 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Your Features Reveal: Data-Efficient Black-Box Feature Inversion Attack for Split DNNs
Nov 19, 2025Split DNNs enable edge devices by offloading intensive computation to a cloud server, but this paradigm exposes privacy vulnerabilities, as the intermediate features can be exploited to reconstruct the private inputs via Feature Inversion Attack (FIA). Existing FIA methods often produce limited reconstruction quality, making it difficult to assess the true extent of privacy leakage. To reveal the privacy risk of the leaked features, we introduce FIA-Flow, a black-box FIA framework that achieves high-fidelity image reconstruction from intermediate features. To exploit the semantic information within intermediate features, we design a Latent Feature Space Alignment Module (LFSAM) to bridge the semantic gap between the intermediate feature space and the latent space. Furthermore, to rectify distributional mismatch, we develop Deterministic Inversion Flow Matching (DIFM), which projects off-manifold features onto the target manifold with one-step inference. This decoupled design simplifies learning and enables effective training with few image-feature pairs. To quantify privacy leakage from a human perspective, we also propose two metrics based on a large vision-language model. Experiments show that FIA-Flow achieves more faithful and semantically aligned feature inversion across various models (AlexNet, ResNet, Swin Transformer, DINO, and YOLO11) and layers, revealing a more severe privacy threat in Split DNNs than previously recognized.
Dependency Structure Augmented Contextual Scoping Framework for Multimodal Aspect-Based Sentiment Analysis
Apr 15, 2025Multimodal Aspect-Based Sentiment Analysis (MABSA) seeks to extract fine-grained information from image-text pairs to identify aspect terms and determine their sentiment polarity. However, existing approaches often fall short in simultaneously addressing three core challenges: Sentiment Cue Perception (SCP), Multimodal Information Misalignment (MIM), and Semantic Noise Elimination (SNE). To overcome these limitations, we propose DASCO (\textbf{D}ependency Structure \textbf{A}ugmented \textbf{Sco}ping Framework), a fine-grained scope-oriented framework that enhances aspect-level sentiment reasoning by leveraging dependency parsing trees. First, we designed a multi-task pretraining strategy for MABSA on our base model, combining aspect-oriented enhancement, image-text matching, and aspect-level sentiment-sensitive cognition. This improved the model's perception of aspect terms and sentiment cues while achieving effective image-text alignment, addressing key challenges like SCP and MIM. Furthermore, we incorporate dependency trees as syntactic branch combining with semantic branch, guiding the model to selectively attend to critical contextual elements within a target-specific scope while effectively filtering out irrelevant noise for addressing SNE problem. Extensive experiments on two benchmark datasets across three subtasks demonstrate that DASCO achieves state-of-the-art performance in MABSA, with notable gains in JMASA (+3.1\% F1 and +5.4\% precision on Twitter2015).
