 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALF: Holistic Auto Machine Learning for FPGAs
Jun 28, 2021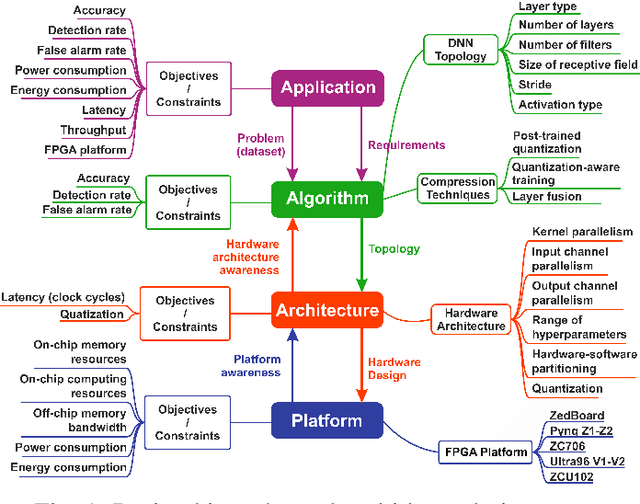
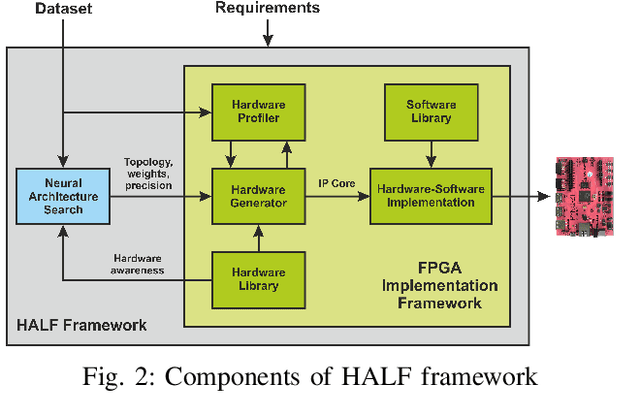
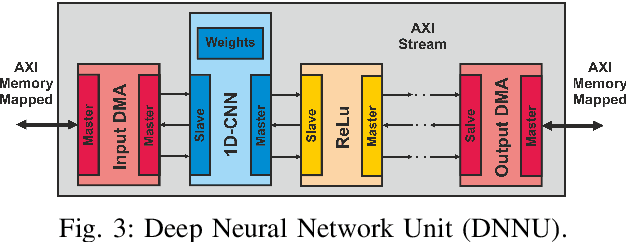
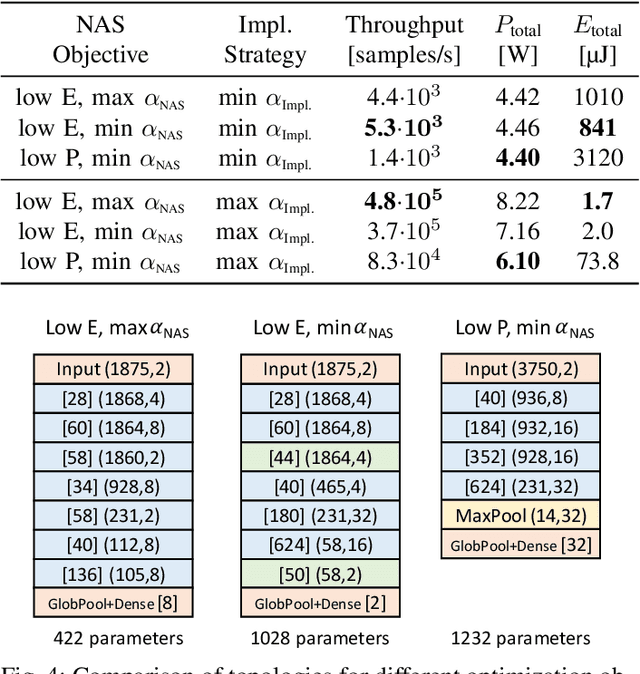
Deep Neural Networks (DNNs) are capable of solving complex problems in domains related to embedded systems, such as image and natural language processing. To efficiently implement DNNs on a specific FPGA platform for a given cost criterion, e.g. energy efficiency, an enormous amount of design parameters has to be considered from the topology down to the final hardware implementation. Interdependencies between the different design layers have to be taken into account and explored efficiently, making it hardly possible to find optimized solutions manually. An automatic, holistic design approach can improve the quality of DNN implementations on FPGA significantly. To this end, we present a cross-layer design space exploration methodology. It comprises optimizations starting from a hardware-aware topology search for DNNs down to the final optimized implementation for a given FPGA platform. The methodology is implemented in our Holistic Auto machine Learning for FPGAs (HALF) framework, which combines an evolutionary search algorithm, various optimization steps and a library of parametrizable hardware DNN modules. HALF automates both the exploration process and the implementation of optimized solutions on a target FPGA platform for various applications. We demonstrate the performance of HALF on a medical use case for arrhythmia detection for three different design goals, i.e. low-energy, low-power and high-throughput respectively. Our FPGA implementation outperforms a TensorRT optimized model on an Nvidia Jetson platform in both throughput and energy consumption.