 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Sensitive Reinforcement Learning with Exponential Criteria
Dec 18, 2022



While risk-neutral reinforcement learning has shown experimental success in a number of applications, it is well-known to be non-robust with respect to noise and perturbations in the parameters of the system. For this reason, risk-sensitive reinforcement learning algorithms have been studied to introduce robustness and sample efficiency, and lead to better real-life performance. In this work, we introduce new model-free risk-sensitive reinforcement learning algorithms as variations of widely-used Policy Gradient algorithms with similar implementation properties. In particular, we study the effect of exponential criteria on the risk-sensitivity of the policy of a reinforcement learning agent, and develop variants of the Monte Carlo Policy Gradient algorithm and the online (temporal-difference) Actor-Critic algorithm. Analytical results showcase that the use of exponential criteria generalize commonly used ad-hoc regularization approaches. The implementation, performance, and robustness properties of the proposed methods are evaluated in simulated experiments.
Multi-Resolution Online Deterministic Annealing: A Hierarchical and Progressive Learning Architecture
Dec 15, 2022Hierarchical learning algorithms that gradually approximate a solution to a data-driven optimization problem are essential to decision-making systems, especially under limitations on time and computational resources. In this study, we introduce a general-purpose hierarchical learning architecture that is based on the progressive partitioning of a possibly multi-resolution data space. The optimal partition is gradually approximated by solving a sequence of optimization sub-problems that yield a sequence of partitions with increasing number of subsets. We show that the solution of each optimization problem can be estimated online using gradient-free stochastic approximation updates. As a consequence, a function approximation problem can be defined within each subset of the partition and solved using the theory of two-timescale stochastic approximation algorithms. This simulates an annealing process and defines a robust and interpretable heuristic method to gradually increase the complexity of the learning architecture in a task-agnostic manner, giving emphasis to regions of the data space that are considered more important according to a predefined criterion. Finally, by imposing a tree structure in the progression of the partitions, we provide a means to incorporate potential multi-resolution structure of the data space into this approach, significantly reducing its complexity, while introducing hierarchical feature extraction properties similar to certain classes of deep learning architectures. Asymptotic convergence analysis and experimental results are provided for clustering, classification, and regression problems.
Annealing Optimization for Progressive Learning with Stochastic Approximation
Sep 06, 2022
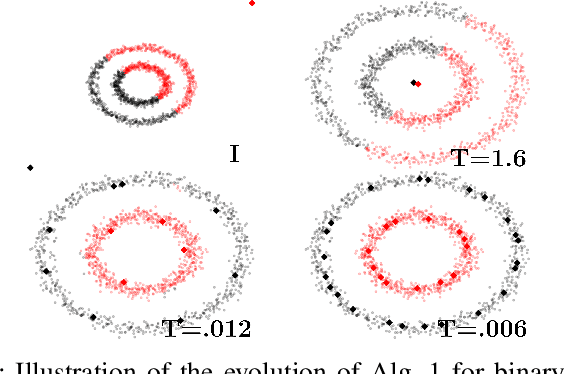
