 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Ensemble approach for Enhancing Brain Tumor Segmentation in Resource-Limited Settings
Feb 04, 2025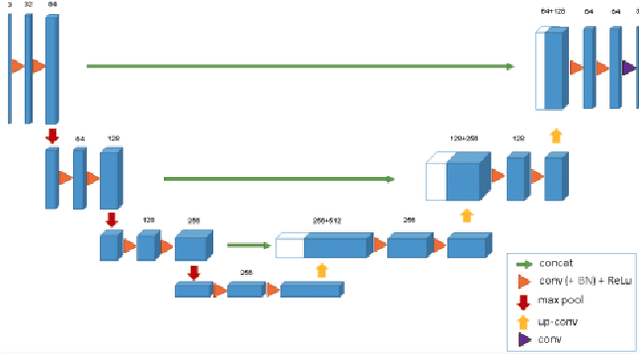
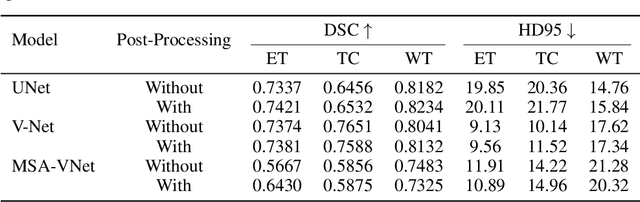
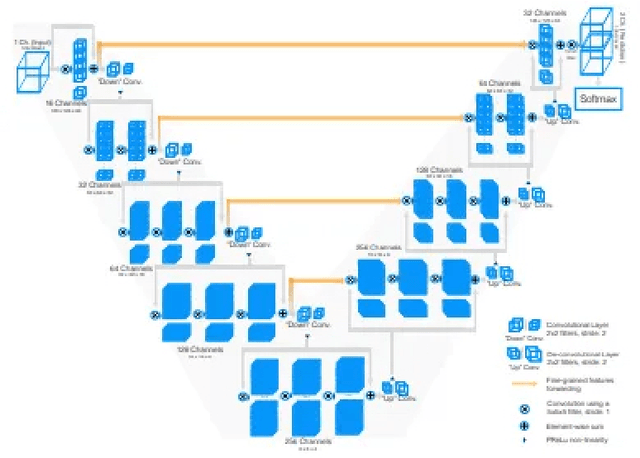
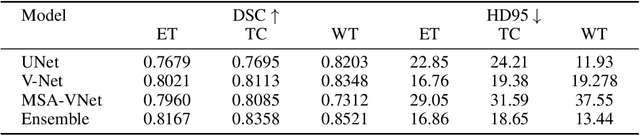
Segmentation of brain tumors is a critical step in treatment planning, yet manual segmentation is both time-consuming and subjective, relying heavily on the expertise of radiologists. In Sub-Saharan Africa, this challenge is magnified by overburdened medical systems and limited access to advanced imaging modalities and expert radiologists. Automating brain tumor segmentation using deep learning offers a promising solution. Convolutional Neural Networks (CNNs), especially the U-Net architecture, have shown significant potential. However, a major challenge remains: achieving generalizability across different datasets. This study addresses this gap by developing a deep learning ensemble that integrates UNet3D, V-Net, and MSA-VNet models for the semantic segmentation of gliomas. By initially training on the BraTS-GLI dataset and fine-tuning with the BraTS-SSA dataset, we enhance model performance. Our ensemble approach significantly outperforms individual models, achieving DICE scores of 0.8358 for Tumor Core, 0.8521 for Whole Tumor, and 0.8167 for Enhancing Tumor. These results underscore the potential of ensemble methods in improving the accuracy and reliability of automated brain tumor segmentation, particularly in resource-limited settings.
Benchmarking Retinal Blood Vessel Segmentation Models for Cross-Dataset and Cross-Disease Generalization
Jun 21, 2024



Retinal blood vessel segmentation can extract clinically relevant information from fundus images. As manual tracing is cumbersome, algorithms based on Convolution Neural Networks have been developed. Such studies have used small publicly available datasets for training and measuring performance, running the risk of overfitting. Here, we provide a rigorous benchmark for various architectural and training choices commonly used in the literature on the largest dataset published to date. We train and evaluate five published models on the publicly available FIVES fundus image dataset, which exceeds previous ones in size and quality and which contains also images from common ophthalmological conditions (diabetic retinopathy, age-related macular degeneration, glaucoma). We compare the performance of different model architectures across different loss functions, levels of image qualitiy and ophthalmological conditions and assess their ability to perform well in the face of disease-induced domain shifts. Given sufficient training data, basic architectures such as U-Net perform just as well as more advanced ones, and transfer across disease-induced domain shifts typically works well for most architectures. However, we find that image quality is a key factor determining segmentation outcomes. When optimizing for segmentation performance, investing into a well curated dataset to train a standard architecture yields better results than tuning a sophisticated architecture on a smaller dataset or one with lower image quality. We distilled the utility of architectural advances in terms of their clinical relevance therefore providing practical guidance for model choices depending on the circumstances of the clinical setting