 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCandidate Labeling for Crowd Learning
Paper and Code
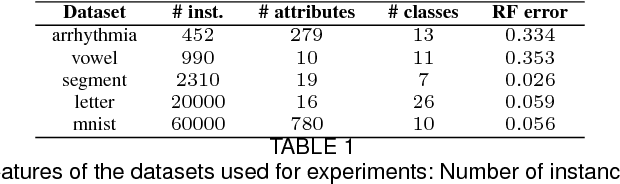
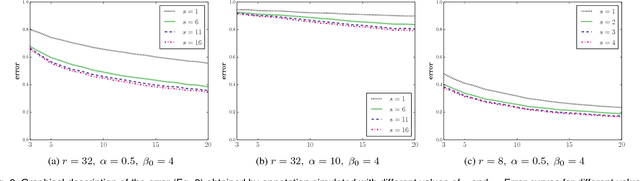
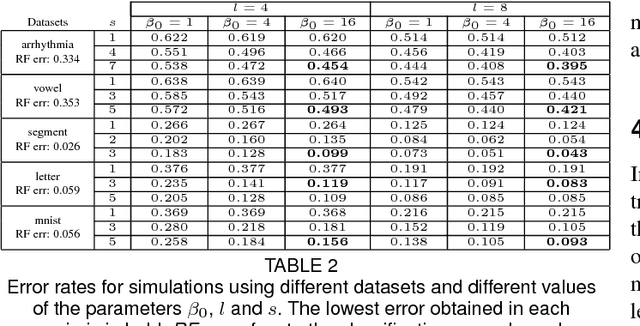
Crowdsourcing has become very popular among the machine learning community as a way to obtain labels that allow a ground truth to be estimated for a given dataset. In most of the approaches that use crowdsourced labels, annotators are asked to provide, for each presented instance, a single class label. Such a request could be inefficient, that is, considering that the labelers may not be experts, that way to proceed could fail to take real advantage of the knowledge of the labelers. In this paper, the use of candidate labeling for crowd learning is proposed, where the annotators may provide more than a single label per instance to try not to miss the real label. The main hypothesis is that, by allowing candidate labeling, knowledge can be extracted from the labelers more efficiently by than in the standard crowd learning scenario. Empirical evidence which supports that hypothesis is presented.