 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Language Models using JAX pjit and TPUv4
Apr 13, 2022
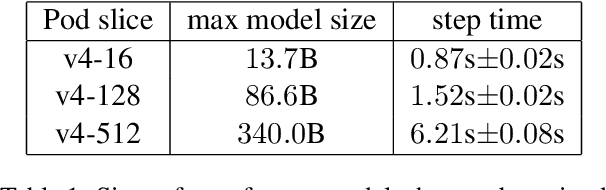
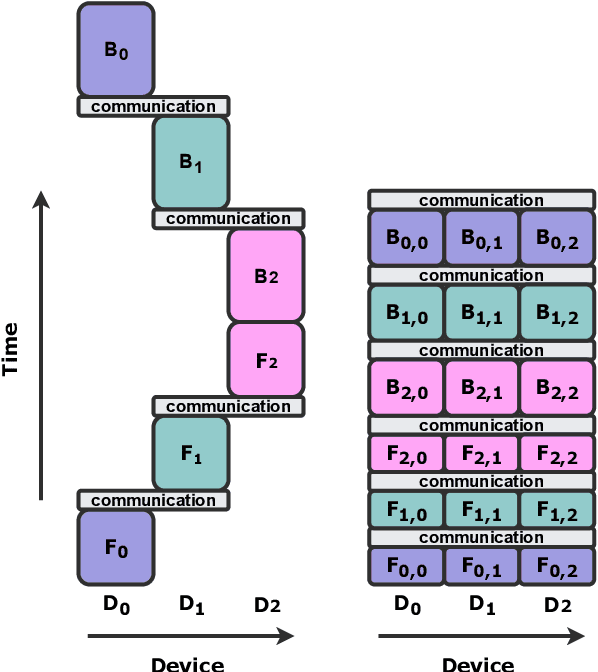
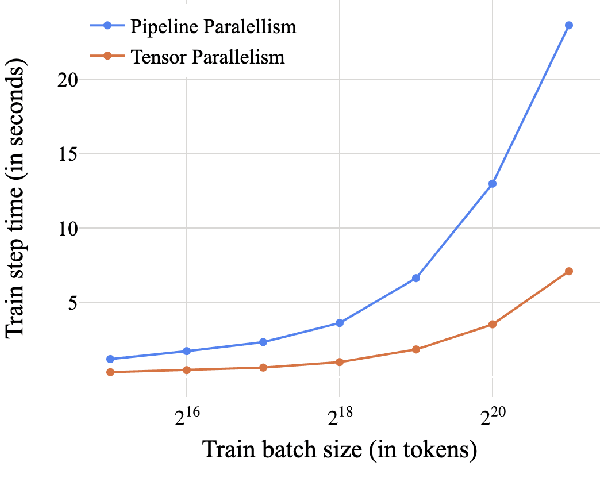
Modern large language models require distributed training strategies due to their size. The challenges of efficiently and robustly training them are met with rapid developments on both software and hardware frontiers. In this technical report, we explore challenges and design decisions associated with developing a scalable training framework, and present a quantitative analysis of efficiency improvements coming from adopting new software and hardware solutions.
SliceOut: Training Transformers and CNNs faster while using less memory
Jul 21, 2020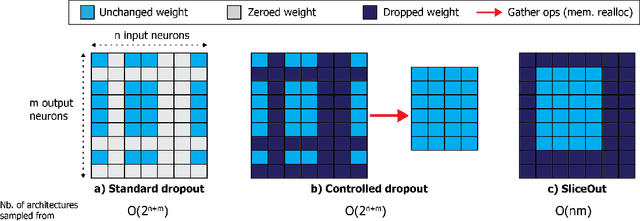
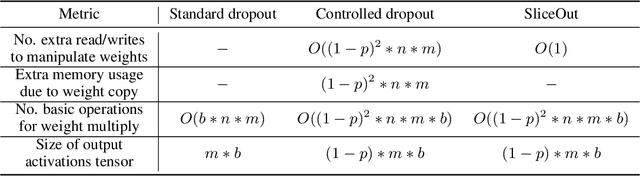
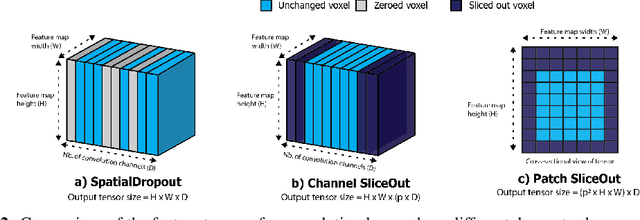
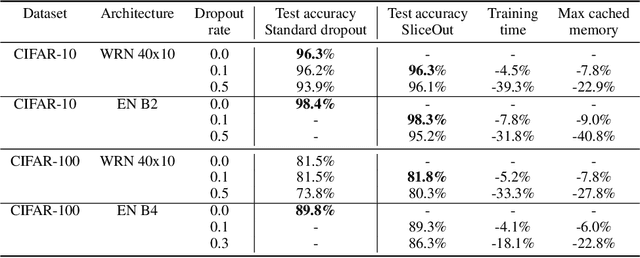
We demonstrate 10-40% speedups and memory reduction with Wide ResNets, EfficientNets, and Transformer models, with minimal to no loss in accuracy, using SliceOut---a new dropout scheme designed to take advantage of GPU memory layout. By dropping contiguous sets of units at random, our method preserves the regularization properties of dropout while allowing for more efficient low-level implementation, resulting in training speedups through (1) fast memory access and matrix multiplication of smaller tensors, and (2) memory savings by avoiding allocating memory to zero units in weight gradients and activations. Despite its simplicity, our method is highly effective. We demonstrate its efficacy at scale with Wide ResNets & EfficientNets on CIFAR10/100 and ImageNet, as well as Transformers on the LM1B dataset. These speedups and memory savings in training can lead to $CO_2$ emissions reduction of up to 40% for training large models.