 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Implicit Neural Network for Binaural Audio Synthesis
Sep 17, 2025



High-fidelity binaural audio synthesis is crucial for immersive listening, but existing methods require extensive computational resources, limiting their edge-device application. To address this, we propose the Lightweight Implicit Neural Network (LINN), a novel two-stage framework. LINN first generates initial estimates using a time-domain warping, which is then refined by an Implicit Binaural Corrector (IBC) module. IBC is an implicit neural network that predicts amplitude and phase corrections directly, resulting in a highly compact model architecture. Experimental results show that LINN achieves statistically comparable perceptual quality to the best-performing baseline model while significantly improving computational efficiency. Compared to the most efficient existing method, LINN achieves a 72.7% reduction in parameters and significantly fewer compute operations (MACs). This demonstrates that our approach effectively addresses the trade-off between synthesis quality and computational efficiency, providing a new solution for high-fidelity edge-device spatial audio applications.
A Lightweight Fourier-based Network for Binaural Speech Enhancement with Spatial Cue Preservation
Sep 17, 2025Binaural speech enhancement faces a severe trade-off challenge, where state-of-the-art performance is achieved by computationally intensive architectures, while lightweight solutions often come at the cost of significant performance degradation. To bridge this gap, we propose the Global Adaptive Fourier Network (GAF-Net), a lightweight deep complex network that aims to establish a balance between performance and computational efficiency. The GAF-Net architecture consists of three components. First, a dual-feature encoder combining short-time Fourier transform and gammatone features enhances the robustness of acoustic representation. Second, a channel-independent globally adaptive Fourier modulator efficiently captures long-term temporal dependencies while preserving the spatial cues. Finally, a dynamic gating mechanism is implemented to reduce processing artifacts. Experimental results show that GAF-Net achieves competitive performance, particularly in terms of binaural cues (ILD and IPD error) and objective intelligibility (MBSTOI), with fewer parameters and computational cost. These results confirm that GAF-Net provides a feasible way to achieve high-fidelity binaural processing on resource-constrained devices.
Behind the Scenes: Mechanistic Interpretability of LoRA-adapted Whisper for Speech Emotion Recognition
Sep 11, 2025Large pre-trained speech models such as Whisper offer strong generalization but pose significant challenges for resource-efficient adaptation. Low-Rank Adaptation (LoRA) has become a popular parameter-efficient fine-tuning method, yet its underlying mechanisms in speech tasks remain poorly understood. In this work, we conduct the first systematic mechanistic interpretability study of LoRA within the Whisper encoder for speech emotion recognition (SER). Using a suite of analytical tools, including layer contribution probing, logit-lens inspection, and representational similarity via singular value decomposition (SVD) and centered kernel alignment (CKA), we reveal two key mechanisms: a delayed specialization process that preserves general features in early layers before consolidating task-specific information, and a forward alignment, backward differentiation dynamic between LoRA's matrices. Our findings clarify how LoRA reshapes encoder hierarchies, providing both empirical insights and a deeper mechanistic understanding for designing efficient and interpretable adaptation strategies in large speech models. Our code is available at https://github.com/harryporry77/Behind-the-Scenes.
EmotionBox: a music-element-driven emotional music generation system using Recurrent Neural Network
Dec 16, 2021
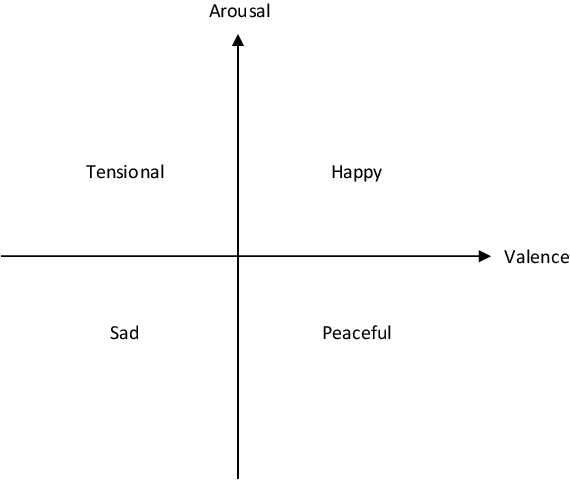
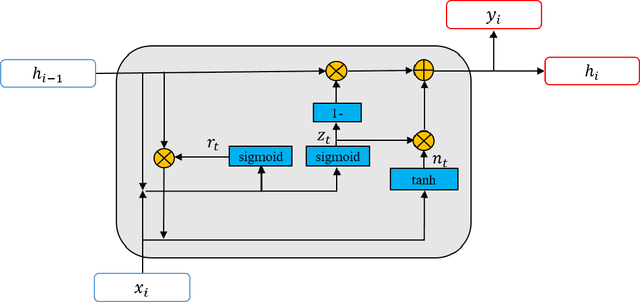
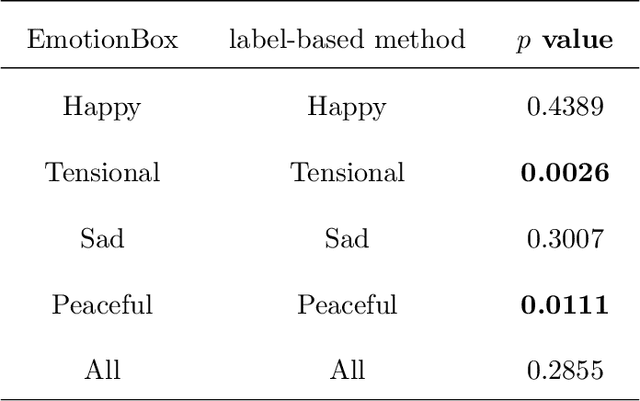
With the development of deep neural networks, automatic music composition has made great progress. Although emotional music can evoke listeners' different emotions and it is important for artistic expression, only few researches have focused on generating emotional music. This paper presents EmotionBox -an music-element-driven emotional music generator that is capable of composing music given a specific emotion, where this model does not require a music dataset labeled with emotions. Instead, pitch histogram and note density are extracted as features that represent mode and tempo respectively to control music emotions. The subjective listening tests show that the Emotionbox has a more competitive and balanced performance in arousing a specified emotion than the emotion-label-based method.