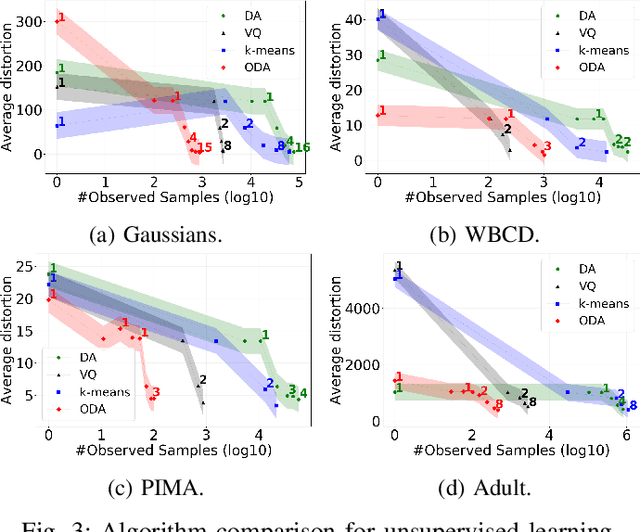
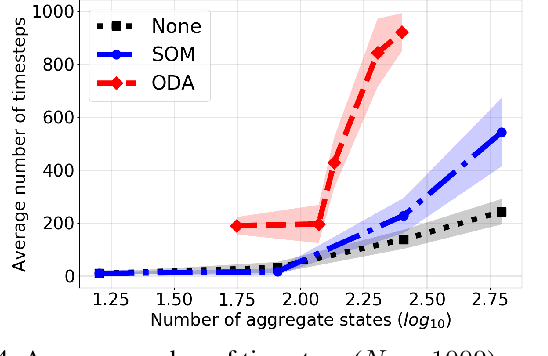
In this work, we introduce a learning model designed to meet the needs of applications in which computational resources are limited, and robustness and interpretability are prioritized. Learning problems can be formulated as constrained stochastic optimization problems, with the constraints originating mainly from model assumptions that define a trade-off between complexity and performance. This trade-off is closely related to over-fitting, generalization capacity, and robustness to noise and adversarial attacks, and depends on both the structure and complexity of the model, as well as the properties of the optimization methods used. We develop an online prototype-based learning algorithm based on annealing optimization that is formulated as an online gradient-free stochastic approximation algorithm. The learning model can be viewed as an interpretable and progressively growing competitive-learning neural network model to be used for supervised, unsupervised, and reinforcement learning. The annealing nature of the algorithm contributes to minimal hyper-parameter tuning requirements, poor local minima prevention, and robustness with respect to the initial conditions. At the same time, it provides online control over the performance-complexity trade-off by progressively increasing the complexity of the learning model as needed, through an intuitive bifurcation phenomenon. Finally, the use of stochastic approximation enables the study of the convergence of the learning algorithm through mathematical tools from dynamical systems and control, and allows for its integration with reinforcement learning algorithms, constructing an adaptive state-action aggregation scheme.
Learning Swarm Interaction Dynamics from Density Evolution
Dec 05, 2021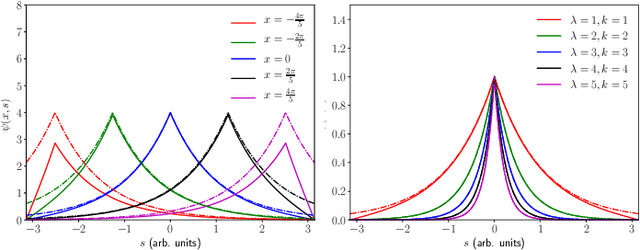

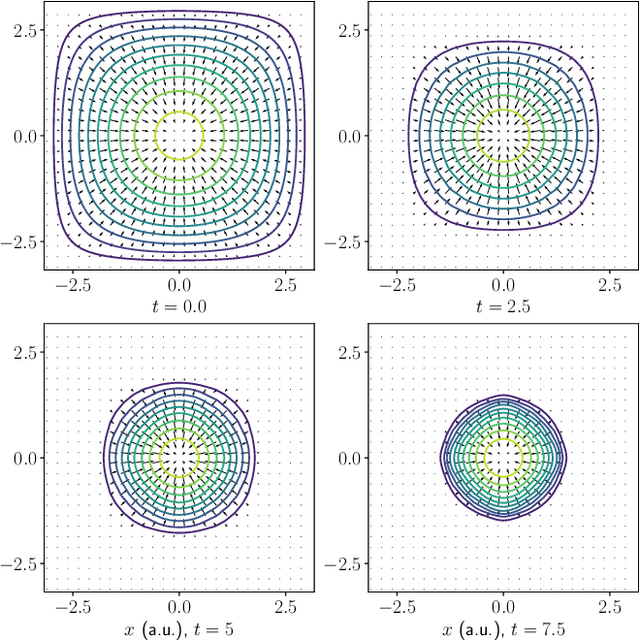

We consider the problem of understanding the coordinated movements of biological or artificial swarms. In this regard, we propose a learning scheme to estimate the coordination laws of the interacting agents from observations of the swarm's density over time. We describe the dynamics of the swarm based on pairwise interactions according to a Cucker-Smale flocking model, and express the swarm's density evolution as the solution to a system of mean-field hydrodynamic equations. We propose a new family of parametric functions to model the pairwise interactions, which allows for the mean-field macroscopic system of integro-differential equations to be efficiently solved as an augmented system of PDEs. Finally, we incorporate the augmented system in an iterative optimization scheme to learn the dynamics of the interacting agents from observations of the swarm's density evolution over time. The results of this work can offer an alternative approach to study how animal flocks coordinate, create new control schemes for large networked systems, and serve as a central part of defense mechanisms against adversarial drone attacks.
