 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAU-Harness: An Open-Source Toolkit for Holistic Evaluation of Audio LLMs
Sep 11, 2025Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities. We introduce AU-Harness, an efficient and comprehensive evaluation framework for LALMs. Our system achieves a speedup of up to 127% over existing toolkits through optimized batch processing and parallel execution, enabling large-scale evaluations previously impractical. We provide standardized prompting protocols and flexible configurations for fair model comparison across diverse scenarios. Additionally, we introduce two new evaluation categories: LLM-Adaptive Diarization for temporal audio understanding and Spoken Language Reasoning for complex audio-based cognitive tasks. Through evaluation across 380+ tasks, we reveal significant gaps in current LALMs, particularly in temporal understanding and complex spoken language reasoning tasks. Our findings also highlight a lack of standardization in instruction modality existent across audio benchmarks, which can lead up performance differences up to 9.5 absolute points on the challenging complex instruction following downstream tasks. AU-Harness provides both practical evaluation tools and insights into model limitations, advancing systematic LALM development.
LALM-Eval: An Open-Source Toolkit for Holistic Evaluation of Large Audio Language Models
Sep 09, 2025Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities. We introduce LALM-Eval, an efficient and comprehensive evaluation framework for LALMs. Our system achieves a speedup of up to 127% over existing toolkits through optimized batch processing and parallel execution, enabling large-scale evaluations previously impractical. We provide standardized prompting protocols and flexible configurations for fair model comparison across diverse scenarios. Additionally, we introduce two new evaluation categories: LLM-Adaptive Diarization for temporal audio understanding and Spoken Language Reasoning for complex audio-based cognitive tasks. Through evaluation across 380+ tasks, we reveal significant gaps in current LALMs, particularly in temporal understanding and complex spoken language reasoning tasks. Our findings also highlight a lack of standardization in instruction modality existent across audio benchmarks, which can lead up performance differences up to 9.5 absolute points on the challenging complex instruction following downstream tasks. LALM-Eval provides both practical evaluation tools and insights into model limitations, advancing systematic LALM development.
A Federated Approach for Hate Speech Detection
Feb 18, 2023



Hate speech detection has been the subject of high research attention, due to the scale of content created on social media. In spite of the attention and the sensitive nature of the task, privacy preservation in hate speech detection has remained under-studied. The majority of research has focused on centralised machine learning infrastructures which risk leaking data. In this paper, we show that using federated machine learning can help address privacy the concerns that are inherent to hate speech detection while obtaining up to 6.81% improvement in terms of F1-score.
A Federated Approach to Predicting Emojis in Hindi Tweets
Nov 11, 2022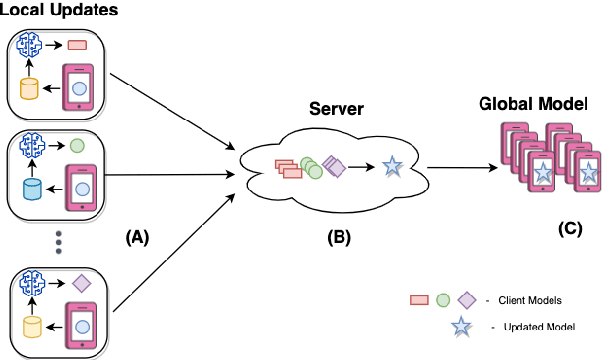
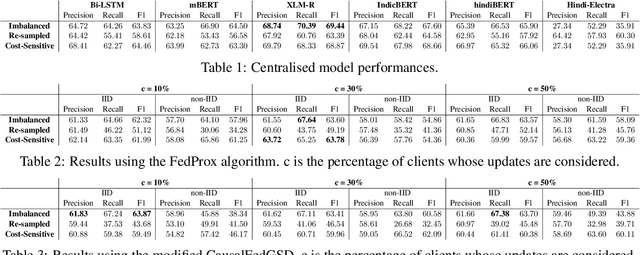
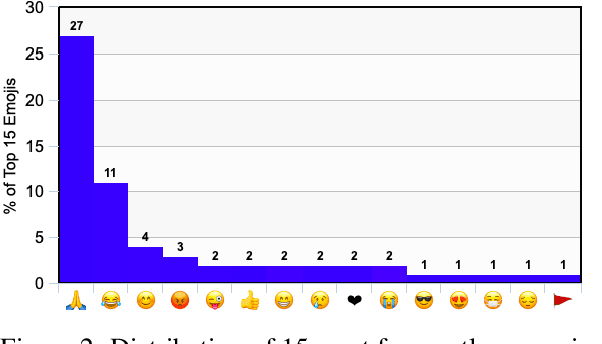
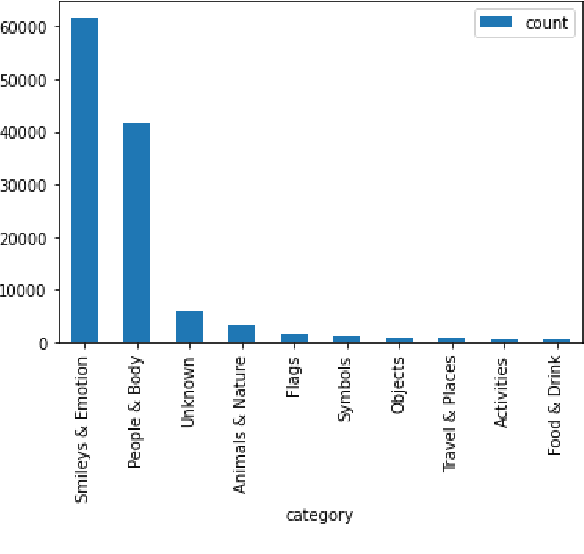
The use of emojis affords a visual modality to, often private, textual communication. The task of predicting emojis however provides a challenge for machine learning as emoji use tends to cluster into the frequently used and the rarely used emojis. Much of the machine learning research on emoji use has focused on high resource languages and has conceptualised the task of predicting emojis around traditional server-side machine learning approaches. However, traditional machine learning approaches for private communication can introduce privacy concerns, as these approaches require all data to be transmitted to a central storage. In this paper, we seek to address the dual concerns of emphasising high resource languages for emoji prediction and risking the privacy of people's data. We introduce a new dataset of $118$k tweets (augmented from $25$k unique tweets) for emoji prediction in Hindi, and propose a modification to the federated learning algorithm, CausalFedGSD, which aims to strike a balance between model performance and user privacy. We show that our approach obtains comparative scores with more complex centralised models while reducing the amount of data required to optimise the models and minimising risks to user privacy.