 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Sampling: A Metric-guided Subgraph Learning Framework for Graph Neural Network
Dec 30, 2021
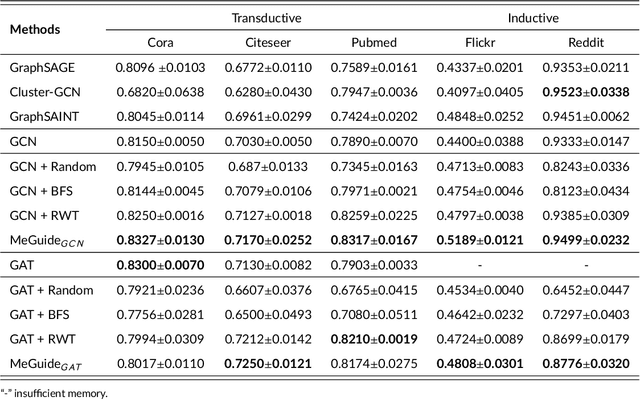


Graph neural network (GNN) has shown convincing performance in learning powerful node representations that preserve both node attributes and graph structural information. However, many GNNs encounter problems in effectiveness and efficiency when they are designed with a deeper network structure or handle large-sized graphs. Several sampling algorithms have been proposed for improving and accelerating the training of GNNs, yet they ignore understanding the source of GNN performance gain. The measurement of information within graph data can help the sampling algorithms to keep high-value information while removing redundant information and even noise. In this paper, we propose a Metric-Guided (MeGuide) subgraph learning framework for GNNs. MeGuide employs two novel metrics: Feature Smoothness and Connection Failure Distance to guide the subgraph sampling and mini-batch based training. Feature Smoothness is designed for analyzing the feature of nodes in order to retain the most valuable information, while Connection Failure Distance can measure the structural information to control the size of subgraphs. We demonstrate the effectiveness and efficiency of MeGuide in training various GNNs on multiple datasets.
Label Contrastive Coding based Graph Neural Network for Graph Classification
Jan 14, 2021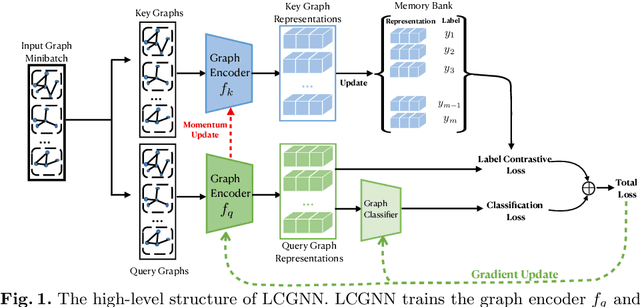


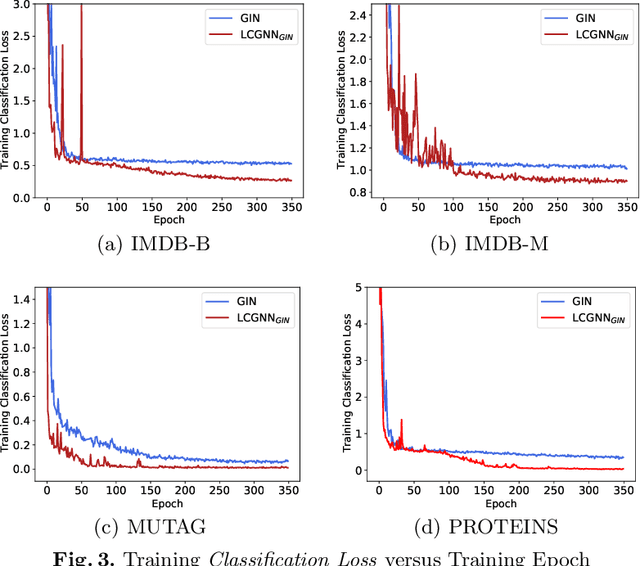
Graph classification is a critical research problem in many applications from different domains. In order to learn a graph classification model, the most widely used supervision component is an output layer together with classification loss (e.g.,cross-entropy loss together with softmax or margin loss). In fact, the discriminative information among instances are more fine-grained, which can benefit graph classification tasks. In this paper, we propose the novel Label Contrastive Coding based Graph Neural Network (LCGNN) to utilize label information more effectively and comprehensively. LCGNN still uses the classification loss to ensure the discriminability of classes. Meanwhile, LCGNN leverages the proposed Label Contrastive Loss derived from self-supervised learning to encourage instance-level intra-class compactness and inter-class separability. To power the contrastive learning, LCGNN introduces a dynamic label memory bank and a momentum updated encoder. Our extensive evaluations with eight benchmark graph datasets demonstrate that LCGNN can outperform state-of-the-art graph classification models. Experimental results also verify that LCGNN can achieve competitive performance with less training data because LCGNN exploits label information comprehensively.
Ripple Walk Training: A Subgraph-based training framework for Large and Deep Graph Neural Network
Mar 05, 2020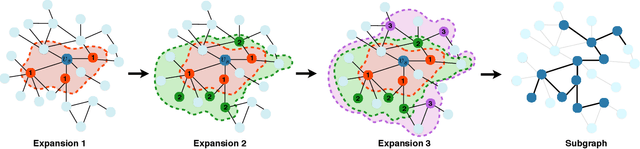
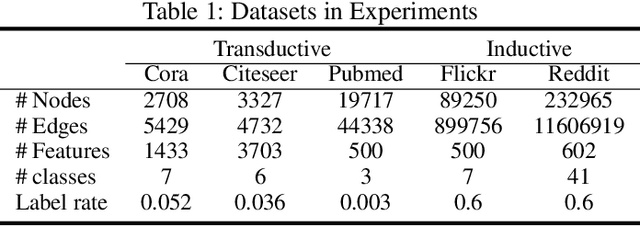
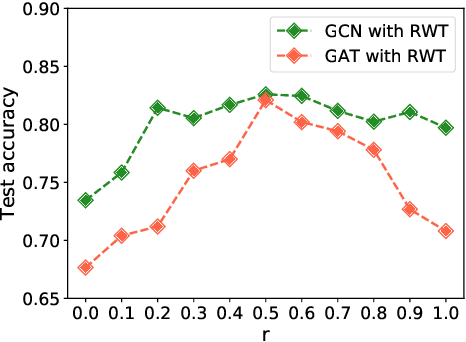
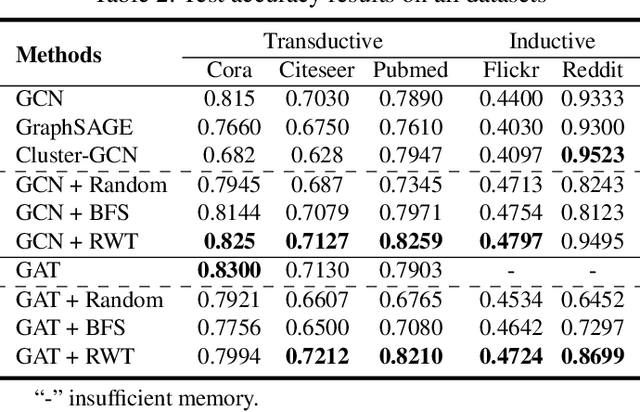
Graph neural networks (GNNs) have achieved outstanding performance in learning graph-structured data. Many current GNNs suffer from three problems when facing large-size graphs and using a deeper structure: neighbors explosion, node dependence, and oversmoothing. In this paper, we propose a general subgraph-based training framework, namely Ripple Walk Training (RWT), for deep and large graph neural networks. RWT samples subgraphs from the full graph to constitute a mini-batch and the full GNN is updated based on the mini-batch gradient. We analyze the high-quality subgraphs required in a mini-batch in a theoretical way. A novel sampling method Ripple Walk Sampler works for sampling these high-quality subgraphs to constitute the mini-batch, which considers both the randomness and connectivity of the graph-structured data. Extensive experiments on different sizes of graphs demonstrate the effectiveness of RWT in training various GNNs (GCN & GAT).
BGADAM: Boosting based Genetic-Evolutionary ADAM for Convolutional Neural Network Optimization
Jul 26, 2019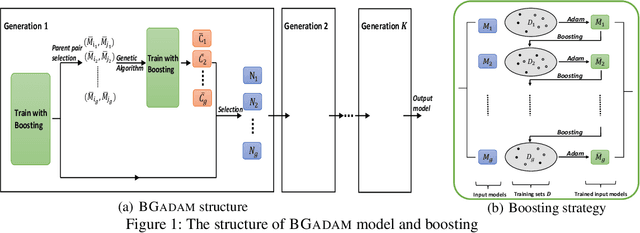