Towards the One Learning Algorithm Hypothesis: A System-theoretic Approach
Dec 04, 2021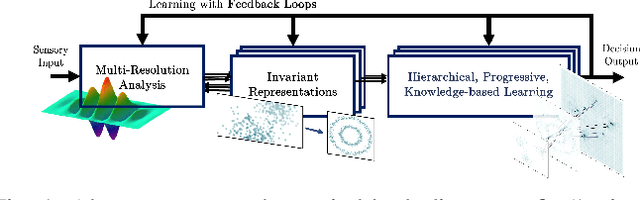
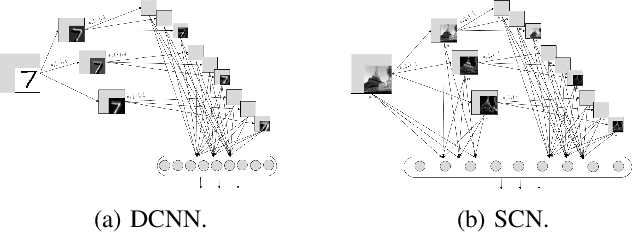
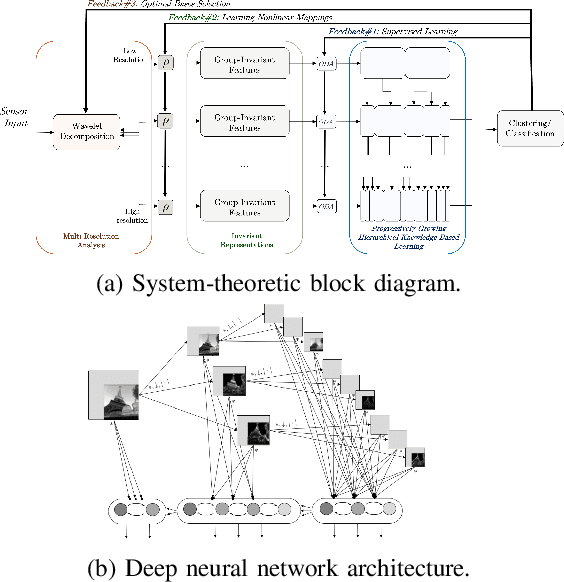
The existence of a universal learning architecture in human cognition is a widely spread conjecture supported by experimental findings from neuroscience. While no low-level implementation can be specified yet, an abstract outline of human perception and learning is believed to entail three basic properties: (a) hierarchical attention and processing, (b) memory-based knowledge representation, and (c) progressive learning and knowledge compaction. We approach the design of such a learning architecture from a system-theoretic viewpoint, developing a closed-loop system with three main components: (i) a multi-resolution analysis pre-processor, (ii) a group-invariant feature extractor, and (iii) a progressive knowledge-based learning module. Multi-resolution feedback loops are used for learning, i.e., for adapting the system parameters to online observations. To design (i) and (ii), we build upon the established theory of wavelet-based multi-resolution analysis and the properties of group convolution operators. Regarding (iii), we introduce a novel learning algorithm that constructs progressively growing knowledge representations in multiple resolutions. The proposed algorithm is an extension of the Online Deterministic Annealing (ODA) algorithm based on annealing optimization, solved using gradient-free stochastic approximation. ODA has inherent robustness and regularization properties and provides a means to progressively increase the complexity of the learning model i.e. the number of the neurons, as needed, through an intuitive bifurcation phenomenon. The proposed multi-resolution approach is hierarchical, progressive, knowledge-based, and interpretable. We illustrate the properties of the proposed architecture in the context of the state-of-the-art learning algorithms and deep learning methods.
