 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Agnostic Stroke Lesion Segmentation Using Physics-Constrained Synthetic Data
Dec 04, 2024



Segmenting stroke lesions in Magnetic Resonance Imaging (MRI) is challenging due to diverse clinical imaging domains, with existing models struggling to generalise across different MRI acquisition parameters and sequences. In this work, we propose two novel physics-constrained approaches using synthetic quantitative MRI (qMRI) images to enhance the robustness and generalisability of segmentation models. We trained a qMRI estimation model to predict qMRI maps from MPRAGE images, which were used to simulate diverse MRI sequences for segmentation training. A second approach built upon prior work in synthetic data for stroke lesion segmentation, generating qMRI maps from a dataset of tissue labels. The proposed approaches improved over the baseline nnUNet on a variety of out-of-distribution datasets, with the second approach outperforming the prior synthetic data method.
NUVA: A Naming Utterance Verifier for Aphasia Treatment
Feb 10, 2021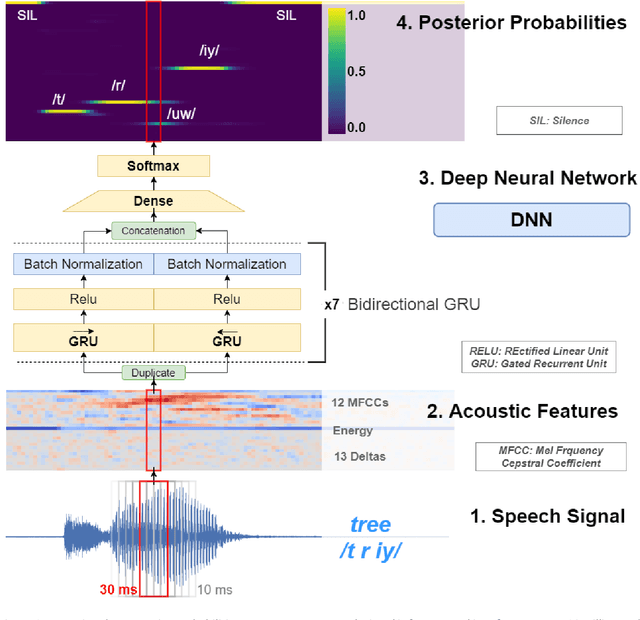



Anomia (word-finding difficulties) is the hallmark of aphasia, an acquired language disorder most commonly caused by stroke. Assessment of speech performance using picture naming tasks is a key method for both diagnosis and monitoring of responses to treatment interventions by people with aphasia (PWA). Currently, this assessment is conducted manually by speech and language therapists (SLT). Surprisingly, despite advancements in automatic speech recognition (ASR) and artificial intelligence with technologies like deep learning, research on developing automated systems for this task has been scarce. Here we present NUVA, an utterance verification system incorporating a deep learning element that classifies 'correct' versus' incorrect' naming attempts from aphasic stroke patients. When tested on eight native British-English speaking PWA the system's performance accuracy ranged between 83.6% to 93.6%, with a 10-fold cross-validation mean of 89.5%. This performance was not only significantly better than a baseline created for this study using one of the leading commercially available ASRs (Google speech-to-text service) but also comparable in some instances with two independent SLT ratings for the same dataset.