 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Training using Tensor Decomposition
Sep 10, 2019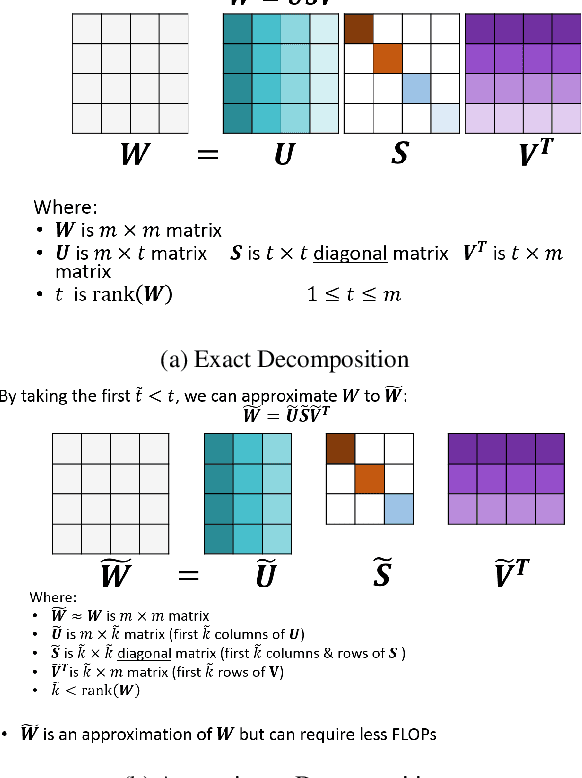
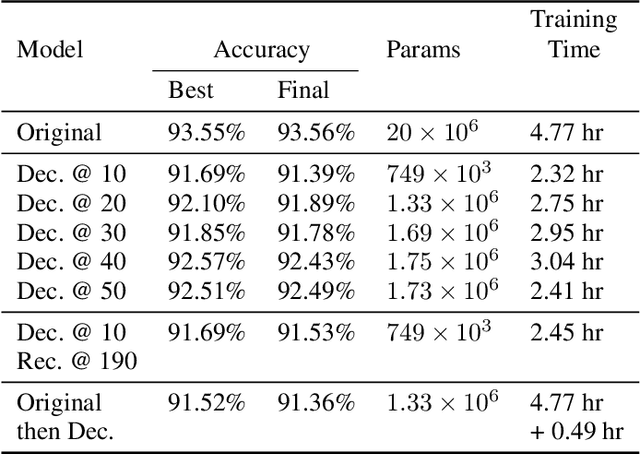

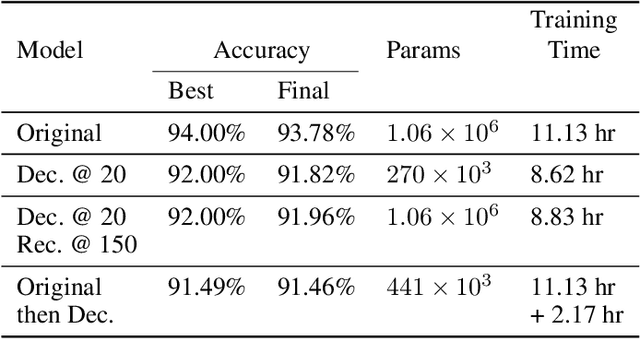
Tensor decomposition is one of the well-known approaches to reduce the latency time and number of parameters of a pre-trained model. However, in this paper, we propose an approach to use tensor decomposition to reduce training time of training a model from scratch. In our approach, we train the model from scratch (i.e., randomly initialized weights) with its original architecture for a small number of epochs, then the model is decomposed, and then continue training the decomposed model till the end. There is an optional step in our approach to convert the decomposed architecture back to the original architecture. We present results of using this approach on both CIFAR10 and Imagenet datasets, and show that there can be upto 2x speed up in training time with accuracy drop of upto 1.5% only, and in other cases no accuracy drop. This training acceleration approach is independent of hardware and is expected to have similar speed ups on both CPU and GPU platforms.
DeepShift: Towards Multiplication-Less Neural Networks
Jun 06, 2019
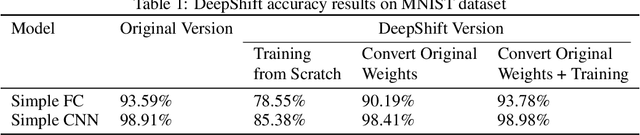


Deep learning models, especially DCNN have obtained high accuracies in several computer vision applications. However, for deployment in mobile environments, the high computation and power budget proves to be a major bottleneck. Convolution layers and fully connected layers, because of their intense use of multiplications, are the dominant contributer to this computation budget. This paper, proposes to tackle this problem by introducing two new operations: convolutional shifts and fully-connected shifts, that replace multiplications all together and use bitwise shift and bitwise negation instead. This family of neural network architectures (that use convolutional shifts and fully-connected shifts) are referred to as DeepShift models. With such DeepShift models that can be implemented with no multiplications, the authors have obtained accuracies of up to 93.6% on CIFAR10 dataset, and Top-1/Top-5 accuracies of 70.9%/90.13% on Imagenet dataset. Extensive testing is made on various well-known CNN architectures after converting all their convolution layers and fully connected layers to their bitwise shift counterparts, and we show that in some architectures, the Top-1 accuracy drops by less than 4% and the Top-5 accuracy drops by less than 1.5%. The experiments have been conducted on PyTorch framework and the code for training and running is submitted along with the paper and will be made available online.