 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-layer retrieval augmented generation framework for low-resource medical question-answering: proof of concept using Reddit data
May 29, 2024



Retrieval augmented generation (RAG) provides the capability to constrain generative model outputs, and mitigate the possibility of hallucination, by providing relevant in-context text. The number of tokens a generative large language model (LLM) can incorporate as context is finite, thus limiting the volume of knowledge from which to generate an answer. We propose a two-layer RAG framework for query-focused answer generation and evaluate a proof-of-concept for this framework in the context of query-focused summary generation from social media forums, focusing on emerging drug-related information. The evaluations demonstrate the effectiveness of the two-layer framework in resource constrained settings to enable researchers in obtaining near real-time data from users.
CARE-SD: Classifier-based analysis for recognizing and eliminating stigmatizing and doubt marker labels in electronic health records: model development and validation
May 08, 2024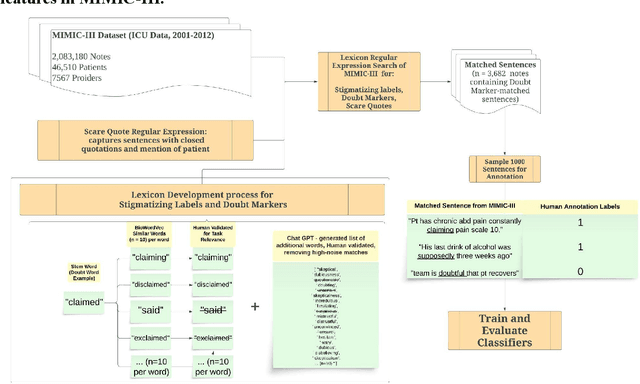
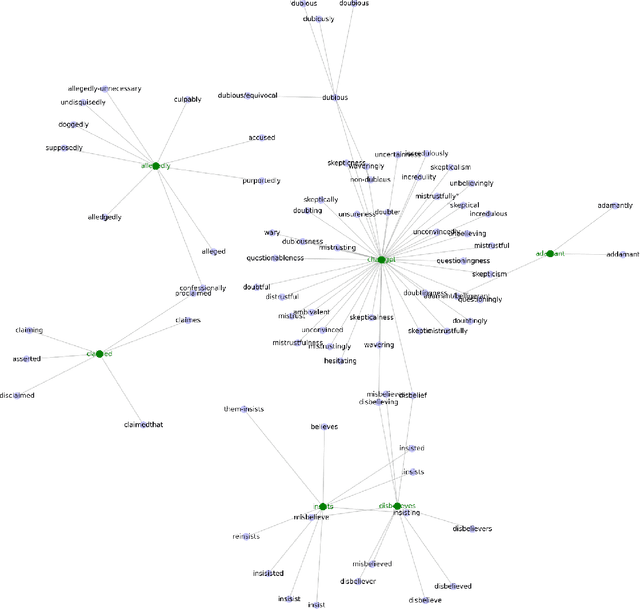
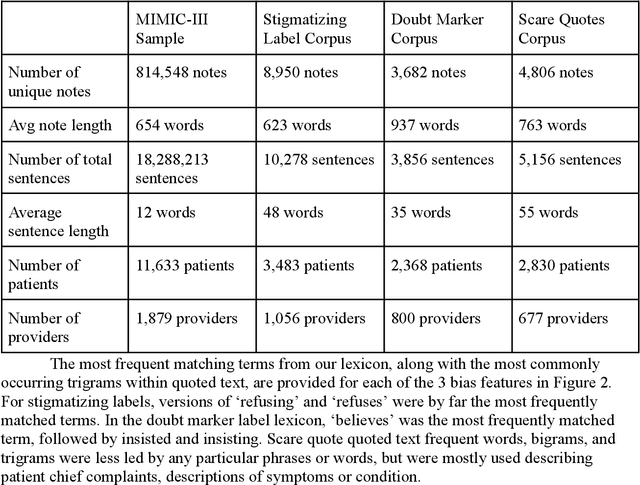
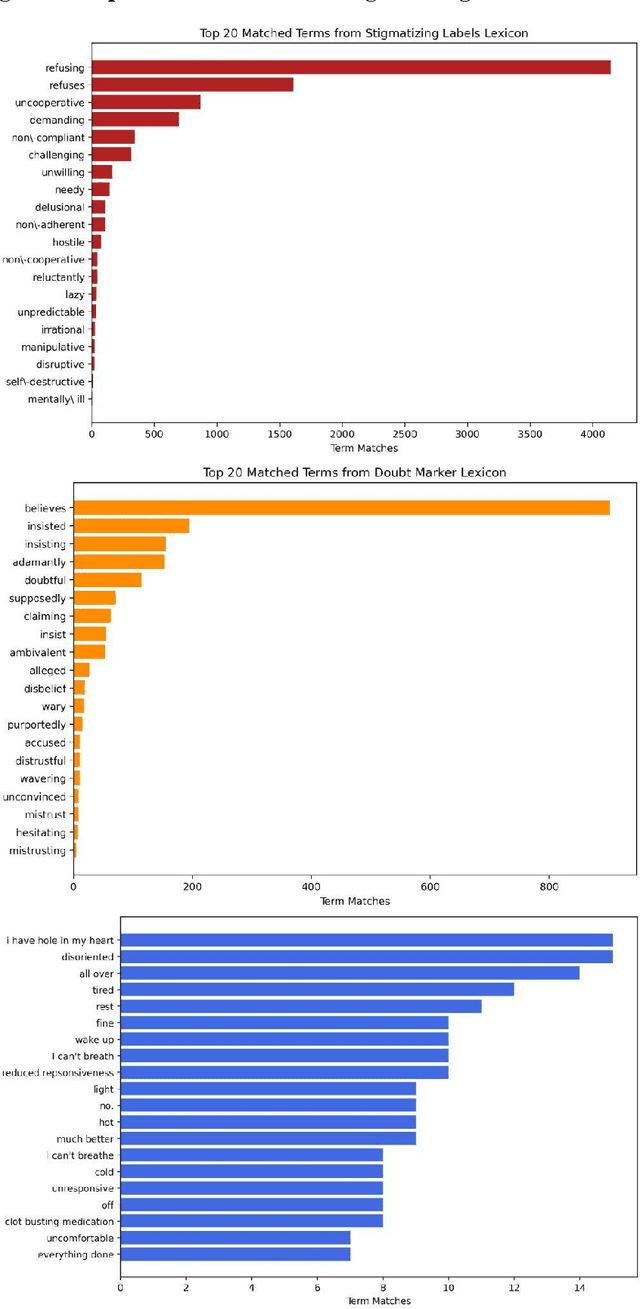
Objective: To detect and classify features of stigmatizing and biased language in intensive care electronic health records (EHRs) using natural language processing techniques. Materials and Methods: We first created a lexicon and regular expression lists from literature-driven stem words for linguistic features of stigmatizing patient labels, doubt markers, and scare quotes within EHRs. The lexicon was further extended using Word2Vec and GPT 3.5, and refined through human evaluation. These lexicons were used to search for matches across 18 million sentences from the de-identified Medical Information Mart for Intensive Care-III (MIMIC-III) dataset. For each linguistic bias feature, 1000 sentence matches were sampled, labeled by expert clinical and public health annotators, and used to supervised learning classifiers. Results: Lexicon development from expanded literature stem-word lists resulted in a doubt marker lexicon containing 58 expressions, and a stigmatizing labels lexicon containing 127 expressions. Classifiers for doubt markers and stigmatizing labels had the highest performance, with macro F1-scores of .84 and .79, positive-label recall and precision values ranging from .71 to .86, and accuracies aligning closely with human annotator agreement (.87). Discussion: This study demonstrated the feasibility of supervised classifiers in automatically identifying stigmatizing labels and doubt markers in medical text, and identified trends in stigmatizing language use in an EHR setting. Additional labeled data may help improve lower scare quote model performance. Conclusions: Classifiers developed in this study showed high model performance and can be applied to identify patterns and target interventions to reduce stigmatizing labels and doubt markers in healthcare systems.