 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGEST: Dynamic Spatial-Spectral Expert Routing for Hyperspectral Image Classification
Mar 25, 2026Deep learning methods, including Convolutional Neural Networks, Transformers and Mamba, have achieved remarkable success in hyperspectral image (HSI) classification. Nevertheless, existing methods exhibit inflexible integration of local-global representations, inadequate handling of spectral-spatial scale disparities across heterogeneous bands, and susceptibility to the Hughes phenomenon under high-dimensional sample heterogeneity. To address these challenges, we propose Local-Global Expert Spatial-Spectral Transformer (LGEST), a novel framework that synergistically combines three key innovations. The LGEST first employs a Deep Spatial-Spectral Autoencoder (DSAE) to generate compact yet discriminative embeddings through hierarchical nonlinear compression, preserving 3D neighborhood coherence while mitigating information loss in high-dimensional spaces. Secondly, a Cross-Interactive Mixed Expert Feature Pyramid (CIEM-FPN) leverages cross-attention mechanisms and residual mixture-of-experts layers to dynamically fuse multi-scale features, adaptively weighting spectral discriminability and spatial saliency through learnable gating functions. Finally, a Local-Global Expert System (LGES) processes decomposed features via sparsely activated expert pairs: convolutional sub-experts capture fine-grained textures, while transformer sub-experts model long-range contextual dependencies, with a routing controller dynamically selecting experts based on real-time feature saliency. Extensive experiments on four benchmark datasets demonstrate that LGEST consistently outperforms state-of-the-art methods.
Morphology-Consistent Humanoid Interaction through Robot-Centric Video Synthesis
Mar 20, 2026Equipping humanoid robots with versatile interaction skills typically requires either extensive policy training or explicit human-to-robot motion retargeting. However, learning-based policies face prohibitive data collection costs. Meanwhile, retargeting relies on human-centric pose estimation (e.g., SMPL), introducing a morphology gap. Skeletal scale mismatches result in severe spatial misalignments when mapped to robots, compromising interaction success. In this work, we propose Dream2Act, a robot-centric framework enabling zero-shot interaction through generative video synthesis. Given a third-person image of the robot and target object, our framework leverages video generation models to envision the robot completing the task with morphology-consistent motion. We employ a high-fidelity pose extraction system to recover physically feasible, robot-native joint trajectories from these synthesized dreams, subsequently executed via a general-purpose whole-body controller. Operating strictly within the robot-native coordinate space, Dream2Act avoids retargeting errors and eliminates task-specific policy training. We evaluate Dream2Act on the Unitree G1 across four whole-body mobile interaction tasks: ball kicking, sofa sitting, bag punching, and box hugging. Dream2Act achieves a 37.5% overall success rate, compared to 0% for conventional retargeting. While retargeting fails to establish correct physical contacts due to the morphology gap (with errors compounded during locomotion), Dream2Act maintains robot-consistent spatial alignment, enabling reliable contact formation and substantially higher task completion.
Trust in One Round: Confidence Estimation for Large Language Models via Structural Signals
Feb 01, 2026Large language models (LLMs) are increasingly deployed in domains where errors carry high social, scientific, or safety costs. Yet standard confidence estimators, such as token likelihood, semantic similarity and multi-sample consistency, remain brittle under distribution shift, domain-specialised text, and compute limits. In this work, we present Structural Confidence, a single-pass, model-agnostic framework that enhances output correctness prediction based on multi-scale structural signals derived from a model's final-layer hidden-state trajectory. By combining spectral, local-variation, and global shape descriptors, our method captures internal stability patterns that are missed by probabilities and sentence embeddings. We conduct extensive, cross-domain evaluation across four heterogeneous benchmarks-FEVER (fact verification), SciFact (scientific claims), WikiBio-hallucination (biographical consistency), and TruthfulQA (truthfulness-oriented QA). Our Structural Confidence framework demonstrates strong performance compared with established baselines in terms of AUROC and AUPR. More importantly, unlike sampling-based consistency methods which require multiple stochastic generations and an auxiliary model, our approach uses a single deterministic forward pass, offering a practical basis for efficient, robust post-hoc confidence estimation in socially impactful, resource-constrained LLM applications.
What You See Is Not Always What You Get: An Empirical Study of Code Comprehension by Large Language Models
Dec 11, 2024Recent studies have demonstrated outstanding capabilities of large language models (LLMs) in software engineering domain, covering numerous tasks such as code generation and comprehension. While the benefit of LLMs for coding task is well noted, it is perceived that LLMs are vulnerable to adversarial attacks. In this paper, we study the specific LLM vulnerability to imperceptible character attacks, a type of prompt-injection attack that uses special characters to befuddle an LLM whilst keeping the attack hidden to human eyes. We devise four categories of attacks and investigate their effects on the performance outcomes of tasks relating to code analysis and code comprehension. Two generations of ChatGPT are included to evaluate the impact of advancements made to contemporary models. Our experimental design consisted of comparing perturbed and unperturbed code snippets and evaluating two performance outcomes, which are model confidence using log probabilities of response, and correctness of response. We conclude that earlier version of ChatGPT exhibits a strong negative linear correlation between the amount of perturbation and the performance outcomes, while the recent ChatGPT presents a strong negative correlation between the presence of perturbation and performance outcomes, but no valid correlational relationship between perturbation budget and performance outcomes. We anticipate this work contributes to an in-depth understanding of leveraging LLMs for coding tasks. It is suggested future research should delve into how to create LLMs that can return a correct response even if the prompt exhibits perturbations.
