 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Time Series Anomalies Like an Expert: A Multi-Agent LLM Framework with Specialized Analyzers
May 07, 2026Recent studies have explored large language models for time-series anomaly detection, yet existing approaches often rely on a single general-purpose model to directly infer anomaly indices or intervals, limiting controllability, interpretability, and reliability for complex anomaly patterns. We propose SAGE (Specialized Analyzer Group for Expert-like Detection), a multi-agent framework for structured anomaly diagnosis in univariate time series. It decomposes anomaly analysis into four specialized Analyzers for point, structural, seasonal, and pattern anomalies. Each Analyzer applies family-specific numerical tools and diagnostic visualizations to generate evidence, while an evidence-grounded Detector consolidates the evidence into confidence-scored anomaly records with intervals and candidate types. A Supervisor then converts these structured records into analyst-facing diagnostic reports. SAGE further constructs synthetic in-context examples from normal-reference training segments, without using real anomalous segments or anomaly-type labels as in-context examples. Across three benchmarks, SAGE achieves the best average performance among strong ML/DL and language-model-based baselines. Ablation studies and human evaluation further show that the proposed framework improves detection reliability and the practical usefulness of diagnostic outputs.
Forecasting Anomaly Precursors via Uncertainty-Aware Time-Series Ensembles
Feb 19, 2026Detecting anomalies in time-series data is critical in domains such as industrial operations, finance, and cybersecurity, where early identification of abnormal patterns is essential for ensuring system reliability and enabling preventive maintenance. However, most existing methods are reactive: they detect anomalies only after they occur and lack the capability to provide proactive early warning signals. In this paper, we propose FATE (Forecasting Anomalies with Time-series Ensembles), a novel unsupervised framework for detecting Precursors-of-Anomaly (PoA) by quantifying predictive uncertainty from a diverse ensemble of time-series forecasting models. Unlike prior approaches that rely on reconstruction errors or require ground-truth labels, FATE anticipates future values and leverages ensemble disagreement to signal early signs of potential anomalies without access to target values at inference time. To rigorously evaluate PoA detection, we introduce Precursor Time-series Aware Precision and Recall (PTaPR), a new metric that extends the traditional Time-series Aware Precision and Recall (TaPR) by jointly assessing segment-level accuracy, within-segment coverage, and temporal promptness of early predictions. This enables a more holistic assessment of early warning capabilities that existing metrics overlook. Experiments on five real-world benchmark datasets show that FATE achieves an average improvement of 19.9 percentage points in PTaPR AUC and 20.02 percentage points in early detection F1 score, outperforming baselines while requiring no anomaly labels. These results demonstrate the effectiveness and practicality of FATE for real-time unsupervised early warning in complex time-series environments.
Modeling and Optimizing the Provisioning of Exhaustible Capabilities for Simultaneous Task Allocation and Scheduling
Feb 14, 2026Deploying heterogeneous robot teams to accomplish multiple tasks over extended time horizons presents significant computational challenges for task allocation and planning. In this paper, we present a comprehensive, time-extended, offline heterogeneous multi-robot task allocation framework, TRAITS, which we believe to be the first that can cope with the provisioning of exhaustible traits under battery and temporal constraints. Specifically, we introduce a nonlinear programming-based trait distribution module that can optimize the trait-provisioning rate of coalitions to yield feasible and time-efficient solutions. TRAITS provides a more accurate feasibility assessment and estimation of task execution times and makespan by leveraging trait-provisioning rates while optimizing battery consumption -- an advantage that state-of-the-art frameworks lack. We evaluate TRAITS against two state-of-the-art frameworks, with results demonstrating its advantage in satisfying complex trait and battery requirements while remaining computationally tractable.
