 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fisher-Rao gradient flow for entropy-regularised Markov decision processes in Polish spaces
Oct 04, 2023We study the global convergence of a Fisher-Rao policy gradient flow for infinite-horizon entropy-regularised Markov decision processes with Polish state and action space. The flow is a continuous-time analogue of a policy mirror descent method. We establish the global well-posedness of the gradient flow and demonstrate its exponential convergence to the optimal policy. Moreover, we prove the flow is stable with respect to gradient evaluation, offering insights into the performance of a natural policy gradient flow with log-linear policy parameterisation. To overcome challenges stemming from the lack of the convexity of the objective function and the discontinuity arising from the entropy regulariser, we leverage the performance difference lemma and the duality relationship between the gradient and mirror descent flows.
Mean-Field Langevin Dynamics and Energy Landscape of Neural Networks
May 19, 2019
We present a probabilistic analysis of the long-time behaviour of the nonlocal, diffusive equations with a gradient flow structure in 2-Wasserstein metric, namely, the Mean-Field Langevin Dynamics (MFLD). Our work is motivated by a desire to provide a theoretical underpinning for the convergence of stochastic gradient type algorithms widely used for non-convex learning tasks such as training of deep neural networks. The key insight is that the certain class of the finite dimensional non-convex problems becomes convex when lifted to infinite dimensional space of measures. We leverage this observation and show that the corresponding energy functional defined on the space of probability measures has a unique minimiser which can be characterised by a first order condition using the notion of linear functional derivative. Next, we show that the flow of marginal laws induced by the MFLD converges to the stationary distribution which is exactly the minimiser of the energy functional. We show that this convergence is exponential under conditions that are satisfied for highly regularised learning tasks. At the heart of our analysis is a pathwise perspective on Otto calculus used in gradient flow literature which is of independent interest. Our proof of convergence to stationary probability measure is novel and it relies on a generalisation of LaSalle's invariance principle. Importantly we do not assume that interaction potential of MFLD is of convolution type nor that has any particular symmetric structure. This is critical for applications. Finally, we show that the error between finite dimensional optimisation problem and its infinite dimensional limit is of order one over the number of parameters.
Martingale Functional Control variates via Deep Learning
Oct 11, 2018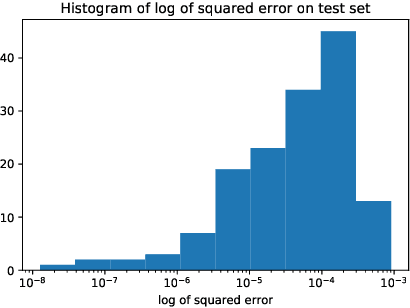


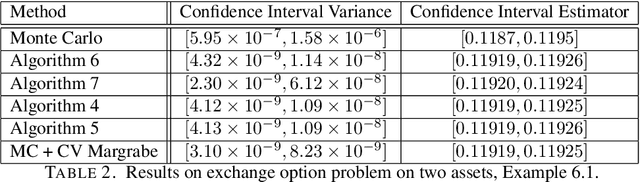
We propose black-box-type control variate for Monte Carlo simulations by leveraging the Martingale Representation Theorem and artificial neural networks. We developed several learning algorithms for finding martingale control variate functionals both for the Markovian and non-Markovian setting. The proposed algorithms guarantee convergence to the true solution independently of the quality of the deep learning approximation of the control variate functional. We believe that this is important as the current theory of deep learning functions approximations lacks theoretical foundation. However the quality of the deep learning functional approximation determines the level of benefit of the control variate. The methods are empirically shown to work for high-dimensional problems. We provide diagnostics that shed light on appropriate network architectures.