 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Class-conditional Autoencoders
Apr 09, 2015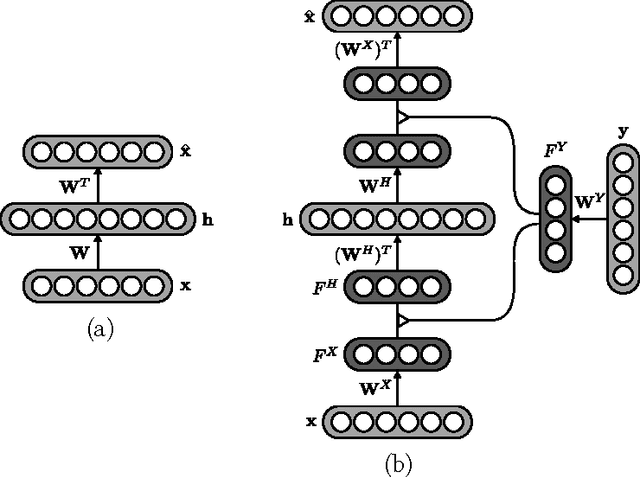


Recent work by Bengio et al. (2013) proposes a sampling procedure for denoising autoencoders which involves learning the transition operator of a Markov chain. The transition operator is typically unimodal, which limits its capacity to model complex data. In order to perform efficient sampling from conditional distributions, we extend this work, both theoretically and algorithmically, to gated autoencoders (Memisevic, 2013), The proposed model is able to generate convincing class-conditional samples when trained on both the MNIST and TFD datasets.
Neural Network Regularization via Robust Weight Factorization
Jan 05, 2015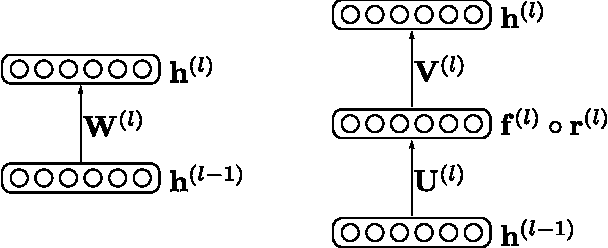
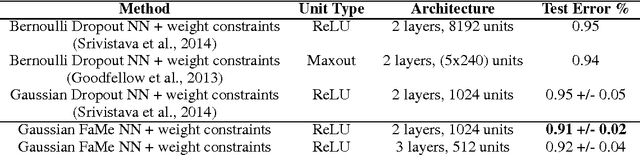

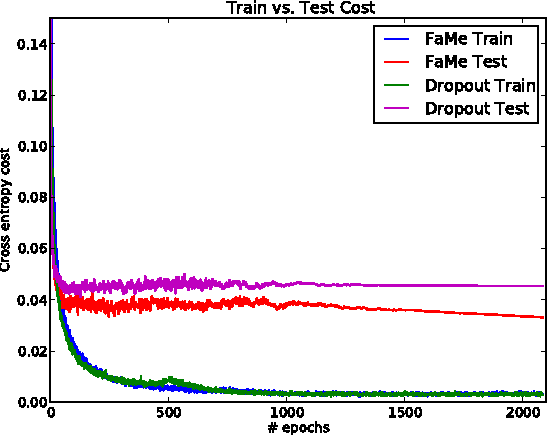
Regularization is essential when training large neural networks. As deep neural networks can be mathematically interpreted as universal function approximators, they are effective at memorizing sampling noise in the training data. This results in poor generalization to unseen data. Therefore, it is no surprise that a new regularization technique, Dropout, was partially responsible for the now-ubiquitous winning entry to ImageNet 2012 by the University of Toronto. Currently, Dropout (and related methods such as DropConnect) are the most effective means of regularizing large neural networks. These amount to efficiently visiting a large number of related models at training time, while aggregating them to a single predictor at test time. The proposed FaMe model aims to apply a similar strategy, yet learns a factorization of each weight matrix such that the factors are robust to noise.