 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Little Confidence Goes a Long Way
Aug 20, 2024We introduce a group of related methods for binary classification tasks using probes of the hidden state activations in large language models (LLMs). Performance is on par with the largest and most advanced LLMs currently available, but requiring orders of magnitude fewer computational resources and not requiring labeled data. This approach involves translating class labels into a semantically rich description, spontaneous symmetry breaking of multilayer perceptron probes for unsupervised learning and inference, training probes to generate confidence scores (prior probabilities) from hidden state activations subject to known constraints via entropy maximization, and selecting the most confident probe model from an ensemble for prediction. These techniques are evaluated on four datasets using five base LLMs.
Transformer Based Language Models for Similar Text Retrieval and Ranking
May 21, 2020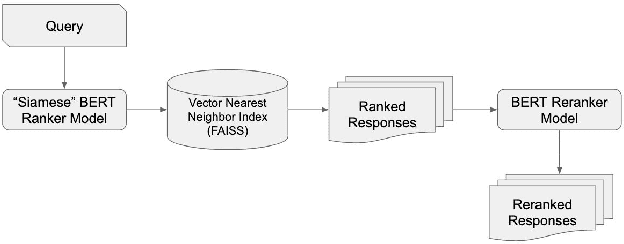
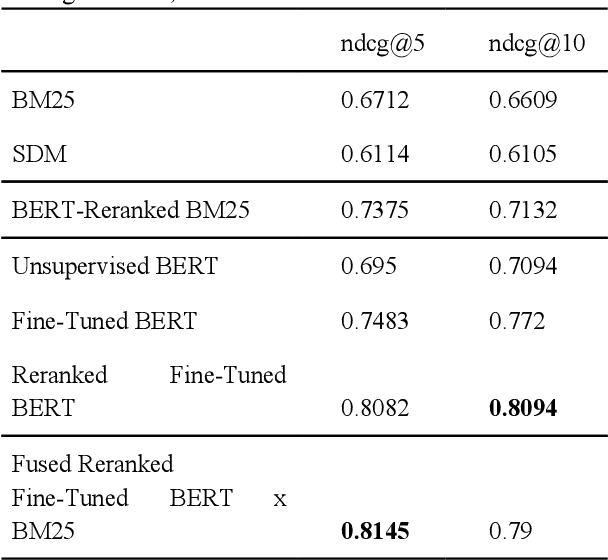
Most approaches for similar text retrieval and ranking with long natural language queries rely at some level on queries and responses having words in common with each other. Recent applications of transformer-based neural language models to text retrieval and ranking problems have been very promising, but still involve a two-step process in which result candidates are first obtained through bag-of-words-based approaches, and then reranked by a neural transformer. In this paper, we introduce novel approaches for effectively applying neural transformer models to similar text retrieval and ranking without an initial bag-of-words-based step. By eliminating the bag-of-words-based step, our approach is able to accurately retrieve and rank results even when they have no non-stopwords in common with the query. We accomplish this by using bidirectional encoder representations from transformers (BERT) to create vectorized representations of sentence-length texts, along with a vector nearest neighbor search index. We demonstrate both supervised and unsupervised means of using BERT to accomplish this task.