 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn NMF-Based Building Block for Interpretable Neural Networks With Continual Learning
Nov 20, 2023



Existing learning methods often struggle to balance interpretability and predictive performance. While models like nearest neighbors and non-negative matrix factorization (NMF) offer high interpretability, their predictive performance on supervised learning tasks is often limited. In contrast, neural networks based on the multi-layer perceptron (MLP) support the modular construction of expressive architectures and tend to have better recognition accuracy but are often regarded as black boxes in terms of interpretability. Our approach aims to strike a better balance between these two aspects through the use of a building block based on NMF that incorporates supervised neural network training methods to achieve high predictive performance while retaining the desirable interpretability properties of NMF. We evaluate our Predictive Factorized Coupling (PFC) block on small datasets and show that it achieves competitive predictive performance with MLPs while also offering improved interpretability. We demonstrate the benefits of this approach in various scenarios, such as continual learning, training on non-i.i.d. data, and knowledge removal after training. Additionally, we show examples of using the PFC block to build more expressive architectures, including a fully-connected residual network as well as a factorized recurrent neural network (RNN) that performs competitively with vanilla RNNs while providing improved interpretability. The PFC block uses an iterative inference algorithm that converges to a fixed point, making it possible to trade off accuracy vs computation after training but also currently preventing its use as a general MLP replacement in some scenarios such as training on very large datasets. We provide source code at https://github.com/bkvogel/pfc
Parameter Reference Loss for Unsupervised Domain Adaptation
Dec 05, 2017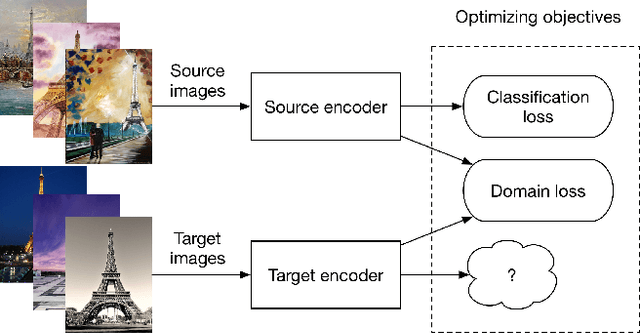
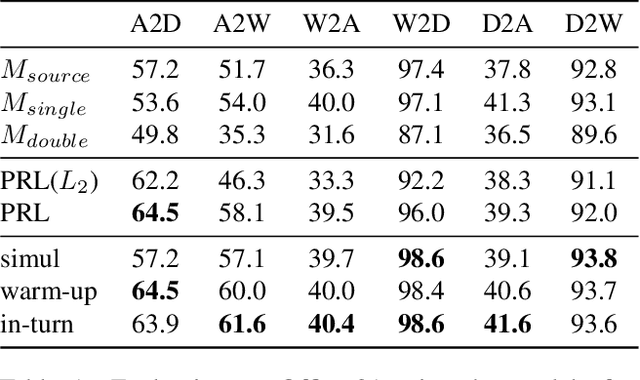

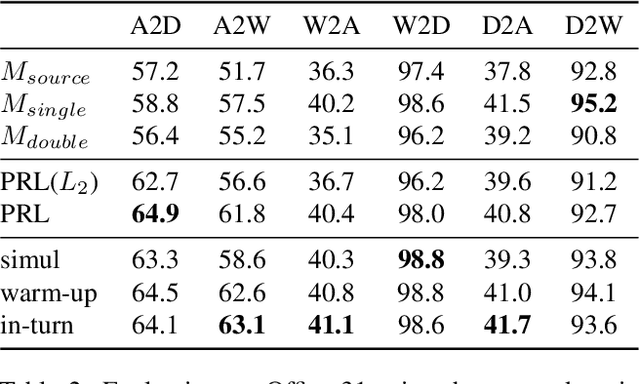
The success of deep learning in computer vision is mainly attributed to an abundance of data. However, collecting large-scale data is not always possible, especially for the supervised labels. Unsupervised domain adaptation (UDA) aims to utilize labeled data from a source domain to learn a model that generalizes to a target domain of unlabeled data. A large amount of existing work uses Siamese network-based models, where two streams of neural networks process the source and the target domain data respectively. Nevertheless, most of these approaches focus on minimizing the domain discrepancy, overlooking the importance of preserving the discriminative ability for target domain features. Another important problem in UDA research is how to evaluate the methods properly. Common evaluation procedures require target domain labels for hyper-parameter tuning and model selection, contradicting the definition of the UDA task. Hence we propose a more reasonable evaluation principle that avoids this contradiction by simply adopting the latest snapshot of a model for evaluation. This adds an extra requirement for UDA methods besides the main performance criteria: the stability during training. We design a novel method that connects the target domain stream to the source domain stream with a Parameter Reference Loss (PRL) to solve these problems simultaneously. Experiments on various datasets show that the proposed PRL not only improves the performance on the target domain, but also stabilizes the training procedure. As a result, PRL based models do not need the contradictory model selection, and thus are more suitable for practical applications.
Warping Peirce Quincuncial Panoramas
Sep 26, 2015



The Peirce quincuncial projection is a mapping of the surface of a sphere to the interior of a square. It is a conformal map except for four points on the equator. These points of non-conformality cause significant artifacts in photographic applications. In this paper, we propose an algorithm and user-interface to mitigate these artifacts. Moreover, in order to facilitate an interactive user-interface, we present a fast algorithm for calculating the Peirce quincuncial projection of spherical imagery. We then promote the Peirce quincuncial projection as a viable alternative to the more popular stereographic projection in some scenarios.
Positive factor networks: A graphical framework for modeling non-negative sequential data
Jul 16, 2009



We present a novel graphical framework for modeling non-negative sequential data with hierarchical structure. Our model corresponds to a network of coupled non-negative matrix factorization (NMF) modules, which we refer to as a positive factor network (PFN). The data model is linear, subject to non-negativity constraints, so that observation data consisting of an additive combination of individually representable observations is also representable by the network. This is a desirable property for modeling problems in computational auditory scene analysis, since distinct sound sources in the environment are often well-modeled as combining additively in the corresponding magnitude spectrogram. We propose inference and learning algorithms that leverage existing NMF algorithms and that are straightforward to implement. We present a target tracking example and provide results for synthetic observation data which serve to illustrate the interesting properties of PFNs and motivate their potential usefulness in applications such as music transcription, source separation, and speech recognition. We show how a target process characterized by a hierarchical state transition model can be represented as a PFN. Our results illustrate that a PFN which is defined in terms of a single target observation can then be used to effectively track the states of multiple simultaneous targets. Our results show that the quality of the inferred target states degrades gradually as the observation noise is increased. We also present results for an example in which meaningful hierarchical features are extracted from a spectrogram. Such a hierarchical representation could be useful for music transcription and source separation applications. We also propose a network for language modeling.