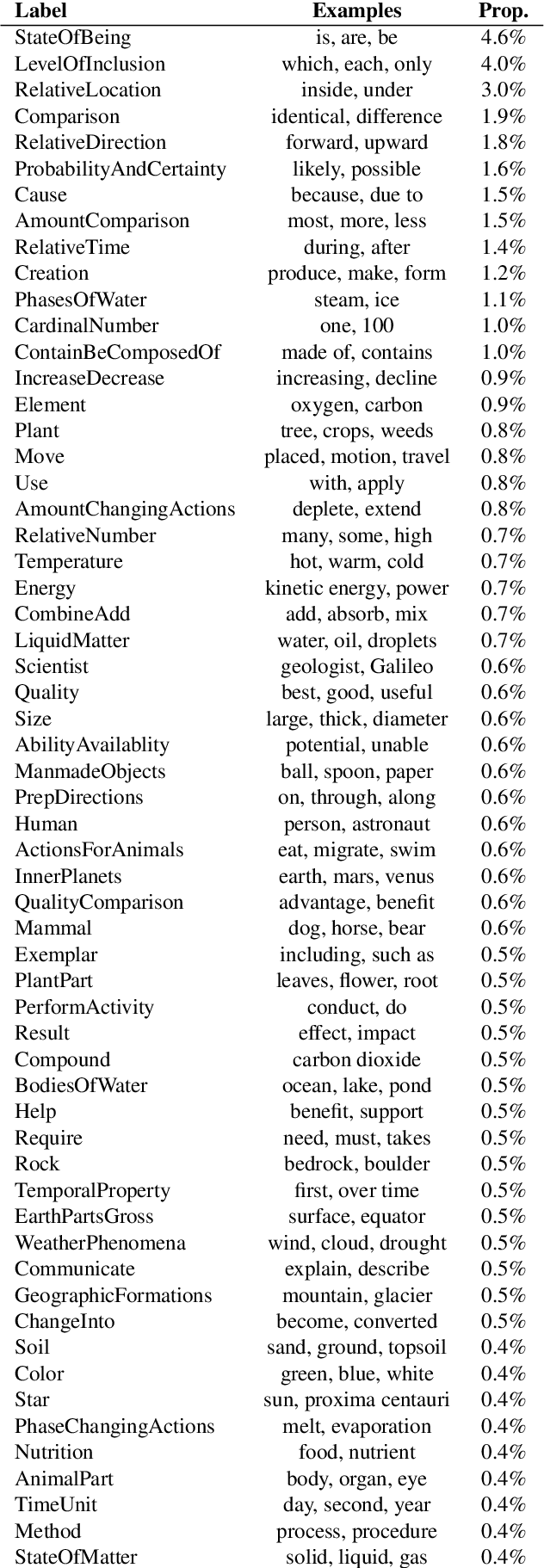
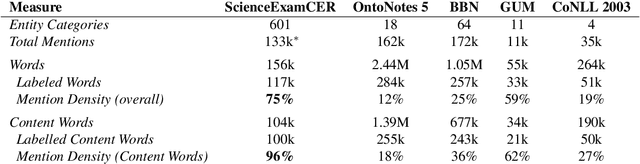
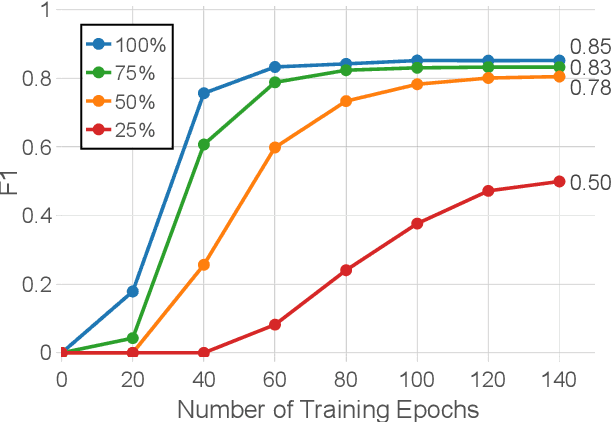
Named entity recognition identifies common classes of entities in text, but these entity labels are generally sparse, limiting utility to downstream tasks. In this work we present ScienceExamCER, a densely-labeled semantic classification corpus of 133k mentions in the science exam domain where nearly all (96%) of content words have been annotated with one or more fine-grained semantic class labels including taxonomic groups, meronym groups, verb/action groups, properties and values, and synonyms. Semantic class labels are drawn from a manually-constructed fine-grained typology of 601 classes generated through a data-driven analysis of 4,239 science exam questions. We show an off-the-shelf BERT-based named entity recognition model modified for multi-label classification achieves an accuracy of 0.85 F1 on this task, suggesting strong utility for downstream tasks in science domain question answering requiring densely-labeled semantic classification.