COMET: Codebook-based Online-adaptive Multi-scale Embedding for Time-series Anomaly Detection
Feb 03, 2026Time series anomaly detection is a critical task across various industrial domains. However, capturing temporal dependencies and multivariate correlations within patch-level representation learning remains underexplored, and reliance on single-scale patterns limits the detection of anomalies across different temporal ranges. Furthermore, focusing on normal data representations makes models vulnerable to distribution shifts at inference time. To address these limitations, we propose Codebook-based Online-adaptive Multi-scale Embedding for Time-series anomaly detection (COMET), which consists of three key components: (1) Multi-scale Patch Encoding captures temporal dependencies and inter-variable correlations across multiple patch scales. (2) Vector-Quantized Coreset learns representative normal patterns via codebook and detects anomalies with a dual-score combining quantization error and memory distance. (3) Online Codebook Adaptation generates pseudo-labels based on codebook entries and dynamically adapts the model at inference through contrastive learning. Experiments on five benchmark datasets demonstrate that COMET achieves the best performance in 36 out of 45 evaluation metrics, validating its effectiveness across diverse environments.
Learning and Optimizing the Efficacy of Spatio-Temporal Task Allocation under Temporal and Resource Constraints
Jan 05, 2026Complex multi-robot missions often require heterogeneous teams to jointly optimize task allocation, scheduling, and path planning to improve team performance under strict constraints. We formalize these complexities into a new class of problems, dubbed Spatio-Temporal Efficacy-optimized Allocation for Multi-robot systems (STEAM). STEAM builds upon trait-based frameworks that model robots using their capabilities (e.g., payload and speed), but goes beyond the typical binary success-failure model by explicitly modeling the efficacy of allocations as trait-efficacy maps. These maps encode how the aggregated capabilities assigned to a task determine performance. Further, STEAM accommodates spatio-temporal constraints, including a user-specified time budget (i.e., maximum makespan). To solve STEAM problems, we contribute a novel algorithm named Efficacy-optimized Incremental Task Allocation Graph Search (E-ITAGS) that simultaneously optimizes task performance and respects time budgets by interleaving task allocation, scheduling, and path planning. Motivated by the fact that trait-efficacy maps are difficult, if not impossible, to specify, E-ITAGS efficiently learns them using a realizability-aware active learning module. Our approach is realizability-aware since it explicitly accounts for the fact that not all combinations of traits are realizable by the robots available during learning. Further, we derive experimentally-validated bounds on E-ITAGS' suboptimality with respect to efficacy. Detailed numerical simulations and experiments using an emergency response domain demonstrate that E-ITAGS generates allocations of higher efficacy compared to baselines, while respecting resource and spatio-temporal constraints. We also show that our active learning approach is sample efficient and establishes a principled tradeoff between data and computational efficiency.
