Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHysteresis-Based RL: Robustifying Reinforcement Learning-based Control Policies via Hybrid Control
Apr 01, 2022
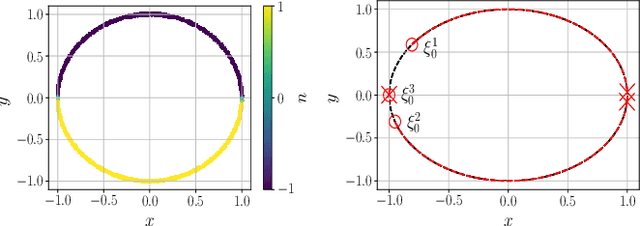
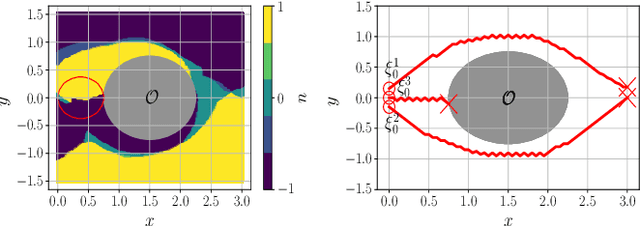

Reinforcement learning (RL) is a promising approach for deriving control policies for complex systems. As we show in two control problems, the derived policies from using the Proximal Policy Optimization (PPO) and Deep Q-Network (DQN) algorithms may lack robustness guarantees. Motivated by these issues, we propose a new hybrid algorithm, which we call Hysteresis-Based RL (HyRL), augmenting an existing RL algorithm with hysteresis switching and two stages of learning. We illustrate its properties in two examples for which PPO and DQN fail.
* This paper has been accepted for publication at the 2022 American
Control Conference (ACC)
Via