Fairpriori: Improving Biased Subgroup Discovery for Deep Neural Network Fairness
Jun 25, 2024While deep learning has become a core functional module of most software systems, concerns regarding the fairness of ML predictions have emerged as a significant issue that affects prediction results due to discrimination. Intersectional bias, which disproportionately affects members of subgroups, is a prime example of this. For instance, a machine learning model might exhibit bias against darker-skinned women, while not showing bias against individuals with darker skin or women. This problem calls for effective fairness testing before the deployment of such deep learning models in real-world scenarios. However, research into detecting such bias is currently limited compared to research on individual and group fairness. Existing tools to investigate intersectional bias lack important features such as support for multiple fairness metrics, fast and efficient computation, and user-friendly interpretation. This paper introduces Fairpriori, a novel biased subgroup discovery method, which aims to address these limitations. Fairpriori incorporates the frequent itemset generation algorithm to facilitate effective and efficient investigation of intersectional bias by producing fast fairness metric calculations on subgroups of a dataset. Through comparison with the state-of-the-art methods (e.g., Themis, FairFictPlay, and TestSGD) under similar conditions, Fairpriori demonstrates superior effectiveness and efficiency when identifying intersectional bias. Specifically, Fairpriori is easier to use and interpret, supports a wider range of use cases by accommodating multiple fairness metrics, and exhibits higher efficiency in computing fairness metrics. These findings showcase Fairpriori's potential for effectively uncovering subgroups affected by intersectional bias, supported by its open-source tooling at https://anonymous.4open.science/r/Fairpriori-0320.
Code Ownership in Open-Source AI Software Security
Dec 18, 2023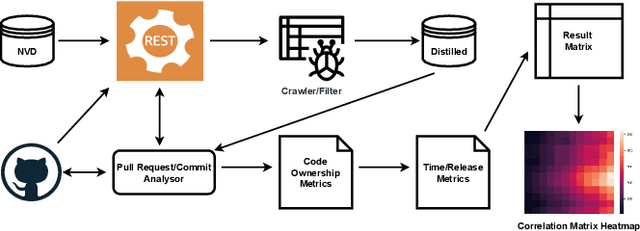
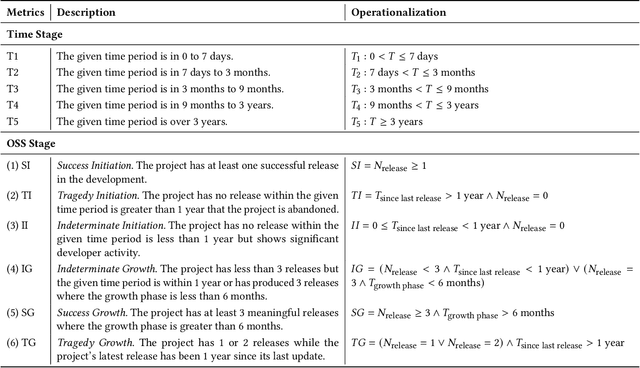
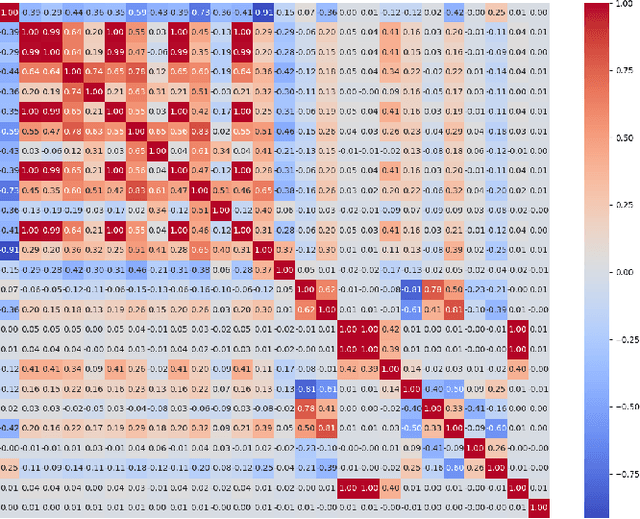
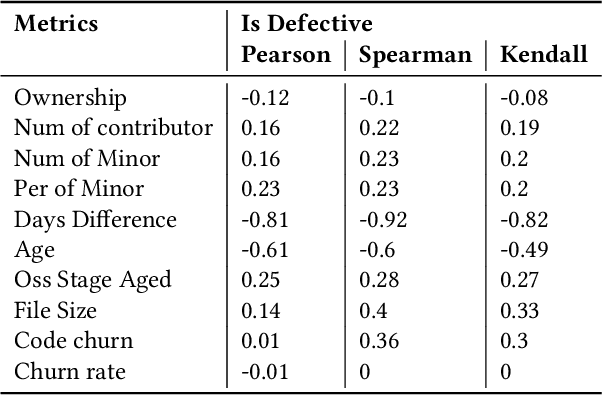
As open-source AI software projects become an integral component in the AI software development, it is critical to develop a novel methods to ensure and measure the security of the open-source projects for developers. Code ownership, pivotal in the evolution of such projects, offers insights into developer engagement and potential vulnerabilities. In this paper, we leverage the code ownership metrics to empirically investigate the correlation with the latent vulnerabilities across five prominent open-source AI software projects. The findings from the large-scale empirical study suggest a positive relationship between high-level ownership (characterised by a limited number of minor contributors) and a decrease in vulnerabilities. Furthermore, we innovatively introduce the time metrics, anchored on the project's duration, individual source code file timelines, and the count of impacted releases. These metrics adeptly categorise distinct phases of open-source AI software projects and their respective vulnerability intensities. With these novel code ownership metrics, we have implemented a Python-based command-line application to aid project curators and quality assurance professionals in evaluating and benchmarking their on-site projects. We anticipate this work will embark a continuous research development for securing and measuring open-source AI project security.