 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-Weight Diffusion Multiplier and Uncertainty Quantification for Fourier Neural Operators
Aug 01, 2025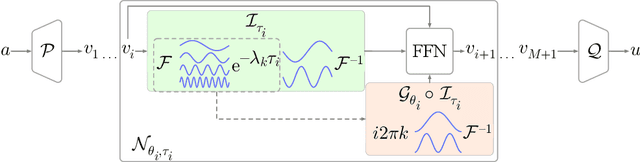
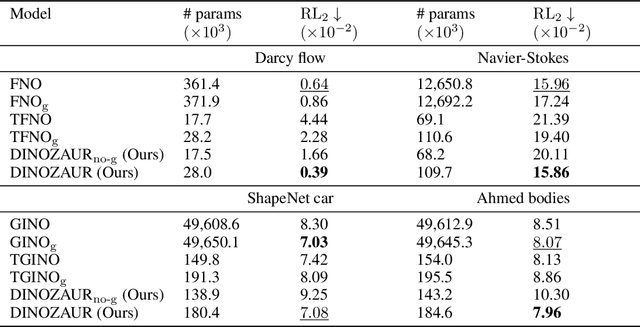
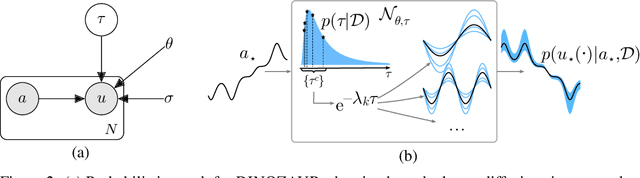
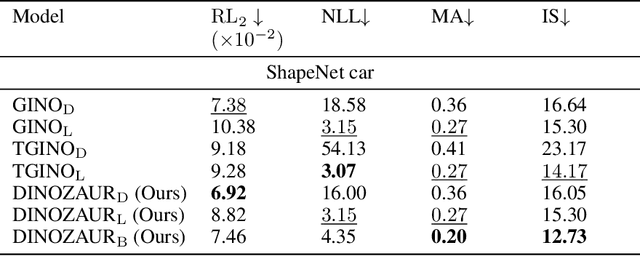
Operator learning is a powerful paradigm for solving partial differential equations, with Fourier Neural Operators serving as a widely adopted foundation. However, FNOs face significant scalability challenges due to overparameterization and offer no native uncertainty quantification -- a key requirement for reliable scientific and engineering applications. Instead, neural operators rely on post hoc UQ methods that ignore geometric inductive biases. In this work, we introduce DINOZAUR: a diffusion-based neural operator parametrization with uncertainty quantification. Inspired by the structure of the heat kernel, DINOZAUR replaces the dense tensor multiplier in FNOs with a dimensionality-independent diffusion multiplier that has a single learnable time parameter per channel, drastically reducing parameter count and memory footprint without compromising predictive performance. By defining priors over those time parameters, we cast DINOZAUR as a Bayesian neural operator to yield spatially correlated outputs and calibrated uncertainty estimates. Our method achieves competitive or superior performance across several PDE benchmarks while providing efficient uncertainty quantification.
A Fisher-Rao gradient flow for entropy-regularised Markov decision processes in Polish spaces
Oct 04, 2023We study the global convergence of a Fisher-Rao policy gradient flow for infinite-horizon entropy-regularised Markov decision processes with Polish state and action space. The flow is a continuous-time analogue of a policy mirror descent method. We establish the global well-posedness of the gradient flow and demonstrate its exponential convergence to the optimal policy. Moreover, we prove the flow is stable with respect to gradient evaluation, offering insights into the performance of a natural policy gradient flow with log-linear policy parameterisation. To overcome challenges stemming from the lack of the convexity of the objective function and the discontinuity arising from the entropy regulariser, we leverage the performance difference lemma and the duality relationship between the gradient and mirror descent flows.
Convergence of policy gradient for entropy regularized MDPs with neural network approximation in the mean-field regime
Jan 18, 2022We study the global convergence of policy gradient for infinite-horizon, continuous state and action space, entropy-regularized Markov decision processes (MDPs). We consider a softmax policy with (one-hidden layer) neural network approximation in a mean-field regime. Additional entropic regularization in the associated mean-field probability measure is added, and the corresponding gradient flow is studied in the 2-Wasserstein metric. We show that the objective function is increasing along the gradient flow. Further, we prove that if the regularization in terms of the mean-field measure is sufficient, the gradient flow converges exponentially fast to the unique stationary solution, which is the unique maximizer of the regularized MDP objective. Lastly, we study the sensitivity of the value function along the gradient flow with respect to regularization parameters and the initial condition. Our results rely on the careful analysis of non-linear Fokker--Planck--Kolmogorov equation and extend the pioneering work of Mei et al. 2020 and Agarwal et al. 2020, which quantify the global convergence rate of policy gradient for entropy-regularized MDPs in the tabular setting.