 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarity and Intensity: the Two Aspects of Sentiment Analysis
Jul 04, 2018



Current multimodal sentiment analysis frames sentiment score prediction as a general Machine Learning task. However, what the sentiment score actually represents has often been overlooked. As a measurement of opinions and affective states, a sentiment score generally consists of two aspects: polarity and intensity. We decompose sentiment scores into these two aspects and study how they are conveyed through individual modalities and combined multimodal models in a naturalistic monologue setting. In particular, we build unimodal and multimodal multi-task learning models with sentiment score prediction as the main task and polarity and/or intensity classification as the auxiliary tasks. Our experiments show that sentiment analysis benefits from multi-task learning, and individual modalities differ when conveying the polarity and intensity aspects of sentiment.
An Empirical Investigation of Proposals in Collaborative Dialogues
Jun 25, 1998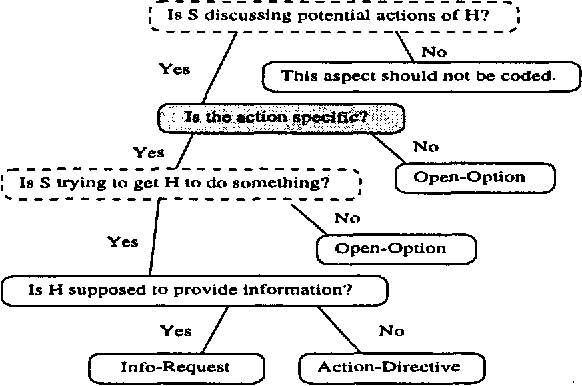
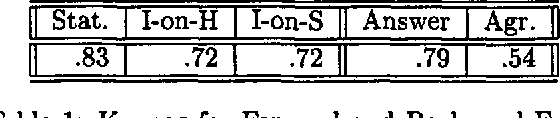
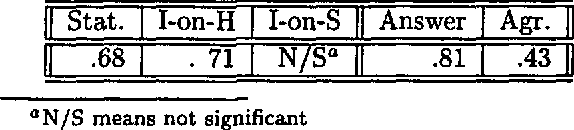
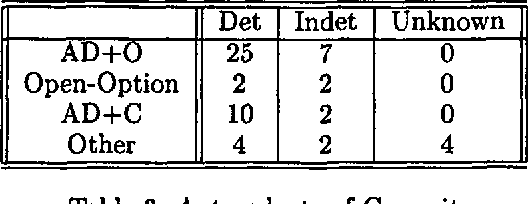
We describe a corpus-based investigation of proposals in dialogue. First, we describe our DRI compliant coding scheme and report our inter-coder reliability results. Next, we test several hypotheses about what constitutes a well-formed proposal.
* 5 pages, colacl.sty, formulas.sty
Learning Features that Predict Cue Usage
Oct 22, 1997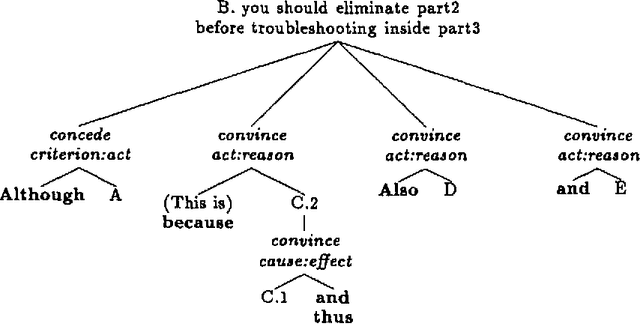
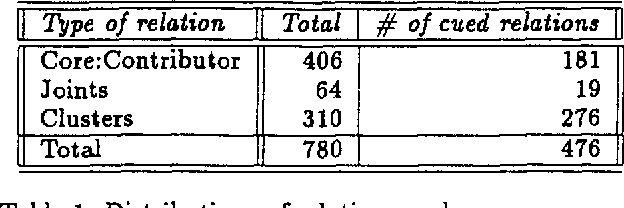

