 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Semi-supervised Learning with Noisy Zero-shot Pseudolabels
Feb 18, 2025



Semi-supervised learning (SSL) leverages limited labeled data alongside abundant unlabeled data to address labeling costs in machine learning. While recent foundation models enable zero-shot inference, attempts to integrate these capabilities into SSL through pseudo-labeling have shown mixed results due to unreliable zero-shot predictions. We present ZMT (Zero-Shot Multi-Task Learning), a framework that jointly optimizes zero-shot pseudo-labels and unsupervised representation learning objectives from contemporary SSL approaches. Our method introduces a multi-task learning-based mechanism that incorporates pseudo-labels while ensuring robustness to varying pseudo-label quality. Experiments across 8 datasets in vision, language, and audio domains demonstrate that ZMT reduces error by up to 56% compared to traditional SSL methods, with particularly compelling results when pseudo-labels are noisy and unreliable. ZMT represents a significant step toward making semi-supervised learning more effective and accessible in resource-constrained environments.
An Efficient Framework for Clustered Federated Learning
Jun 07, 2020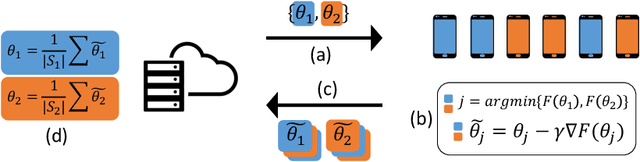

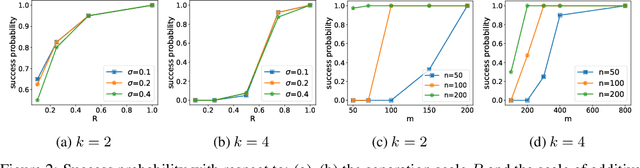
We address the problem of Federated Learning (FL) where users are distributed and partitioned into clusters. This setup captures settings where different groups of users have their own objectives (learning tasks) but by aggregating their data with others in the same cluster (same learning task), they can leverage the strength in numbers in order to perform more efficient Federated Learning. We propose a new framework dubbed the Iterative Federated Clustering Algorithm (IFCA), which alternately estimates the cluster identities of the users and optimizes model parameters for the user clusters via gradient descent. We analyze the convergence rate of this algorithm first in a linear model with squared loss and then for generic strongly convex and smooth loss functions. We show that in both settings, with good initialization, IFCA converges at an exponential rate, and discuss the optimality of the statistical error rate. In the experiments, we show that our algorithm can succeed even if we relax the requirements on initialization with random initialization and multiple restarts. We also present experimental results showing that our algorithm is efficient in non-convex problems such as neural networks and outperforms the baselines on several clustered FL benchmarks created based on the MNIST and CIFAR-10 datasets by $5\sim 8\%$.