 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusformer: A Transformer-based Fusion Approach for Hyperspectral Image Super-resolution
Sep 05, 2021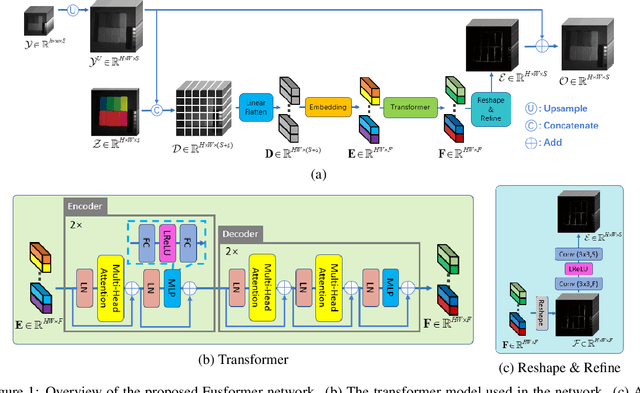



Hyperspectral image has become increasingly crucial due to its abundant spectral information. However, It has poor spatial resolution with the limitation of the current imaging mechanism. Nowadays, many convolutional neural networks have been proposed for the hyperspectral image super-resolution problem. However, convolutional neural network (CNN) based methods only consider the local information instead of the global one with the limited kernel size of receptive field in the convolution operation. In this paper, we design a network based on the transformer for fusing the low-resolution hyperspectral images and high-resolution multispectral images to obtain the high-resolution hyperspectral images. Thanks to the representing ability of the transformer, our approach is able to explore the intrinsic relationships of features globally. Furthermore, considering the LR-HSIs hold the main spectral structure, the network focuses on the spatial detail estimation releasing from the burden of reconstructing the whole data. It reduces the mapping space of the proposed network, which enhances the final performance. Various experiments and quality indexes show our approach's superiority compared with other state-of-the-art methods.
Hyperspectral Image Super-resolution via Deep Spatio-spectral Convolutional Neural Networks
May 29, 2020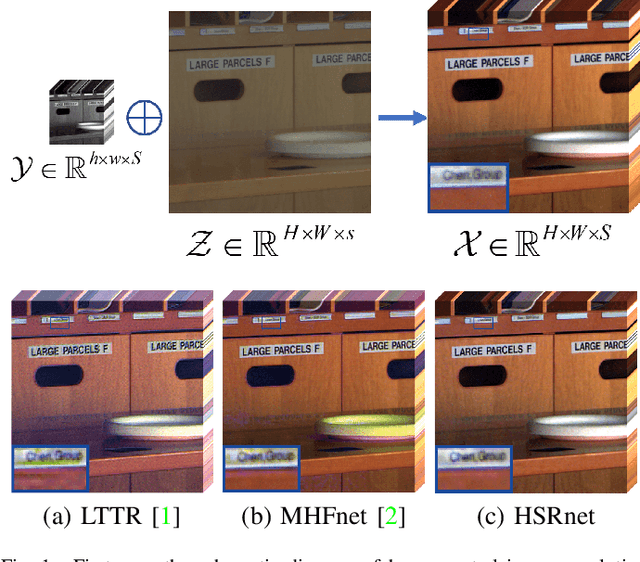



Hyperspectral images are of crucial importance in order to better understand features of different materials. To reach this goal, they leverage on a high number of spectral bands. However, this interesting characteristic is often paid by a reduced spatial resolution compared with traditional multispectral image systems. In order to alleviate this issue, in this work, we propose a simple and efficient architecture for deep convolutional neural networks to fuse a low-resolution hyperspectral image (LR-HSI) and a high-resolution multispectral image (HR-MSI), yielding a high-resolution hyperspectral image (HR-HSI). The network is designed to preserve both spatial and spectral information thanks to an architecture from two folds: one is to utilize the HR-HSI at a different scale to get an output with a satisfied spectral preservation; another one is to apply concepts of multi-resolution analysis to extract high-frequency information, aiming to output high quality spatial details. Finally, a plain mean squared error loss function is used to measure the performance during the training. Extensive experiments demonstrate that the proposed network architecture achieves best performance (both qualitatively and quantitatively) compared with recent state-of-the-art hyperspectral image super-resolution approaches. Moreover, other significant advantages can be pointed out by the use of the proposed approach, such as, a better network generalization ability, a limited computational burden, and a robustness with respect to the number of training samples.