 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Planning with Transformers for Vision-and-Language Navigation
Dec 09, 2020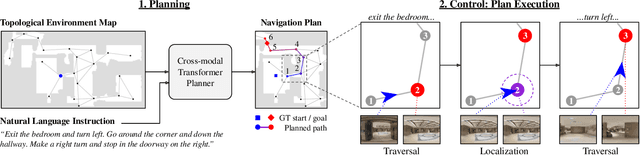
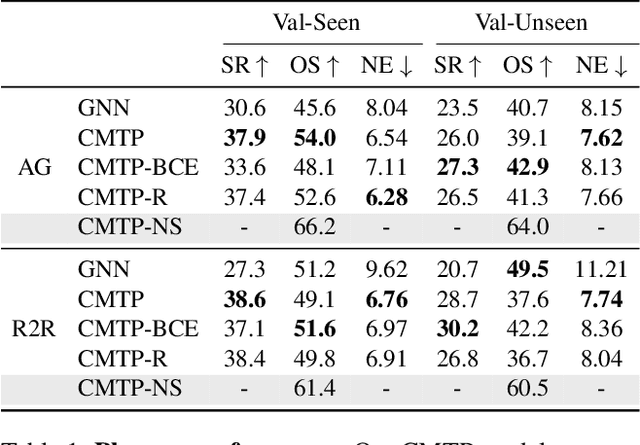
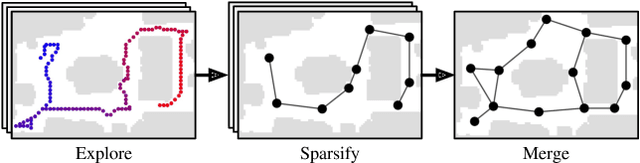

Conventional approaches to vision-and-language navigation (VLN) are trained end-to-end but struggle to perform well in freely traversable environments. Inspired by the robotics community, we propose a modular approach to VLN using topological maps. Given a natural language instruction and topological map, our approach leverages attention mechanisms to predict a navigation plan in the map. The plan is then executed with low-level actions (e.g. forward, rotate) using a robust controller. Experiments show that our method outperforms previous end-to-end approaches, generates interpretable navigation plans, and exhibits intelligent behaviors such as backtracking.
JIT-Masker: Efficient Online Distillation for Background Matting
Jun 11, 2020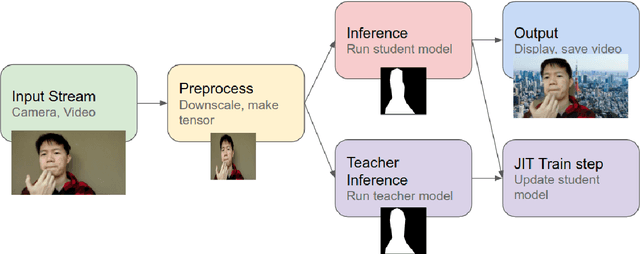
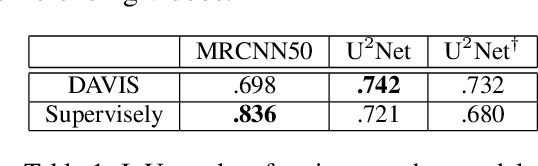
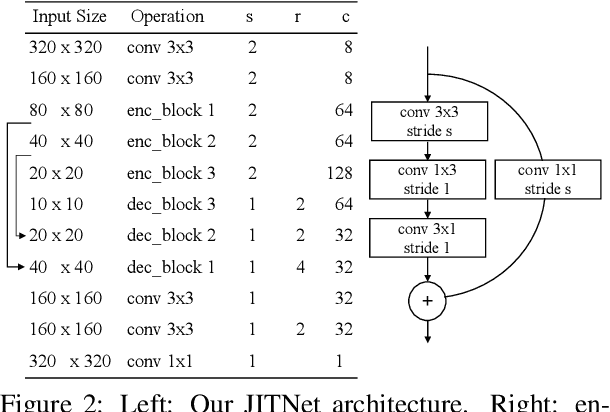
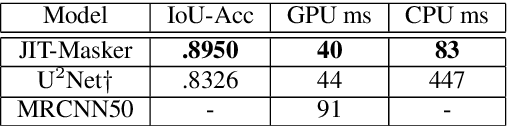
We design a real-time portrait matting pipeline for everyday use, particularly for "virtual backgrounds" in video conferences. Existing segmentation and matting methods prioritize accuracy and quality over throughput and efficiency, and our pipeline enables trading off a controllable amount of accuracy for better throughput by leveraging online distillation on the input video stream. We construct our own dataset of simulated video calls in various scenarios, and show that our approach delivers a 5x speedup over a saliency detection based pipeline in a non-GPU accelerated setting while delivering higher quality results. We demonstrate that an online distillation approach can feasibly work as part of a general, consumer level product as a "virtual background" tool. Our public implementation is at https://github.com/josephch405/jit-masker.