VOS: a Method for Variational Oversampling of Imbalanced Data
Sep 07, 2018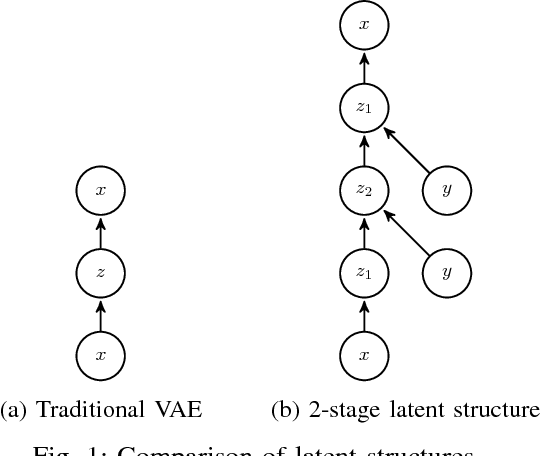
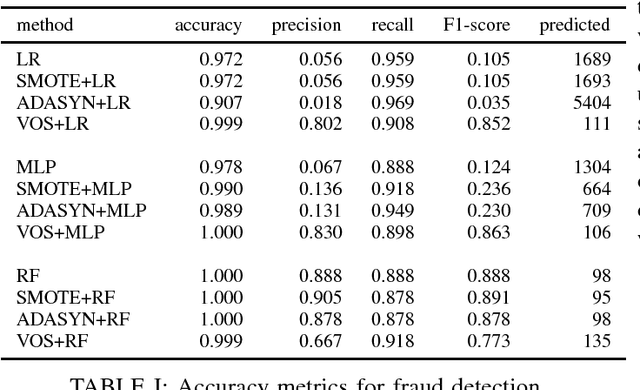

Class imbalanced datasets are common in real-world applications that range from credit card fraud detection to rare disease diagnostics. Several popular classification algorithms assume that classes are approximately balanced, and hence build the accompanying objective function to maximize an overall accuracy rate. In these situations, optimizing the overall accuracy will lead to highly skewed predictions towards the majority class. Moreover, the negative business impact resulting from false positives (positive samples incorrectly classified as negative) can be detrimental. Many methods have been proposed to address the class imbalance problem, including methods such as over-sampling, under-sampling and cost-sensitive methods. In this paper, we consider the over-sampling method, where the aim is to augment the original dataset with synthetically created observations of the minority classes. In particular, inspired by the recent advances in generative modelling techniques (e.g., Variational Inference and Generative Adversarial Networks), we introduce a new oversampling technique based on variational autoencoders. Our experiments show that the new method is superior in augmenting datasets for downstream classification tasks when compared to traditional oversampling methods.
On the EM-Tau algorithm: a new EM-style algorithm with partial E-steps
Nov 21, 2017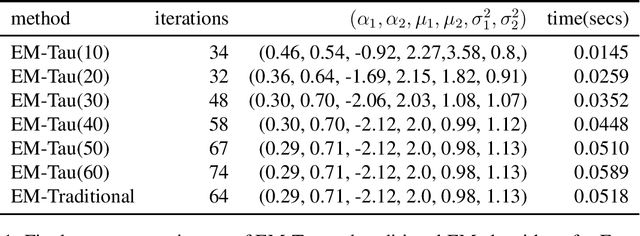
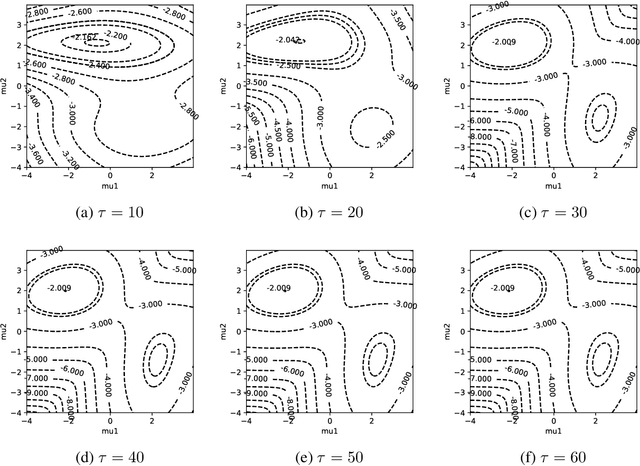
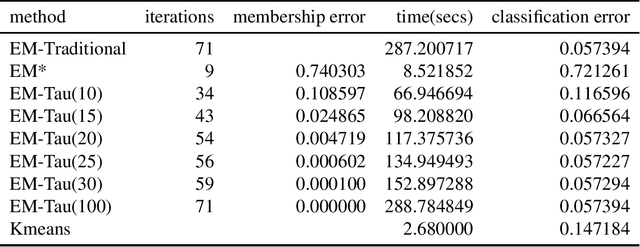
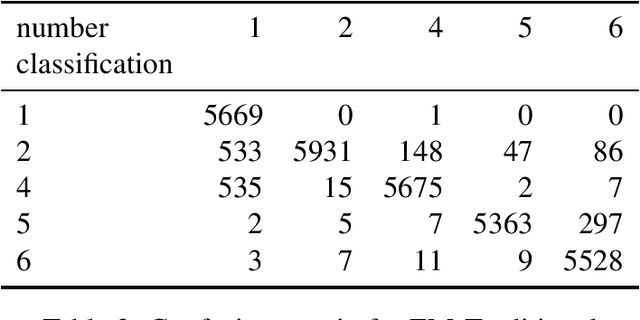
The EM algorithm is one of many important tools in the field of statistics. While often used for imputing missing data, its widespread applications include other common statistical tasks, such as clustering. In clustering, the EM algorithm assumes a parametric distribution for the clusters, whose parameters are estimated through a novel iterative procedure that is based on the theory of maximum likelihood. However, one major drawback of the EM algorithm, that renders it impractical especially when working with large datasets, is that it often requires several passes of the data before convergence. In this paper, we introduce a new EM-style algorithm that implements a novel policy for performing partial E-steps. We call the new algorithm the EM-Tau algorithm, which can approximate the traditional EM algorithm with high accuracy but with only a fraction of the running time.
