 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Reference Loss for Unsupervised Domain Adaptation
Dec 05, 2017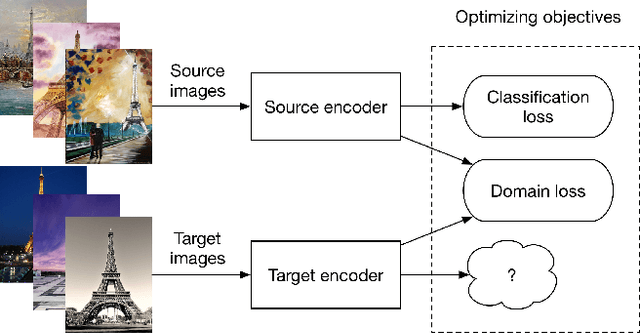
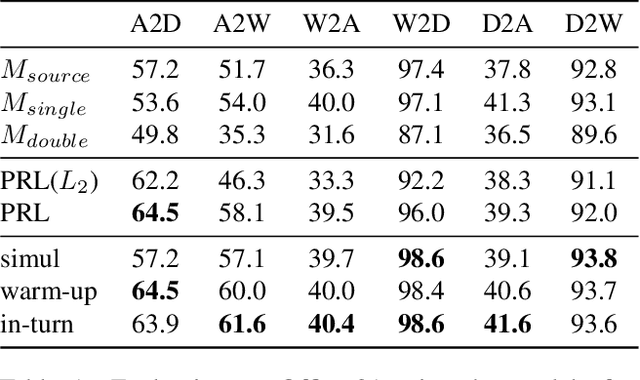

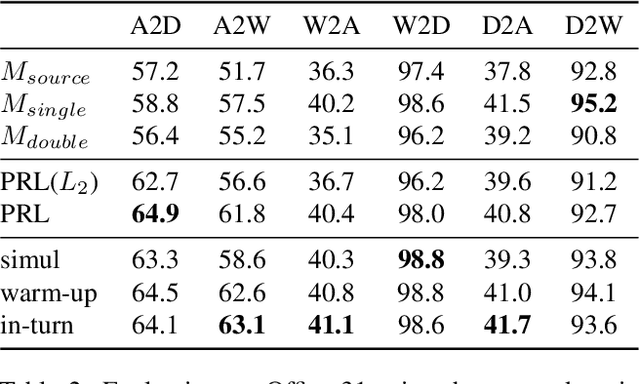
The success of deep learning in computer vision is mainly attributed to an abundance of data. However, collecting large-scale data is not always possible, especially for the supervised labels. Unsupervised domain adaptation (UDA) aims to utilize labeled data from a source domain to learn a model that generalizes to a target domain of unlabeled data. A large amount of existing work uses Siamese network-based models, where two streams of neural networks process the source and the target domain data respectively. Nevertheless, most of these approaches focus on minimizing the domain discrepancy, overlooking the importance of preserving the discriminative ability for target domain features. Another important problem in UDA research is how to evaluate the methods properly. Common evaluation procedures require target domain labels for hyper-parameter tuning and model selection, contradicting the definition of the UDA task. Hence we propose a more reasonable evaluation principle that avoids this contradiction by simply adopting the latest snapshot of a model for evaluation. This adds an extra requirement for UDA methods besides the main performance criteria: the stability during training. We design a novel method that connects the target domain stream to the source domain stream with a Parameter Reference Loss (PRL) to solve these problems simultaneously. Experiments on various datasets show that the proposed PRL not only improves the performance on the target domain, but also stabilizes the training procedure. As a result, PRL based models do not need the contradictory model selection, and thus are more suitable for practical applications.
Annotation Order Matters: Recurrent Image Annotator for Arbitrary Length Image Tagging
Dec 07, 2016
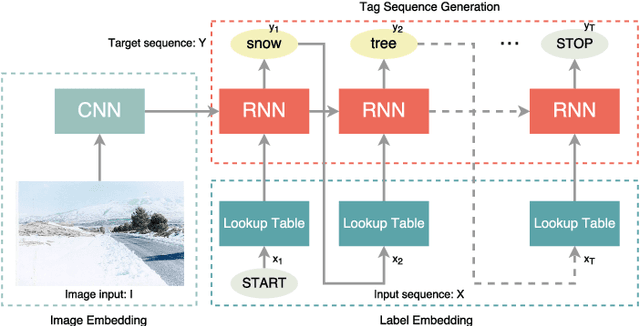


Automatic image annotation has been an important research topic in facilitating large scale image management and retrieval. Existing methods focus on learning image-tag correlation or correlation between tags to improve annotation accuracy. However, most of these methods evaluate their performance using top-k retrieval performance, where k is fixed. Although such setting gives convenience for comparing different methods, it is not the natural way that humans annotate images. The number of annotated tags should depend on image contents. Inspired by the recent progress in machine translation and image captioning, we propose a novel Recurrent Image Annotator (RIA) model that forms image annotation task as a sequence generation problem so that RIA can natively predict the proper length of tags according to image contents. We evaluate the proposed model on various image annotation datasets. In addition to comparing our model with existing methods using the conventional top-k evaluation measures, we also provide our model as a high quality baseline for the arbitrary length image tagging task. Moreover, the results of our experiments show that the order of tags in training phase has a great impact on the final annotation performance.