Online Deterministic Annealing for Classification and Clustering
Feb 11, 2021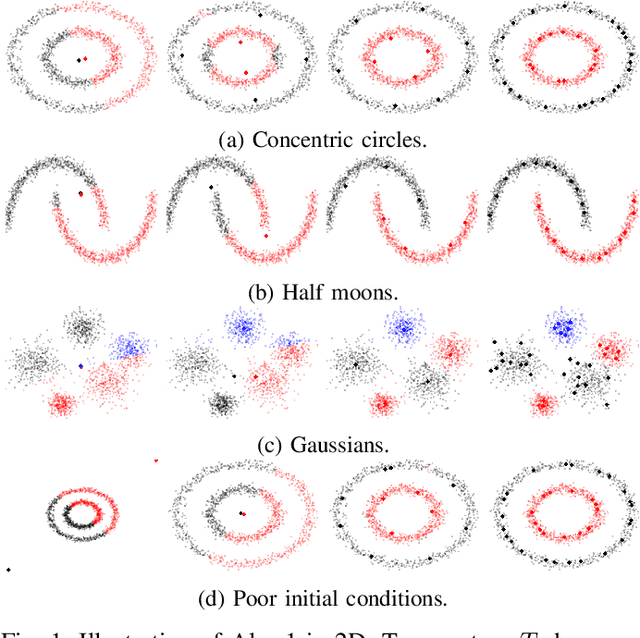
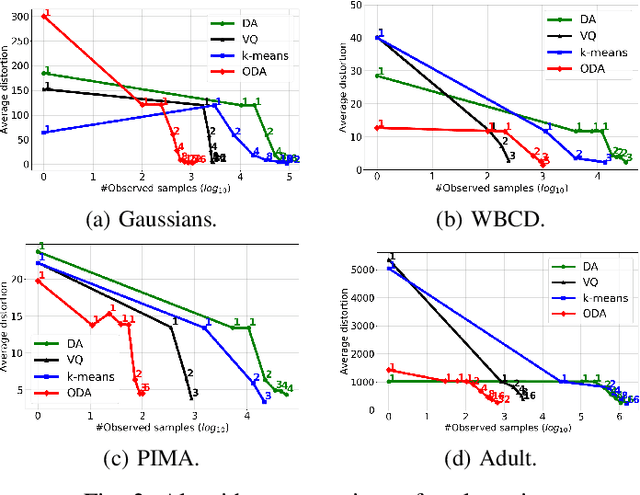
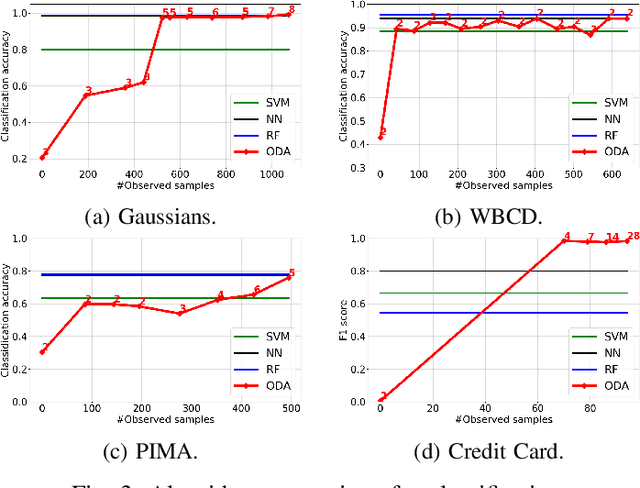
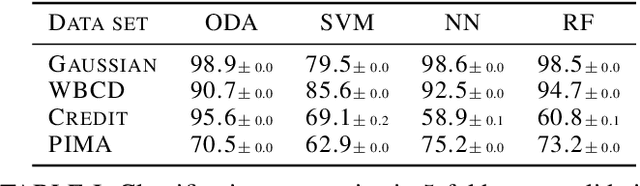
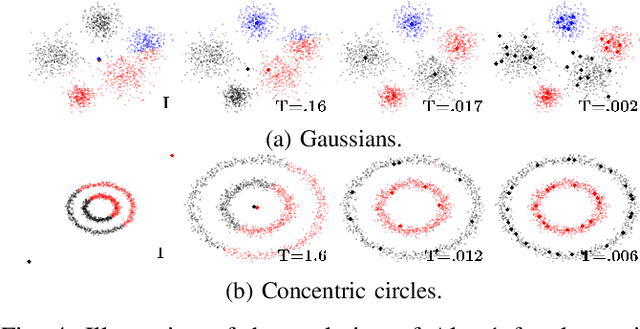
We introduce an online prototype-based learning algorithm for clustering and classification, based on the principles of deterministic annealing. We show that the proposed algorithm constitutes a competitive-learning neural network, the learning rule of which is formulated as an online stochastic approximation algorithm. The annealing nature of the algorithm prevents poor local minima, offers robustness with respect to the initial conditions, and provides a means to progressively increase the complexity of the learning model as needed, through an intuitive bifurcation phenomenon. As a result, the proposed approach is interpretable, requires minimal hyper-parameter tuning, and offers online control over the complexity-accuracy trade-off. Finally, Bregman divergences are used as a family of dissimilarity measures that are shown to play an important role in both the performance of the algorithm, and its computational complexity. We illustrate the properties and evaluate the performance of the proposed learning algorithm in artificial and real datasets.
