 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthiness of Laser-Induced Breakdown Spectroscopy Predictions via Simulation-based Synthetic Data Augmentation and Multitask Learning
Paper and Code
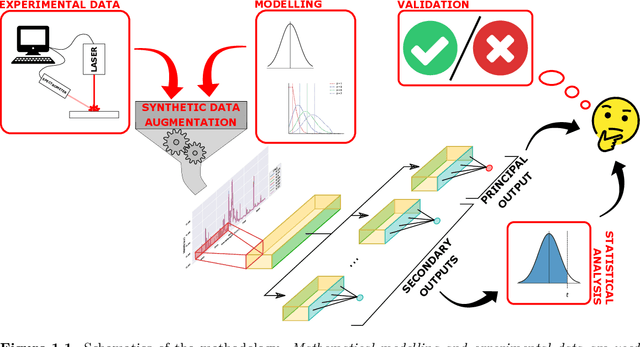
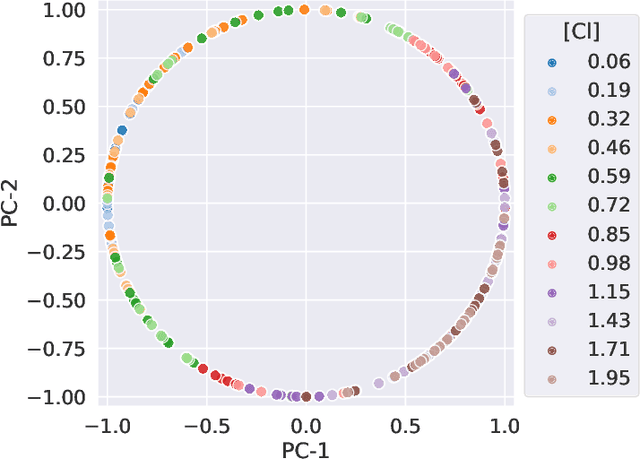
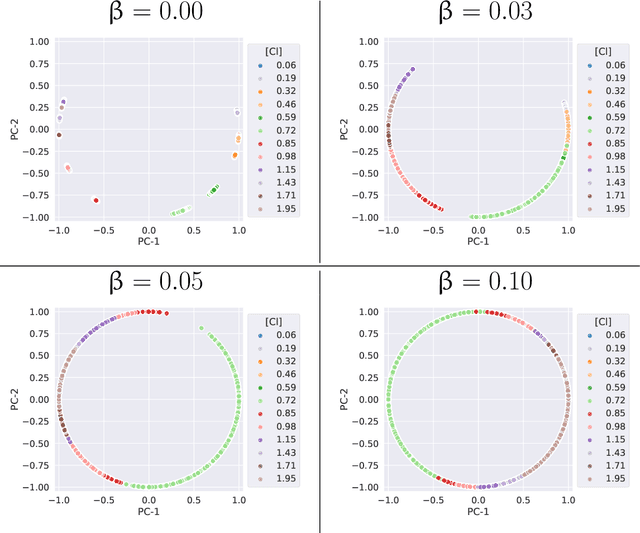
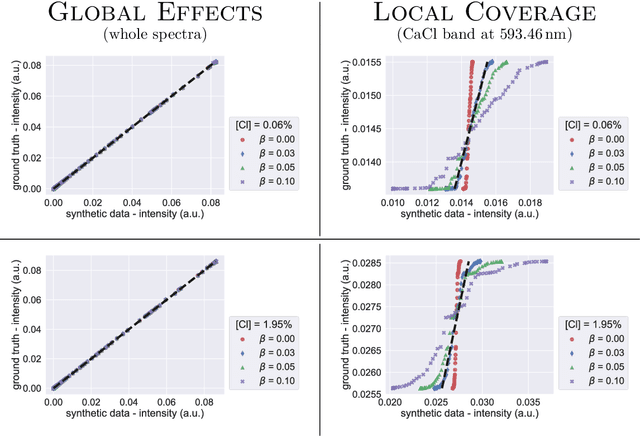
We consider quantitative analyses of spectral data using laser-induced breakdown spectroscopy. We address the small size of training data available, and the validation of the predictions during inference on unknown data. For the purpose, we build robust calibration models using deep convolutional multitask learning architectures to predict the concentration of the analyte, alongside additional spectral information as auxiliary outputs. These secondary predictions can be used to validate the trustworthiness of the model by taking advantage of the mutual dependencies of the parameters of the multitask neural networks. Due to the experimental lack of training samples, we introduce a simulation-based data augmentation process to synthesise an arbitrary number of spectra, statistically representative of the experimental data. Given the nature of the deep learning model, no dimensionality reduction or data selection processes are required. The procedure is an end-to-end pipeline including the process of synthetic data augmentation, the construction of a suitable robust, homoscedastic, deep learning model, and the validation of its predictions. In the article, we compare the performance of the multitask model with traditional univariate and multivariate analyses, to highlight the separate contributions of each element introduced in the process.