A New Method for Performance Analysis in Nonlinear Dimensionality Reduction
Nov 16, 2017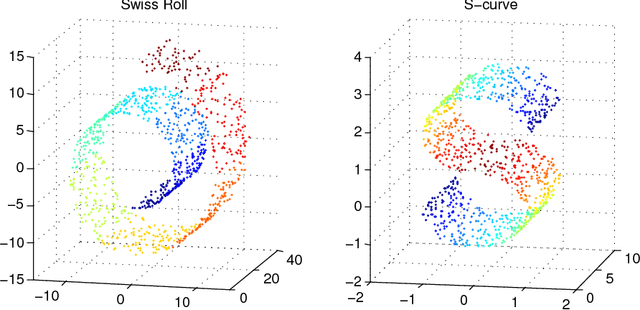
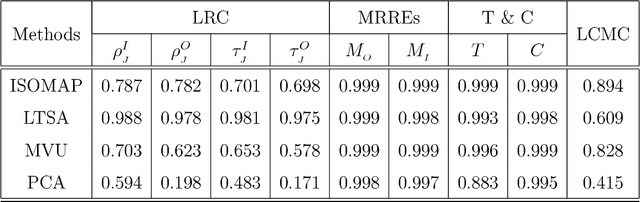
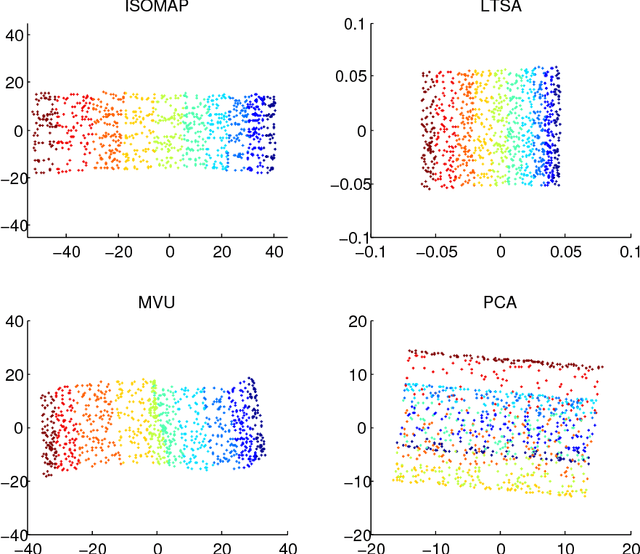
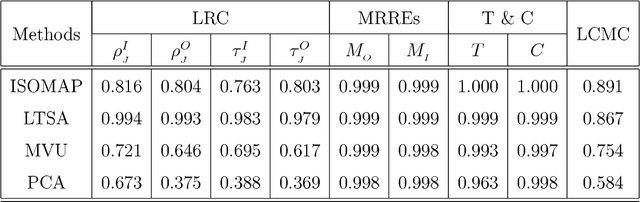
In this paper, we develop a local rank correlation measure which quantifies the performance of dimension reduction methods. The local rank correlation is easily interpretable, and robust against the extreme skewness of nearest neighbor distributions in high dimensions. Some benchmark datasets are studied. We find that the local rank correlation closely corresponds to our visual interpretation of the quality of the output. In addition, we demonstrate that the local rank correlation is useful in estimating the intrinsic dimensionality of the original data, and in selecting a suitable value of tuning parameters used in some algorithms.