Reliable Attribute-Based Object Recognition Using High Predictive Value Classifiers
Oct 24, 2016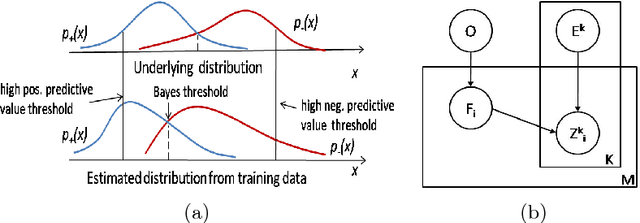
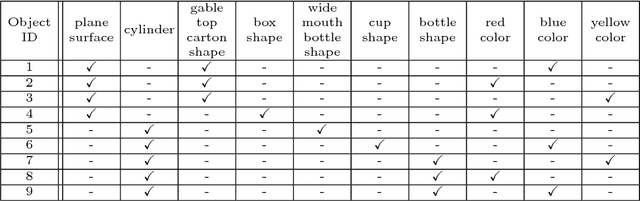

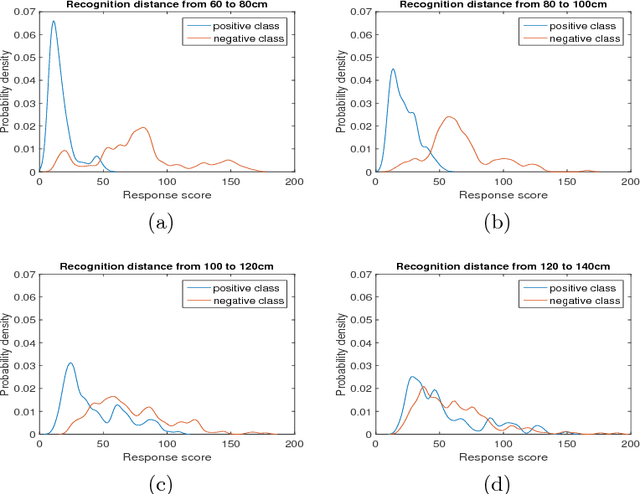
We consider the problem of object recognition in 3D using an ensemble of attribute-based classifiers. We propose two new concepts to improve classification in practical situations, and show their implementation in an approach implemented for recognition from point-cloud data. First, the viewing conditions can have a strong influence on classification performance. We study the impact of the distance between the camera and the object and propose an approach to fuse multiple attribute classifiers, which incorporates distance into the decision making. Second, lack of representative training samples often makes it difficult to learn the optimal threshold value for best positive and negative detection rate. We address this issue, by setting in our attribute classifiers instead of just one threshold value, two threshold values to distinguish a positive, a negative and an uncertainty class, and we prove the theoretical correctness of this approach. Empirical studies demonstrate the effectiveness and feasibility of the proposed concepts.