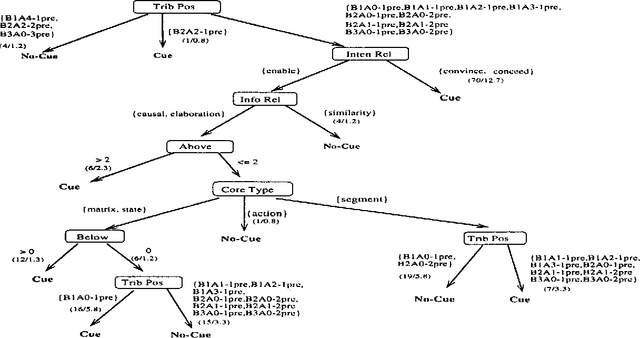
Our goal is to identify the features that predict the occurrence and placement of discourse cues in tutorial explanations in order to aid in the automatic generation of explanations. Previous attempts to devise rules for text generation were based on intuition or small numbers of constructed examples. We apply a machine learning program, C4.5, to induce decision trees for cue occurrence and placement from a corpus of data coded for a variety of features previously thought to affect cue usage. Our experiments enable us to identify the features with most predictive power, and show that machine learning can be used to induce decision trees useful for text generation.
* 10 pages, 2 Postscript figures, uses aclap.sty, psfig.tex
DPOCL: A Principled Approach to Discourse Planning
Jun 10, 1994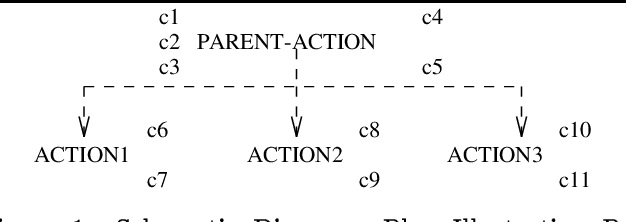
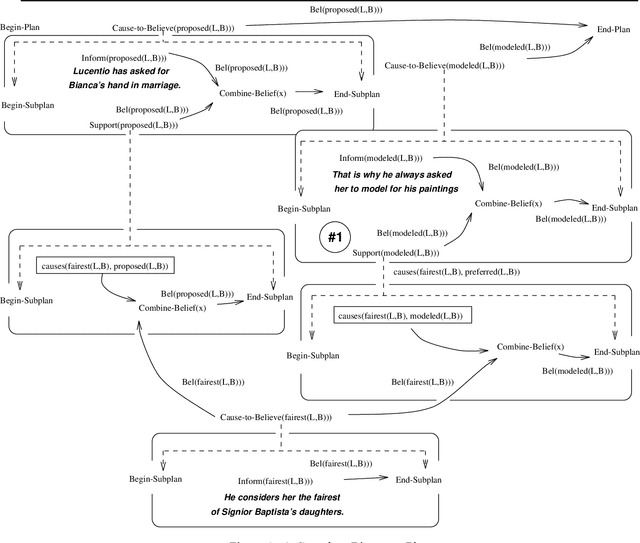

Research in discourse processing has identified two representational requirements for discourse planning systems. First, discourse plans must adequately represent the intentional structure of the utterances they produce in order to enable a computational discourse agent to respond effectively to communicative failures \cite{MooreParisCL}. Second, discourse plans must represent the informational structure of utterances. In addition to these representational requirements, we argue that discourse planners should be formally characterizable in terms of soundness and completeness.
Towards a Principled Representation of Discourse Plans
Jun 01, 1994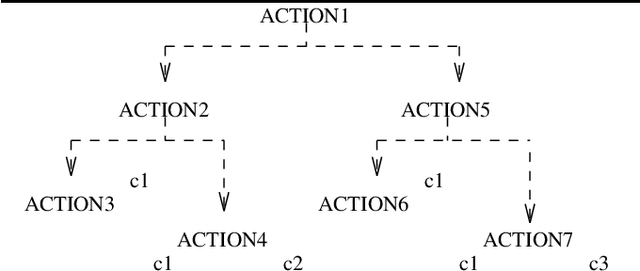
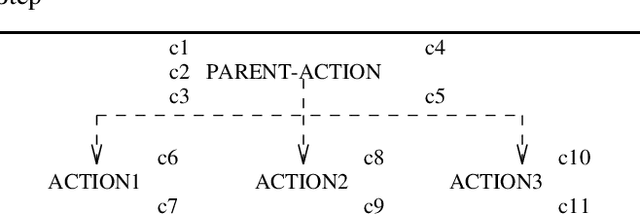
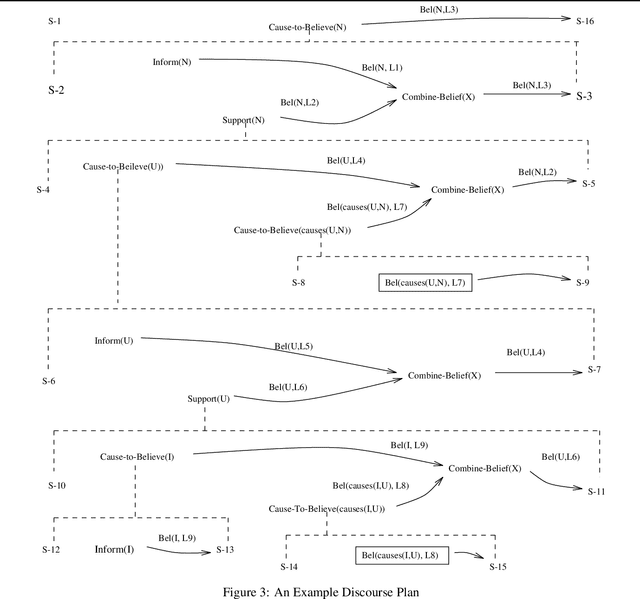
We argue that discourse plans must capture the intended causal and decompositional relations between communicative actions. We present a planning algorithm, DPOCL, that builds plan structures that properly capture these relations, and show how these structures are used to solve the problems that plagued previous discourse planners, and allow a system to participate effectively and flexibly in an ongoing dialogue.
* requires cogsci94.sty, psfig.sty