 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthiness of Laser-Induced Breakdown Spectroscopy Predictions via Simulation-based Synthetic Data Augmentation and Multitask Learning
Oct 07, 2022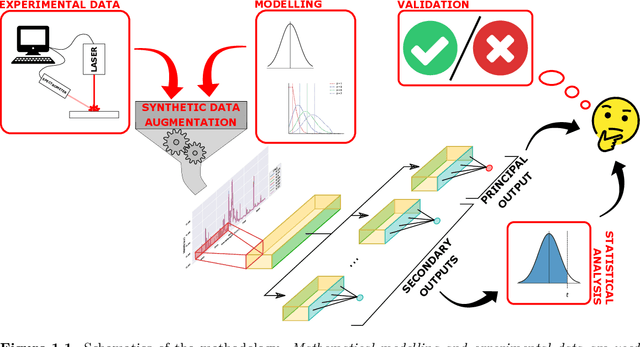
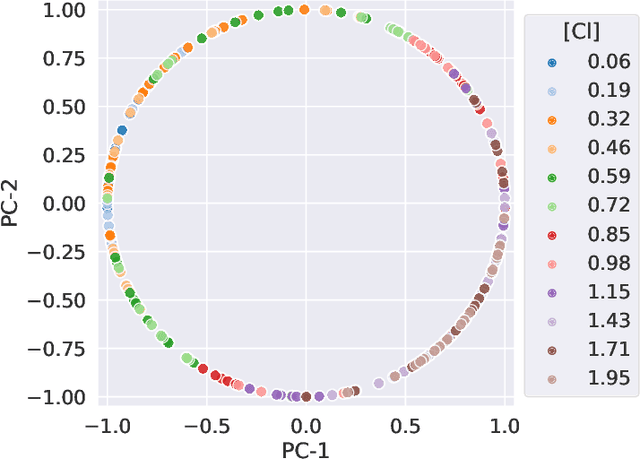
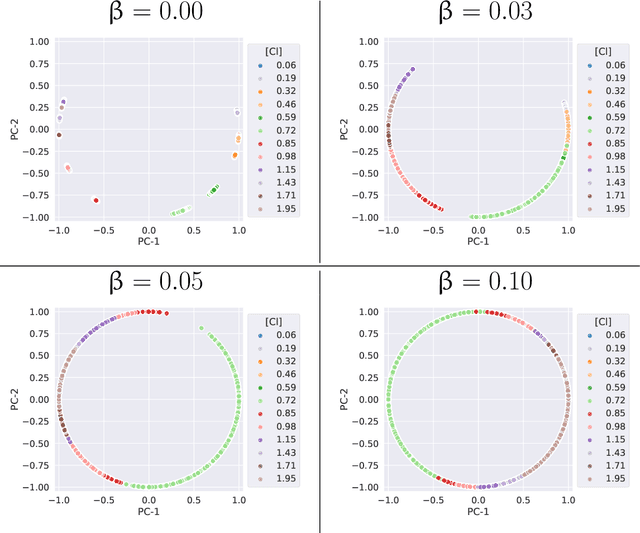
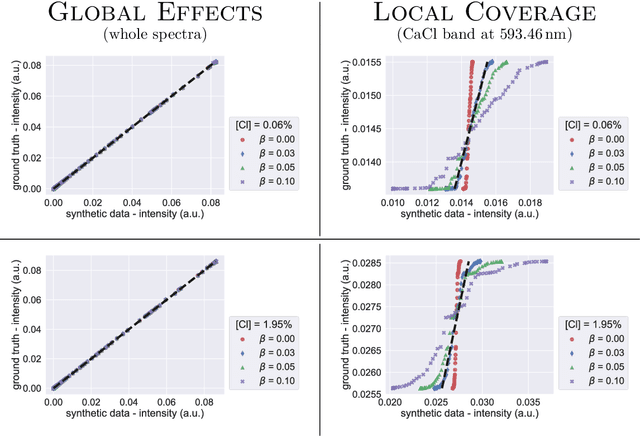
We consider quantitative analyses of spectral data using laser-induced breakdown spectroscopy. We address the small size of training data available, and the validation of the predictions during inference on unknown data. For the purpose, we build robust calibration models using deep convolutional multitask learning architectures to predict the concentration of the analyte, alongside additional spectral information as auxiliary outputs. These secondary predictions can be used to validate the trustworthiness of the model by taking advantage of the mutual dependencies of the parameters of the multitask neural networks. Due to the experimental lack of training samples, we introduce a simulation-based data augmentation process to synthesise an arbitrary number of spectra, statistically representative of the experimental data. Given the nature of the deep learning model, no dimensionality reduction or data selection processes are required. The procedure is an end-to-end pipeline including the process of synthetic data augmentation, the construction of a suitable robust, homoscedastic, deep learning model, and the validation of its predictions. In the article, we compare the performance of the multitask model with traditional univariate and multivariate analyses, to highlight the separate contributions of each element introduced in the process.
HyperPCA: a Powerful Tool to Extract Elemental Maps from Noisy Data Obtained in LIBS Mapping of Materials
Nov 30, 2021Laser-induced breakdown spectroscopy is a preferred technique for fast and direct multi-elemental mapping of samples under ambient pressure, without any limitation on the targeted element. However, LIBS mapping data have two peculiarities: an intrinsically low signal-to-noise ratio due to single-shot measurements, and a high dimensionality due to the high number of spectra acquired for imaging. This is all the truer as lateral resolution gets higher: in this case, the ablation spot diameter is reduced, as well as the ablated mass and the emission signal, while the number of spectra for a given surface increases. Therefore, efficient extraction of physico-chemical information from a noisy and large dataset is a major issue. Multivariate approaches were introduced by several authors as a means to cope with such data, particularly Principal Component Analysis. Yet, PCA is known to present theoretical constraints for the consistent reconstruction of the dataset, and has therefore limitations to efficient interpretation of LIBS mapping data. In this paper, we introduce HyperPCA, a new analysis tool for hyperspectral images based on a sparse representation of the data using Discrete Wavelet Transform and kernel-based sparse PCA to reduce the impact of noise on the data and to consistently reconstruct the spectroscopic signal, with a particular emphasis on LIBS data. The method is first illustrated using simulated LIBS mapping datasets to emphasize its performances with highly noisy and/or highly interfered spectra. Comparisons to standard PCA and to traditional univariate data analyses are provided. Finally, it is used to process real data in two cases that clearly illustrate the potential of the proposed algorithm. We show that the method presents advantages both in quantity and quality of the information recovered, thus improving the physico-chemical characterisation of analysed surfaces.