Among various optimization algorithms, ADAM can achieve outstanding performance and has been widely used in model learning. ADAM has the advantages of fast convergence with both momentum and adaptive learning rate. For deep neural network learning problems, since their objective functions are nonconvex, ADAM can also get stuck in local optima easily. To resolve such a problem, the genetic evolutionary ADAM (GADAM) algorithm, which combines the ADAM and genetic algorithm, was introduced in recent years. To further maximize the advantages of the GADAM model, we propose to implement the boosting strategy for unit model training in GADAM. In this paper, we introduce a novel optimization algorithm, namely Boosting based GADAM (BGADAM). We will show that after adding the boosting strategy to the GADAM model, it can help unit models jump out the local optima and converge to better solutions.
DEAM: Accumulated Momentum with Discriminative Weight for Stochastic Optimization
Jul 25, 2019
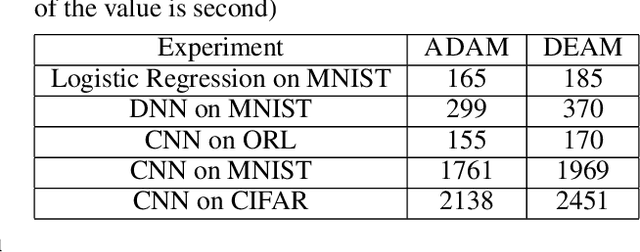
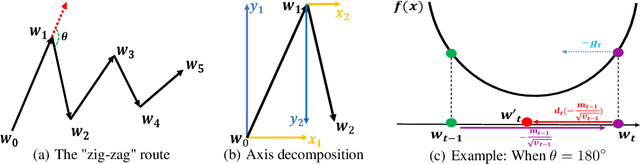

Optimization algorithms with momentum, e.g., Nesterov Accelerated Gradient and ADAM, have been widely used for building deep learning models because of their faster convergence rates compared to stochastic gradient descent (SGD). Momentum is a method that helps accelerate SGD in the relevant directions in variable updating, which can minify the oscillations of variables update route. Optimization algorithms with momentum usually allocate a fixed hyperparameter (e.g., \beta_1) as the weight of the momentum term. However, using a fixed weight is not applicable to some situations, and such a hyper-parameter can be extremely hard to tune in applications. In this paper, we will introduce a new optimization algorithm, namely DEAM (Discriminative wEight on Accumulated Momentum). Instead of assigning the momentum term with a fixed weight, DEAM proposes to compute the momentum weight in the learning process automatically. DEAM also involves a "backtrack" term, which can help accelerate the algorithm convergence by restricting redundant updates. Extensive experiments have been done on several real-world datasets. The experimental results demonstrate that DEAM can achieve a faster convergence rate than the existing optimization algorithms in training both the classic machine learning models and the recent deep learning models.