Unveiling Key Aspects of Fine-Tuning in Sentence Embeddings: A Representation Rank Analysis
May 18, 2024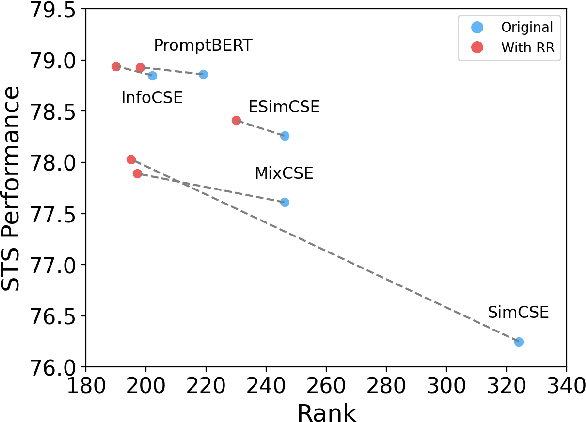
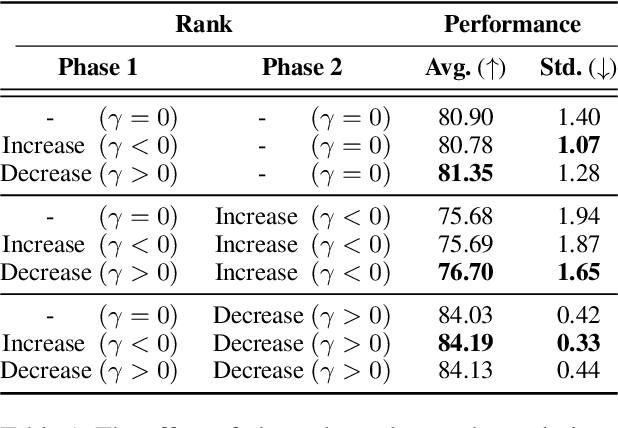
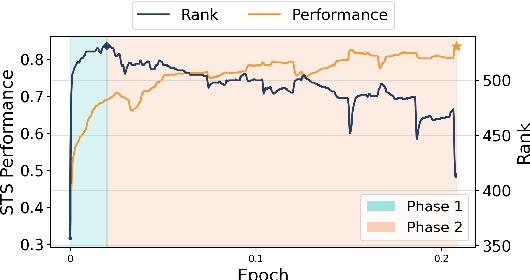

The latest advancements in unsupervised learning of sentence embeddings predominantly involve employing contrastive learning-based (CL-based) fine-tuning over pre-trained language models. In this study, we analyze the latest sentence embedding methods by adopting representation rank as the primary tool of analysis. We first define Phase 1 and Phase 2 of fine-tuning based on when representation rank peaks. Utilizing these phases, we conduct a thorough analysis and obtain essential findings across key aspects, including alignment and uniformity, linguistic abilities, and correlation between performance and rank. For instance, we find that the dynamics of the key aspects can undergo significant changes as fine-tuning transitions from Phase 1 to Phase 2. Based on these findings, we experiment with a rank reduction (RR) strategy that facilitates rapid and stable fine-tuning of the latest CL-based methods. Through empirical investigations, we showcase the efficacy of RR in enhancing the performance and stability of five state-of-the-art sentence embedding methods.
Deep reinforcement learning for guidewire navigation in coronary artery phantom
Oct 05, 2021

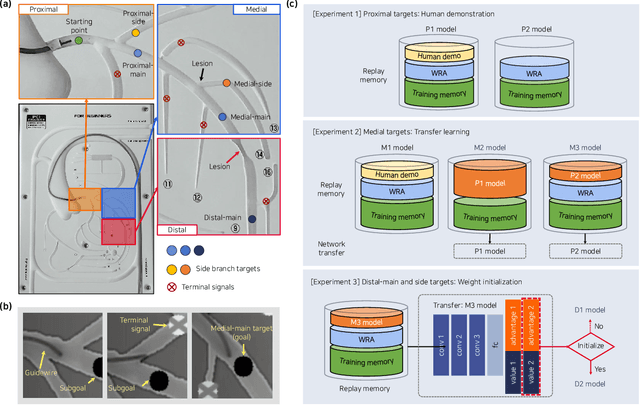

In percutaneous intervention for treatment of coronary plaques, guidewire navigation is a primary procedure for stent delivery. Steering a flexible guidewire within coronary arteries requires considerable training, and the non-linearity between the control operation and the movement of the guidewire makes precise manipulation difficult. Here, we introduce a deep reinforcement learning(RL) framework for autonomous guidewire navigation in a robot-assisted coronary intervention. Using Rainbow, a segment-wise learning approach is applied to determine how best to accelerate training using human demonstrations with deep Q-learning from demonstrations (DQfD), transfer learning, and weight initialization. `State' for RL is customized as a focus window near the guidewire tip, and subgoals are placed to mitigate a sparse reward problem. The RL agent improves performance, eventually enabling the guidewire to reach all valid targets in `stable' phase. Our framework opens anew direction in the automation of robot-assisted intervention, providing guidance on RL in physical spaces involving mechanical fatigue.