 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness and bias correction in machine learning for depression prediction: results from four different study populations
Nov 10, 2022

A significant level of stigma and inequality exists in mental healthcare, especially in under-served populations, which spreads through collected data. When not properly accounted for, machine learning (ML) models learned from data can reinforce the structural biases already present in society. Here, we present a systematic study of bias in ML models designed to predict depression in four different case studies covering different countries and populations. We find that standard ML approaches show regularly biased behaviors. However, we show that standard mitigation techniques, and our own post-hoc method, can be effective in reducing the level of unfair bias. We provide practical recommendations to develop ML models for depression risk prediction with increased fairness and trust in the real world. No single best ML model for depression prediction provides equality of outcomes. This emphasizes the importance of analyzing fairness during model selection and transparent reporting about the impact of debiasing interventions.
Candidate Labeling for Crowd Learning
Aug 08, 2018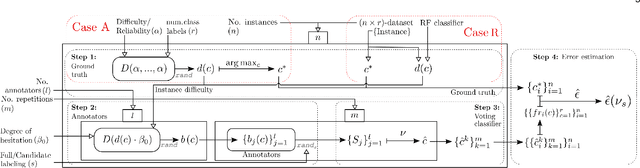
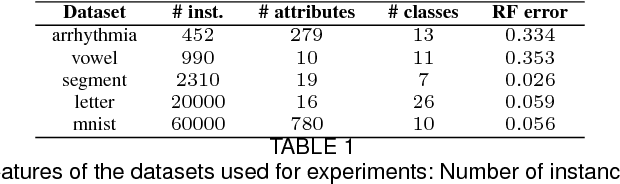
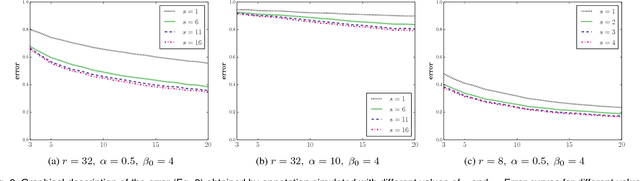
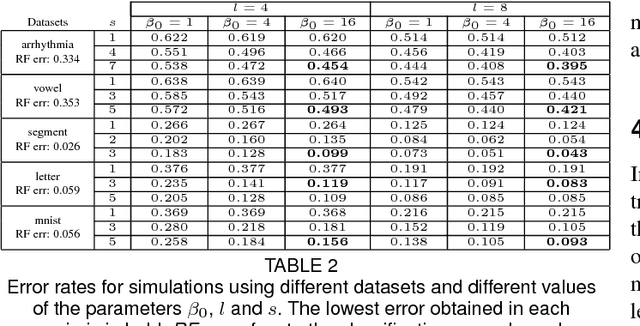
Crowdsourcing has become very popular among the machine learning community as a way to obtain labels that allow a ground truth to be estimated for a given dataset. In most of the approaches that use crowdsourced labels, annotators are asked to provide, for each presented instance, a single class label. Such a request could be inefficient, that is, considering that the labelers may not be experts, that way to proceed could fail to take real advantage of the knowledge of the labelers. In this paper, the use of candidate labeling for crowd learning is proposed, where the annotators may provide more than a single label per instance to try not to miss the real label. The main hypothesis is that, by allowing candidate labeling, knowledge can be extracted from the labelers more efficiently by than in the standard crowd learning scenario. Empirical evidence which supports that hypothesis is presented.