 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Parallel Training for Transformers
Jan 13, 2026We present a new training methodology for transformers using a multilevel, layer-parallel approach. Through a neural ODE formulation of transformers, our application of a multilevel parallel-in-time algorithm for the forward and backpropagation phases of training achieves parallel acceleration over the layer dimension. This dramatically enhances parallel scalability as the network depth increases, which is particularly useful for increasingly large foundational models. However, achieving this introduces errors that cause systematic bias in the gradients, which in turn reduces convergence when closer to the minima. We develop an algorithm to detect this critical transition and either switch to serial training or systematically increase the accuracy of layer-parallel training. Results, including BERT, GPT2, ViT, and machine translation architectures, demonstrate parallel-acceleration as well as accuracy commensurate with serial pre-training while fine-tuning is unaffected.
Multilevel Initialization for Layer-Parallel Deep Neural Network Training
Dec 19, 2019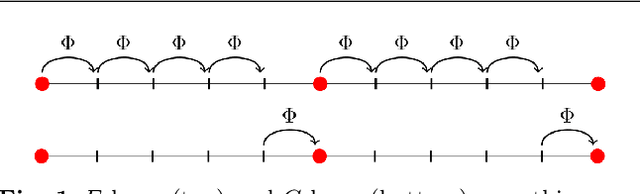
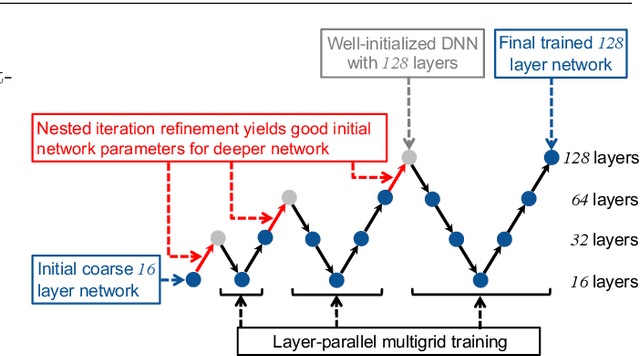
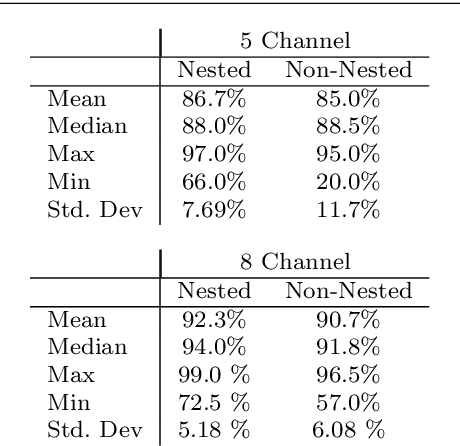
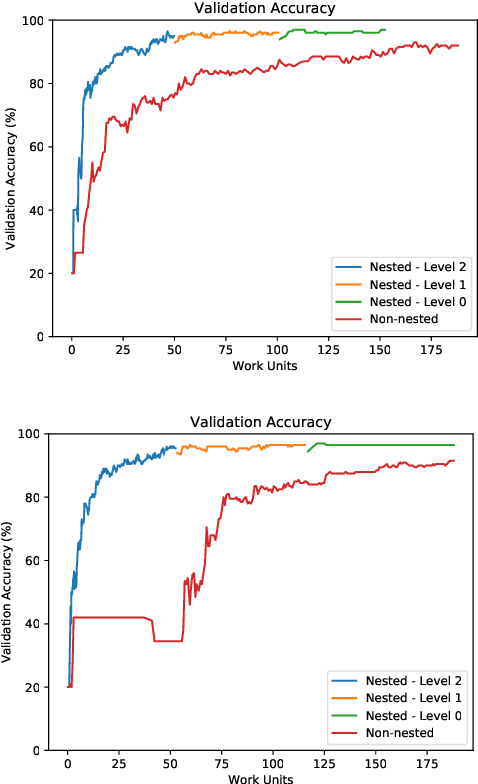
This paper investigates multilevel initialization strategies for training very deep neural networks with a layer-parallel multigrid solver. The scheme is based on the continuous interpretation of the training problem as a problem of optimal control, in which neural networks are represented as discretizations of time-dependent ordinary differential equations. A key goal is to develop a method able to intelligently initialize the network parameters for the very deep networks enabled by scalable layer-parallel training. To do this, we apply a refinement strategy across the time domain, that is equivalent to refining in the layer dimension. The resulting refinements create deep networks, with good initializations for the network parameters coming from the coarser trained networks. We investigate the effectiveness of such multilevel "nested iteration" strategies for network training, showing supporting numerical evidence of reduced run time for equivalent accuracy. In addition, we study whether the initialization strategies provide a regularizing effect on the overall training process and reduce sensitivity to hyperparameters and randomness in initial network parameters.
Parallelizing Over Artificial Neural Network Training Runs with Multigrid
Oct 01, 2017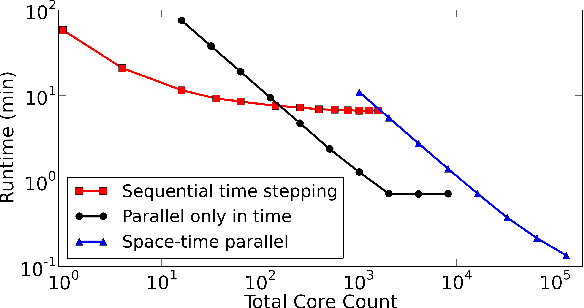



Artificial neural networks are a popular and effective machine learning technique. Great progress has been made parallelizing the expensive training phase of an individual network, leading to highly specialized pieces of hardware, many based on GPU-type architectures, and more concurrent algorithms such as synthetic gradients. However, the training phase continues to be a bottleneck, where the training data must be processed serially over thousands of individual training runs. This work considers a multigrid reduction in time (MGRIT) algorithm that is able to parallelize over the thousands of training runs and converge to the exact same solution as traditional training would provide. MGRIT was originally developed to provide parallelism for time evolution problems that serially step through a finite number of time-steps. This work recasts the training of a neural network similarly, treating neural network training as an evolution equation that evolves the network weights from one step to the next. Thus, this work concerns distributed computing approaches for neural networks, but is distinct from other approaches which seek to parallelize only over individual training runs. The work concludes with supporting numerical results for two model problems.