Noise-robust blind reverberation time estimation using noise-aware time-frequency masking
Dec 09, 2021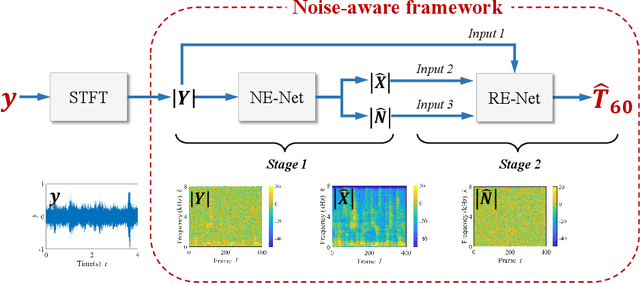
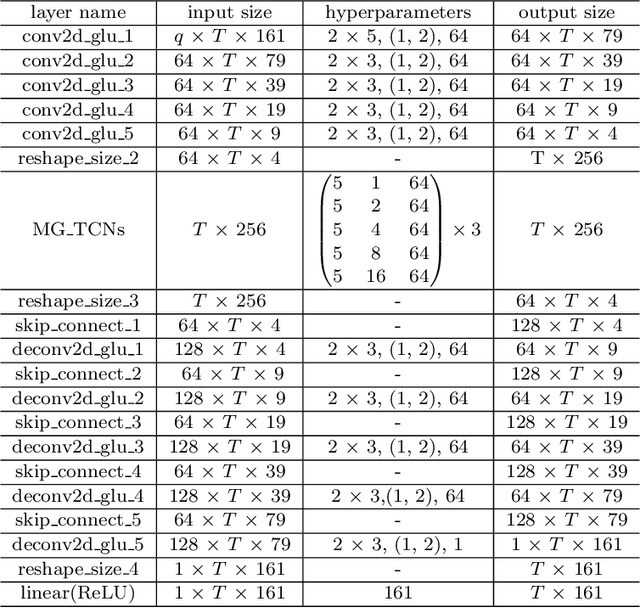
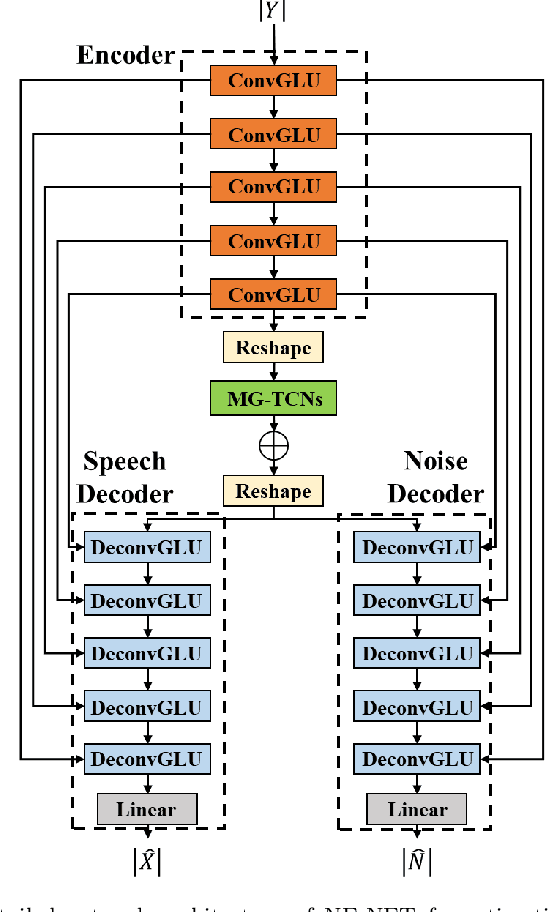

The reverberation time is one of the most important parameters used to characterize the acoustic property of an enclosure. In real-world scenarios, it is much more convenient to estimate the reverberation time blindly from recorded speech compared to the traditional acoustic measurement techniques using professional measurement instruments. However, the recorded speech is often corrupted by noise, which has a detrimental effect on the estimation accuracy of the reverberation time. To address this issue, this paper proposes a two-stage blind reverberation time estimation method based on noise-aware time-frequency masking. This proposed method has a good ability to distinguish the reverberation tails from the noise, thus improving the estimation accuracy of reverberation time in noisy scenarios. The simulated and real-world acoustic experimental results show that the proposed method significantly outperforms other methods in challenging scenarios.