 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Ensemble of Models for Optimal Predictive Performance with Applications to Sector Rotation Strategy
Mar 30, 2023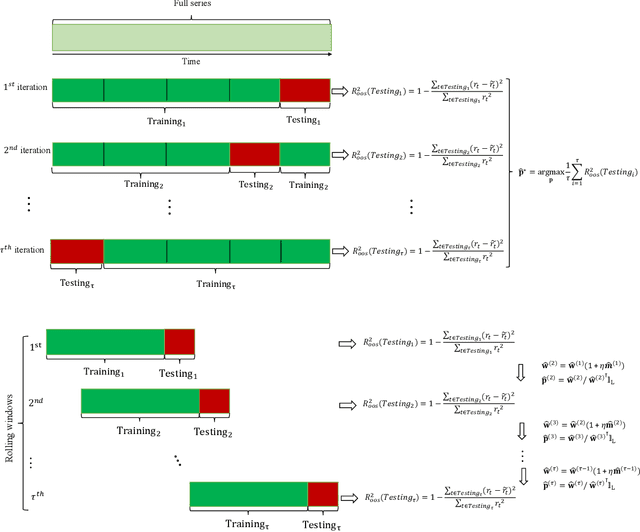



Asset-specific factors are commonly used to forecast financial returns and quantify asset-specific risk premia. Using various machine learning models, we demonstrate that the information contained in these factors leads to even larger economic gains in terms of forecasts of sector returns and the measurement of sector-specific risk premia. To capitalize on the strong predictive results of individual models for the performance of different sectors, we develop a novel online ensemble algorithm that learns to optimize predictive performance. The algorithm continuously adapts over time to determine the optimal combination of individual models by solely analyzing their most recent prediction performance. This makes it particularly suited for time series problems, rolling window backtesting procedures, and systems of potentially black-box models. We derive the optimal gain function, express the corresponding regret bounds in terms of the out-of-sample R-squared measure, and derive optimal learning rate for the algorithm. Empirically, the new ensemble outperforms both individual machine learning models and their simple averages in providing better measurements of sector risk premia. Moreover, it allows for performance attribution of different factors across various sectors, without conditioning on a specific model. Finally, by utilizing monthly predictions from our ensemble, we develop a sector rotation strategy that significantly outperforms the market. The strategy remains robust against various financial factors, periods of financial distress, and conservative transaction costs. Notably, the strategy's efficacy persists over time, exhibiting consistent improvement throughout an extended backtesting period and yielding substantial profits during the economic turbulence of the COVID-19 pandemic.
Precision-Recall Curve (PRC) Classification Trees
Nov 15, 2020



The classification of imbalanced data has presented a significant challenge for most well-known classification algorithms that were often designed for data with relatively balanced class distributions. Nevertheless skewed class distribution is a common feature in real world problems. It is especially prevalent in certain application domains with great need for machine learning and better predictive analysis such as disease diagnosis, fraud detection, bankruptcy prediction, and suspect identification. In this paper, we propose a novel tree-based algorithm based on the area under the precision-recall curve (AUPRC) for variable selection in the classification context. Our algorithm, named as the "Precision-Recall Curve classification tree", or simply the "PRC classification tree" modifies two crucial stages in tree building. The first stage is to maximize the area under the precision-recall curve in node variable selection. The second stage is to maximize the harmonic mean of recall and precision (F-measure) for threshold selection. We found the proposed PRC classification tree, and its subsequent extension, the PRC random forest, work well especially for class-imbalanced data sets. We have demonstrated that our methods outperform their classic counterparts, the usual CART and random forest for both synthetic and real data. Furthermore, the ROC classification tree proposed by our group previously has shown good performance in imbalanced data. The combination of them, the PRC-ROC tree, also shows great promise in identifying the minority class.