 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Clouds Are Specialized Images: A Knowledge Transfer Approach for 3D Understanding
Jul 28, 2023Self-supervised representation learning (SSRL) has gained increasing attention in point cloud understanding, in addressing the challenges posed by 3D data scarcity and high annotation costs. This paper presents PCExpert, a novel SSRL approach that reinterprets point clouds as "specialized images". This conceptual shift allows PCExpert to leverage knowledge derived from large-scale image modality in a more direct and deeper manner, via extensively sharing the parameters with a pre-trained image encoder in a multi-way Transformer architecture. The parameter sharing strategy, combined with a novel pretext task for pre-training, i.e., transformation estimation, empowers PCExpert to outperform the state of the arts in a variety of tasks, with a remarkable reduction in the number of trainable parameters. Notably, PCExpert's performance under LINEAR fine-tuning (e.g., yielding a 90.02% overall accuracy on ScanObjectNN) has already approached the results obtained with FULL model fine-tuning (92.66%), demonstrating its effective and robust representation capability.
Leveraging Systematic Knowledge of 2D Transformations
Jun 02, 2022

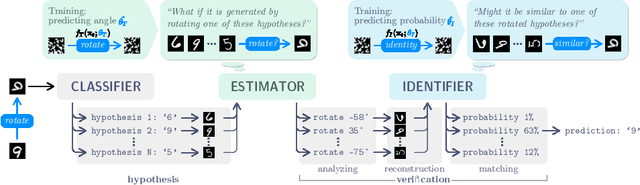

The existing deep learning models suffer from out-of-distribution (o.o.d.) performance drop in computer vision tasks. In comparison, humans have a remarkable ability to interpret images, even if the scenes in the images are rare, thanks to the systematicity of acquired knowledge. This work focuses on 1) the acquisition of systematic knowledge of 2D transformations, and 2) architectural components that can leverage the learned knowledge in image classification tasks in an o.o.d. setting. With a new training methodology based on synthetic datasets that are constructed under the causal framework, the deep neural networks acquire knowledge from semantically different domains (e.g. even from noise), and exhibit certain level of systematicity in parameter estimation experiments. Based on this, a novel architecture is devised consisting of a classifier, an estimator and an identifier (abbreviated as "CED"). By emulating the "hypothesis-verification" process in human visual perception, CED improves the classification accuracy significantly on test sets under covariate shift.